






记录一下python的一些常用语法,避免忘记,占个坑:
一.列表,元组,字典,集合等数据类型的基础用法
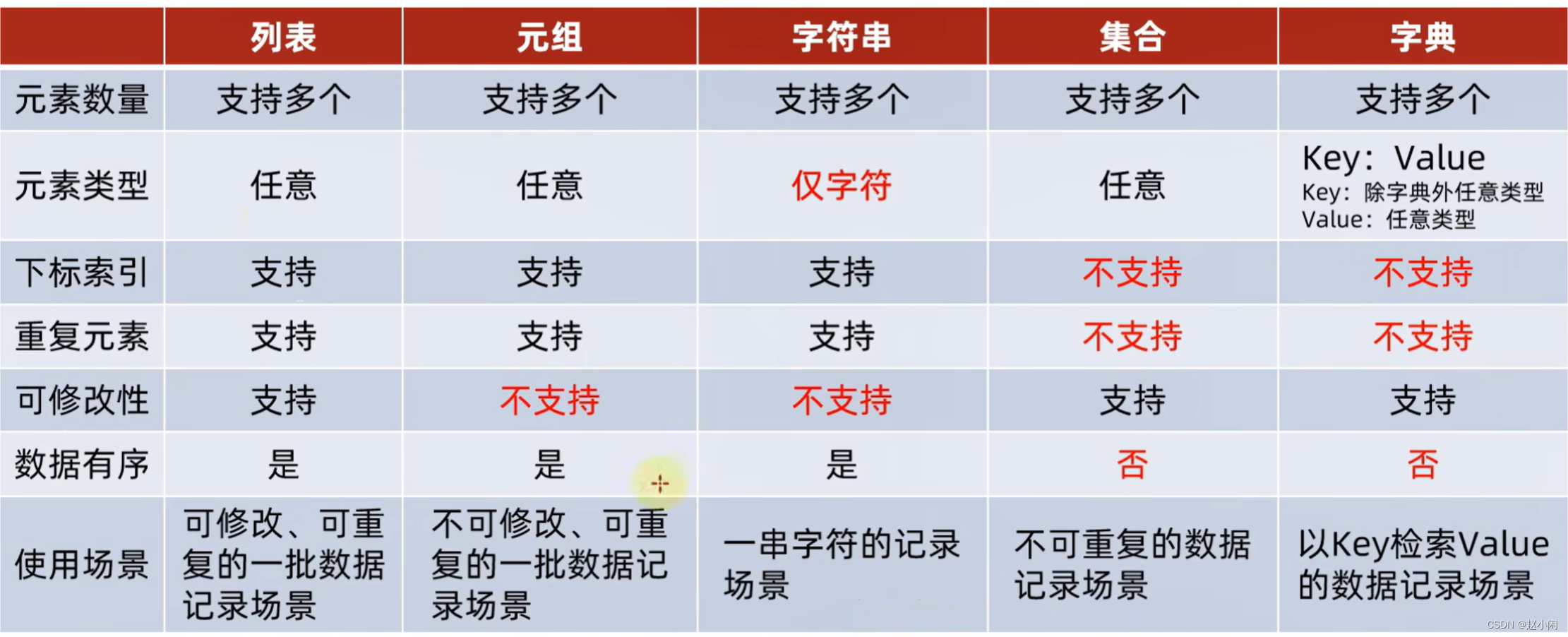
1.1 数据类型
(1)list() 列表
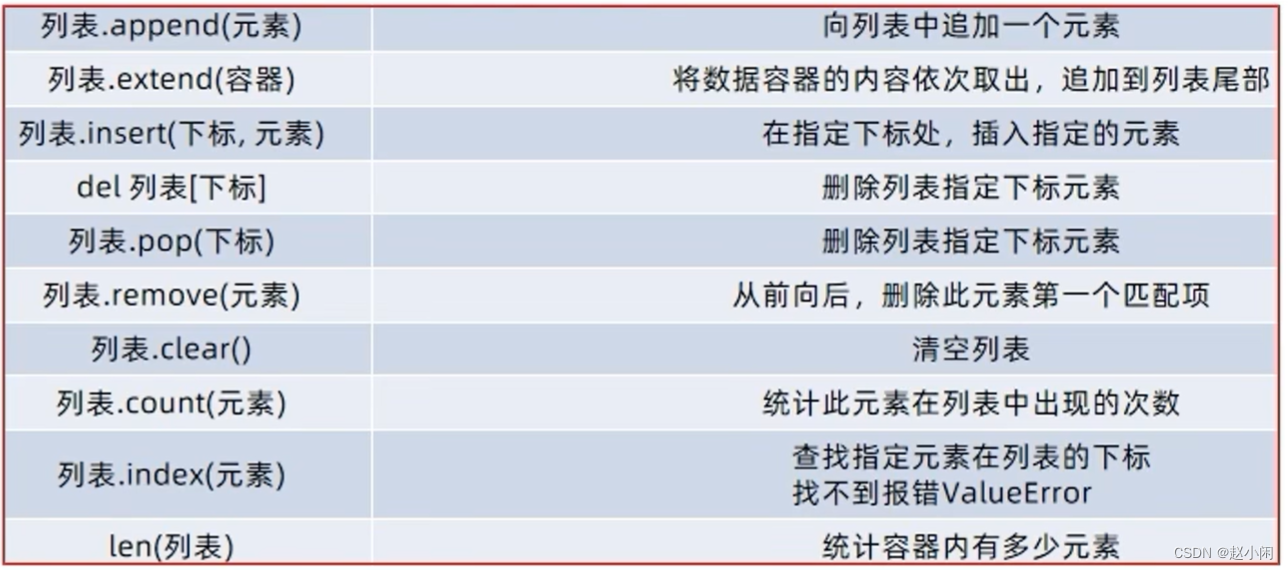
列表.insert(1, ‘d’) #按位插入。
列表.append #表尾追加。
(2)dict() 字典
可参考:Python的字典操作
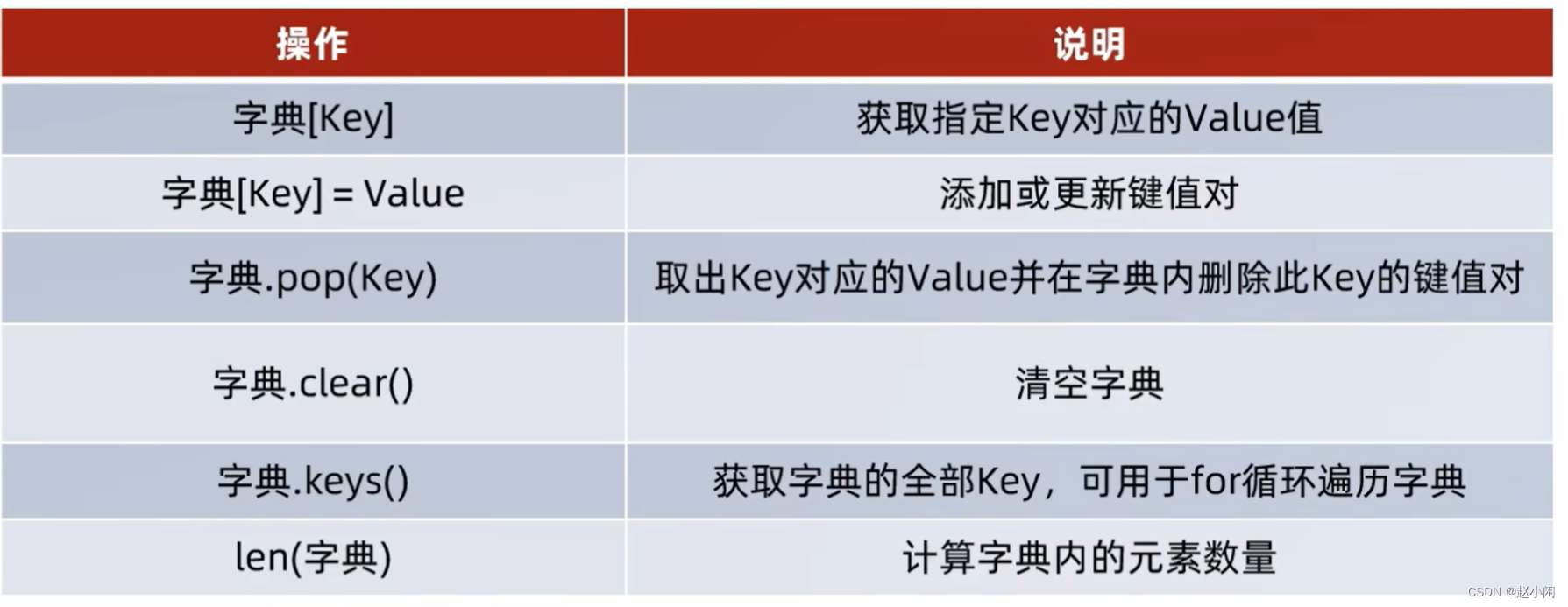
字典特点:

- keys()方法返回字典的所有键组成的一个视图对象,注意不是返回一个列表,该对象不支持下标的索引,如果需要可以用list函数转换为列表。
- 新增和更新语法一致,若key存在则更新,不存在则新增。
(3)set() 集合
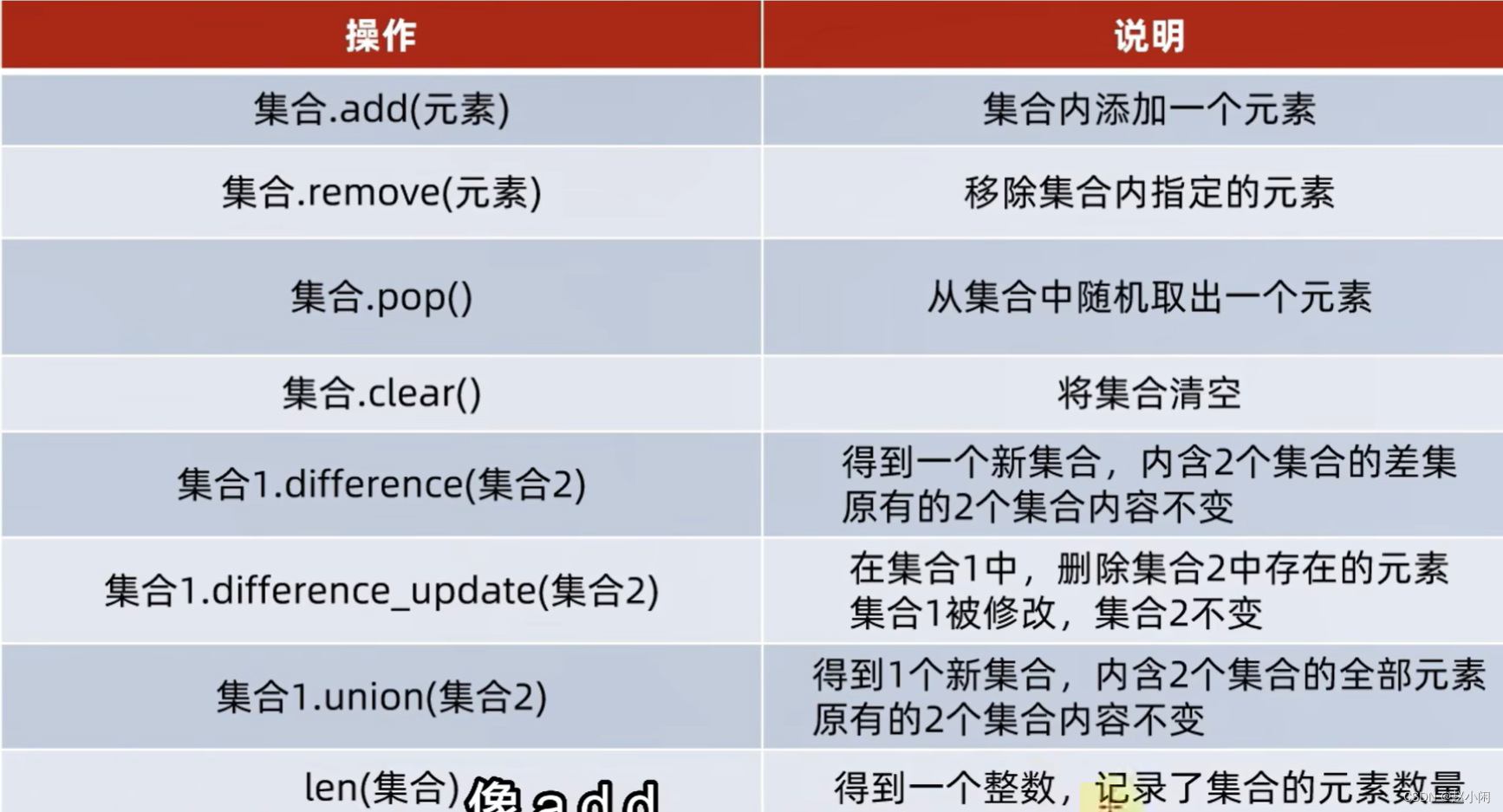
集合特点:(无序!!)

(4)tuple() 元组
元组特点:

元组操作:

(5)总结和通用操作
- 列表使用:[]
- 集合使用:{}
- 元组使用:()
- 字典使用:{key:value}
- 字符串使用:" "
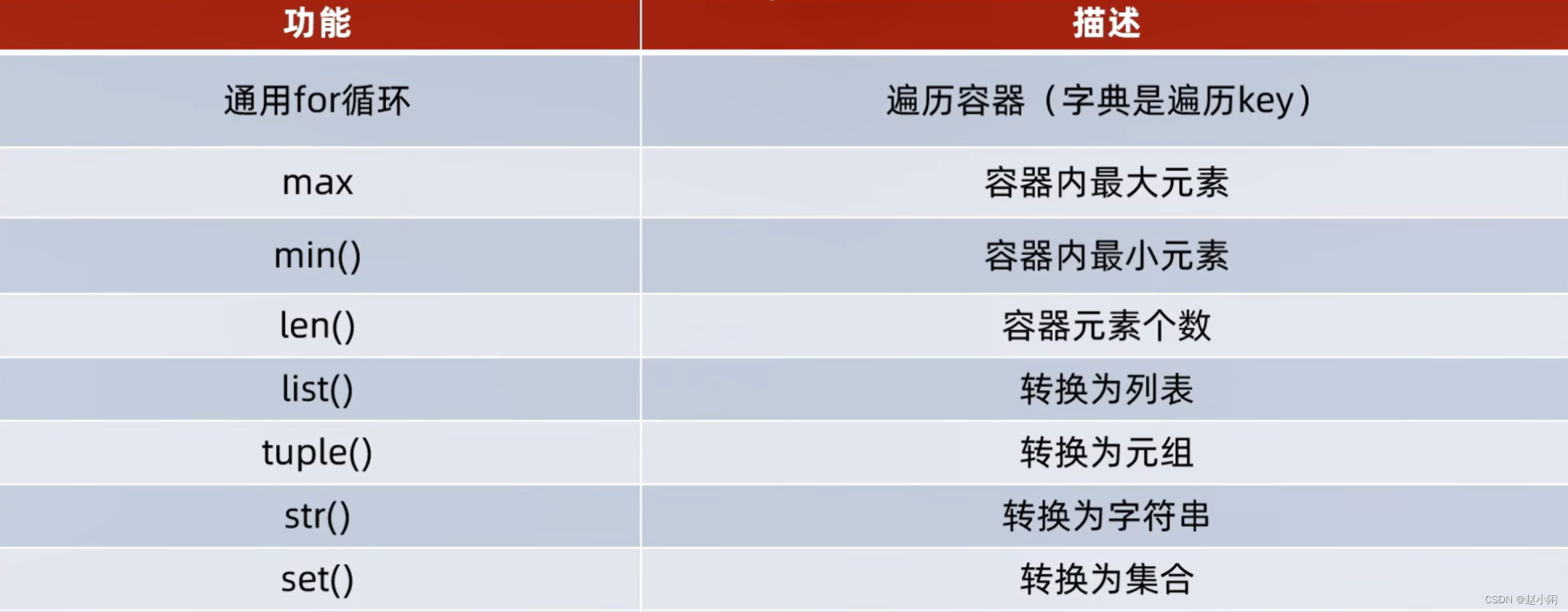

(6)数据容器之间的需要注意的转换操作
- 字符串转列表/元组会将字符串中每一个元素取出作为列表的每一个元素
- 字典转列表/元组/集合会将value抛弃,只剩下key
# 字符串转化
"how"---->["h","o","w"]
1.2一些基础操作
split()拆分
a.split(str, num)
split()是按指定的分隔符,把一个字符串分隔成指定数目的子字符串,然后把它们放入一个列表中,
str – 分隔符,默认为所有的空字符。包括逗号、空格、换行(\n)、制表符(\t)等。
max – 分割次数。规定要执行的拆分数。默认值为 -1,即“所有出现次数”
#例1:
a="I love China"
a.split() # 分隔符为空,分割次数默认
['I', 'love', 'China']
#例2:
b="I love China, and you, you"
b.split(", ") # 使用逗号和空格作为分隔符
['I love China', 'and you', 'you']
#例3:
c="I#love#China#andyou#you"
c.split("#") #使用#作为分隔符
['I', 'love', 'China', 'andyou', 'you']
#例4:
d="I#love#China#andyou#you"
d.split("#",1) # 将 max值为 1,将返回包含 2 个元素的列表
['I', 'love#China#andyou#you']
#例5:
e="with great power comes great responsibility. I love China and you you"
e.split(" ",15) #空格为分隔符
['with', 'great', 'power', 'comes', 'great', 'responsibility.', 'I', 'love', 'China', 'and', 'you', 'you']
replace()替换
str = "hello"
print(str.replace('h', 'H')) # Hello
print(str.replace('l', 'L')) # heLLo
print(str.replace('l', 'L', 1)) # heLlo
X.replace('/n', '').replace('/t','') #空格替换/n,/t
第一个参数是替换之前的值
第二个参数是替换之后的值
第三个是替换次数,不写默认全部替换
strip()移除字符串
strip方法用于移除字符串首尾指定的字符串;当没有参数时,默认为空格和换行符。
str = " 002200\n"
print(str.strip()) #结果为:“002200”
也可以指定字符串如:
str = "002200"
print(str.strip("0"))#结果为:“22”
strip函数还有“lstrip”和“rstrip”的形式
通过英文单词我们可知,“lstrip”是删除左边的指定字符串,“rstrip”是删除右边的指定字符串。注意:“lstrip”是只删除左边的指定字符串,而不会删除右边的指定字符串。同理,“rstrip”只删除右边的指定字符串,而不会删除左边的指定字符串。
str = "002233喔喔"
print(str.lstrip("0")) # 结果为:“2233喔喔”
str1 = "002233喔喔"
print(str1.rstrip("喔喔")) # 结果为:“002233”
二.关于文件操作
2.1文件打开与关闭、删除等
python 关于文件操作:读写,打开关闭
一般用open()和close()打开和关闭文件。
也可使用with open语法打开文件,会自动关闭文件,无需close()命令关闭
with open("test.txt","r") as f:
for line in f: # for循环会按行输出文件内容
print(line)
- ‘r’ 以「只读」模式打开文件,如果指定文件不存在,则会报错,默认情况下文件指针指向文件开头
- ‘w’ 以「只写」模式打开文件,如果文件不存在,则根据 filename 创建相应的文件,如果文件已存在,则会覆盖原文件
写入后可以f.flush() 文件刷新保存,close()带有flush()方法的功能

- ‘a’ 以「追加」模式打开文件,如果文件已存在,文件指针会指向文件尾部,将内容追加在原文件后面,如果文件不存在,则会新建文件且写入内容
可以使用“\n换行”
2.2读数据
#若存在文件test.txt内容为
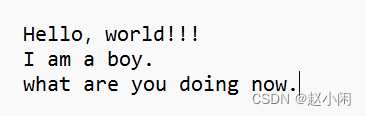
1. read()函数
使用read(num)可以从文件中读取数据,num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中的所有数据。
f = open("test.txt","r")
content = f.read(5)
f.close()
print(content) #Hello
2. readlines()和readline()函数
readlines()可以按照行的方式把整个文件中的内容进行一次性的读取,并且返回的是一个列表,其中每一行的数据为一个元素。
readline()一次读取一行
f = open("test.txt","r")
lines = f.readlines()
f.close()
print(lines) # ['Hello world!!!\n', 'I am a boy.\n', 'what are you doing now.']
#注意输出结果有“\n”回车换行符
f = open("test.txt","r")
line1 = f.readline()
f.close()
print(line1) # Hello world!!!
**注意:**读取文件后,若不关闭,默认会续接上次读取文件结尾处继续读取,如:
f = open("test.txt","r")
content = f.read(5)
line = f.readline()
lines = f.readlines()
print(content)
print(line)
print(lines)
输出结果为:
Hello
world!!!
#注意这里会有一个空行,因为读取的数据会带有一个换行符“\n”
['I am a boy.\n', 'what are you doing now.']


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









