







 本文介绍Python在文本和文件处理方面的强大功能,包括读取和写入各种格式的数据文件,处理缺失值,以及逐块读取大文件的技术。同时,文章还讨论了如何使用pandas库进行数据转换和聚合。
本文介绍Python在文本和文件处理方面的强大功能,包括读取和写入各种格式的数据文件,处理缺失值,以及逐块读取大文件的技术。同时,文章还讨论了如何使用pandas库进行数据转换和聚合。
输入输出通常可以划分为几个大类:读取文本文件和其他更高效的磁盘存储格式,加载数据库中的数据,利用Web API操作网络资源。
因为其简单的文件交互语法、直观的数据结构,以及诸如元组打包解包之类的便利功能,Python在文本和文件处理方面已经成为一门招人喜欢的语言。
读写文本格式的数据
本文将大致介绍一下这些函数在将文本数据转换为DataFrame时所用到的一些技术。这些函数的选项可以划分为以下几个大类:
- 索引:将一个或多个列当做返回的DataFrame处理,以及是否从文件、用户获取列名。
- 类型推断和数据转换:包括用户定义值的转换、缺失值标记列表等。
- 日期解析:包括组合功能,比如将分散在多个列中的日期时间信息组合成结果中的单个列。
- 迭代:支持对大文件进行逐块迭代。
- 不规整数据问题:跳过一些行、页脚、注释或其他一些不重要的东西(比如由成千上万个逗号隔开的数值数据)。
比如,如下的文本:

由于该文件以逗号分隔,所以我们可以使用read_csv将其读入一个DataFrame:
import pandas as pd
df=pd.read_csv('ex1.csv')
print(df)
#output
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
我们也可以用read_table,只不过需要指定分隔符而已:
print(pd.read_table('ex1.csv',sep=','))
#output
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
当然也可以自己分配列名,或者默认列名:
import pandas as pd
df=pd.read_csv('ex2.csv',header=None)
print(df)
df2=pd.read_table('ex2.csv',sep=',',
names=['a', 'b', 'c', 'd', 'message'])
print(df2)
#output
0 1 2 3 4
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
假设你希望将message列做成DataFrame的索引。你可以明确表示要将该列放到索引4的位置上,也可以通过index_col参数指定"message":
df2=pd.read_table('ex2.csv',sep=',',
names=['a', 'b', 'c', 'd', 'message'],
index_col='message')
print(df2)
#output
a b c d
message
hello 1 2 3 4
world 5 6 7 8
foo 9 10 11 12
如果希望将多个列做成一个层次化索引,只需传入由列编号或列名组成的列表即可:
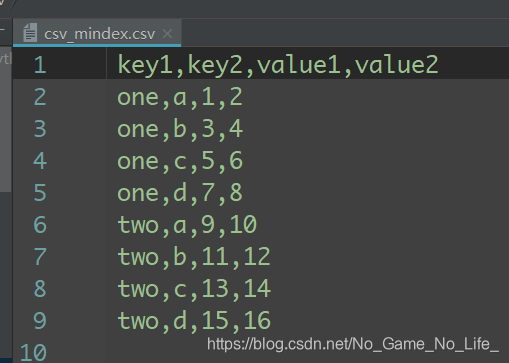
df=pd.read_csv('csv_mindex.csv',index_col=['key1','key2'])
print(df)
#output
value1 value2
key1 key2
one a 1 2
b 3 4
c 5 6
d 7 8
two a 9 10
b 11 12
c 13 14
d 15 16
有些表格可能不是用固定的分隔符去分隔字段的(比如空白符或其他模式)。对于这种情况,可以编写一个正则表达式来作为read_table的分隔符。看看下面这个文本文件:
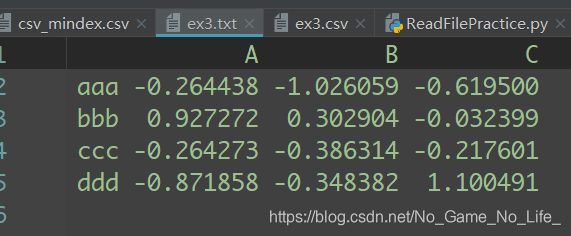
该文件各个字段由数量不定的空白符分隔,虽然你可以对其做一些手工调整,但这个情况还是处理比较好。本例的这个情况可以用正则表达式\s+表示,于是我们就有了:
In [859]: result = pd.read_table('ch06/ex3.txt', sep='\s+')
In [860]: result
Out[860]:
A B C
aaa -0.264438 -1.026059 -0.619500
bbb 0.927272 0.302904 -0.032399
ccc -0.264273 -0.386314 -0.217601
ddd -0.871858 -0.348382 1.100491
许多参数可以帮助你处理各种各样的异形文件格式。
比如跳过无用行。
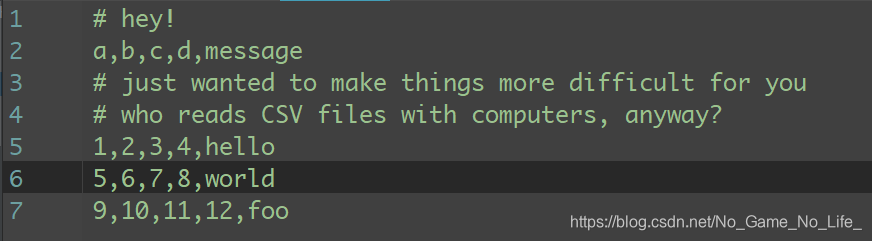
比如说,你可以用skiprows跳过文件的第一行、第三行和第四行:
In [862]: pd.read_csv('ch06/ex4.csv', skiprows=[0, 2, 3])
Out[862]:
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
缺失值处理是文件解析任务中的一个重要组成部分。缺失数据经常是要么没有(空字符串),要么用某个标记值表示。默认情况下,pandas会用一组经常出现的标记值进行识别,如NA、-1.#IND以及NULL等:
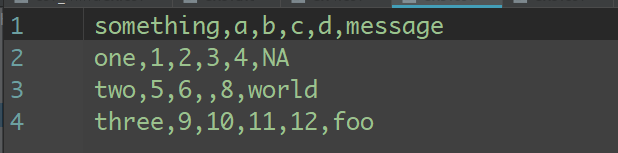
In [864]: result = pd.read_csv('ch06/ex5.csv')
In [865]: result
Out[865]:
something a b c d message
0 one 1 2 3 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11 12 foo
In [866]: pd.isnull(result)
Out[866]:
something a b c d message
0 False False False False False True
1 False False False True False False
2 False False False False False False
na_values可以接受一组用于表示缺失值的字符串:
In [867]: result = pd.read_csv('ch06/ex5.csv', na_values=['NULL'])
In [868]: result
Out[868]:
something a b c d message
0 one 1 2 3 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11 12 foo
可以用一个字典为各列指定不同的NA标记值:
In [869]: sentinels = {'message': ['foo', 'NA'], 'something': ['two']}
In [870]: pd.read_csv('ch06/ex5.csv', na_values=sentinels)
Out[870]:
something a b c d message
0 one 1 2 3 4 NaN
1 NaN 5 6 NaN 8 world
2 three 9 10 11 12 NaN
- 逐块读取文本文件
在处理很大的文件时,或找出大文件中的参数集以便于后续处理时,你可能只想读取文件的一小部分或逐块对文件进行迭代。
如果只想读取几行(避免读取整个文件),通过nrows进行指定即可:
In [873]: pd.read_csv('ch06/ex6.csv', nrows=5)
Out[873]:
one two three four key
0 0.467976 -0.038649 -0.295344 -1.824726 L
1 -0.358893 1.404453 0.704965 -0.200638 B
2 -0.501840 0.659254 -0.421691 -0.057688 G
3 0.204886 1.074134 1.388361 -0.982404 R
4 0.354628 -0.133116 0.283763 -0.837063 Q
要逐块读取文件,需要设置chunksize(行数):
In [874]: chunker = pd.read_csv('ch06/ex6.csv', chunksize=1000)
In [875]: chunker
Out[875]: <pandas.io.parsers.TextParser at 0x8398150>
read_csv所返回的这个TextParser对象使你可以根据chunksize对文件进行逐块迭代。比如说,我们可以迭代处理ex6.csv,将值计数聚合到"key"列中,如下所示:
from pandas import Series
import pandas as pd
chunker=pd.read_csv('ex6.csv',chunksize=1000)
tot=Series([])
for piece in chunker:
tot=tot.add(piece['key'].value_counts(),fill_value=0)
tot=tot.sort_index(ascending=False)
print(tot[:10])
#output
Z 288.0
Y 314.0
X 364.0
W 305.0
V 328.0
U 326.0
T 304.0
S 308.0
R 318.0
Q 340.0
dtype: float64
这里piece就是每一个分片,piece[‘key’]就是每个分片上,key列。value_count()就是统计key上不同字母出现的数目。然后for循环加起来。
- 将数据写出到文本格式
数据也可以被输出为分隔符格式的文本。我们再来看看之前读过的一个CSV文件:
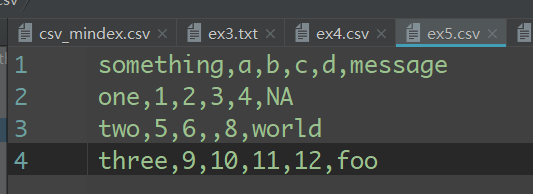
利用DataFrame的to_csv方法,我们可以将数据写到一个以逗号分隔的文件中:
import pandas as pd
data=pd.read_csv('ex5.csv')
data.to_csv('out.csv',sep='|',na_rep='NULL') #也可以不指定sep,默认为|
如果没有设置其他选项,则会写出行和列的标签。当然,它们也都可以被禁用:
In [884]: data.to_csv(sys.stdout, index=False, header=False)
one,1,2,3.0,4,
two,5,6,,8,world
three,9,10,11.0,12,foo
此外,你还可以只写出一部分的列,并以你指定的顺序排列:
In [885]: data.to_csv(sys.stdout, index=False, cols=['a', 'b', 'c'])
a,b,c
1,2,3.0
5,6,
9,10,11.0
Series也有一个to_csv方法。
- 手工处理分隔符格式
大部分存储在磁盘上的表格型数据都能用pandas.read_table进行加载。然而,有时还是需要做一些手工处理。由于接收到含有畸形行的文件而使read_table出毛病的情况并不少见。
这里暂时不介绍。
- JSON XML HTML
暂略
二进制数据格式
实现数据的二进制格式存储最简单的办法之一是使用Python内置的pickle序列化。为了使用方便,pandas对象都有一个用于将数据以pickle形式保存到磁盘上的save方法:
In [933]: frame = pd.read_csv('ch06/ex1.csv')
In [934]: frame
Out[934]:
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
In [935]: frame.save('ch06/frame_pickle')
In [936]: pd.load('ch06/frame_pickle')
Out[936]:
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
pickle仅建议用于短期存储格式。其原因是很难保证该格式永远是稳定的;今天pickle的对象可能无法被后续版本的库unpickle出来。
- 使用HDF5格式
暂略
- 读取Microsoft Excel文件
pandas的ExcelFile类支持读取存储在Excel 2003(或更高版本)中的表格型数据。由于ExcelFile用到了xlrd和openpyxl包,所以你先得安装它们才行。通过传入一个xls或xlsx文件的路径即可创建一个ExcelFile实例:
xls_file = pd.ExcelFile('data.xls')
#存放在某个工作表中的数据可以通过parse读取到DataFrame中:
table = xls_file.parse('Sheet1')
- 使用HTML和Web API
暂略
- 使用HTML和Web API
暂略
- 使用数据库
暂略
- 存取MongoDB中的数据
暂略


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









