









 文章介绍了回归分析中常用的模型评估指标,包括平均绝对误差(MAE)、均方误差(MSE)、均方根误差(RMSE)以及决定系数(R2)。这些指标用于衡量预测值与真实值之间的差距,帮助评估模型的预测性能。此外,还提到了如校准和预测相关系数等其他相关评价标准。
文章介绍了回归分析中常用的模型评估指标,包括平均绝对误差(MAE)、均方误差(MSE)、均方根误差(RMSE)以及决定系数(R2)。这些指标用于衡量预测值与真实值之间的差距,帮助评估模型的预测性能。此外,还提到了如校准和预测相关系数等其他相关评价标准。
目录
1. MAE(Mean Absolute Error:平均绝对误差)
2. MSE(Mean Square Error:均方误差)
3. RMSE(Root Mean Square Error:均方根误差)
4. RMSEC(Root Mean Square Error of Calibration:校准均方根误差)
5. RMSECV(Root Mean Square Error of Cross Validation:交叉校准均方根误差)
7. RMSEP(Root Mean Square Error of Prediction:预测均方根误差)
回归算法中常用的评价指标:MAE、MSE和RMSE
一、回归算法或模型评估指标
1. MAE(Mean Absolute Error:平均绝对误差)

其中,表示真实值,
表示预测值,m表示样本集的数量。
mean_absolute_error = np.sum(np.absolute(y_true - y_predict)) / len(y_true)
示例源码,MSE一行代码即可实现:
from sklearn.metrics import mean_absolute_error
import numpy as np
y_true = np.array([1, 2, 4, 8])
y_pred = np.array([2, 4, 6, 8])
mae = mean_absolute_error(y_true, y_pred)
print("平均绝对误差:", mae) # 1.252. MSE(Mean Square Error:均方误差)
真实值减预测值的平方和除以预测样本大小,使得其与测试样本大小无关。

mean_squared_error = np.sum((y_true-y_predict)**2) / len(y_predict)
示例源码,MSE一行代码即可实现:
from sklearn.metrics import mean_squared_error
import numpy as np
y_true = np.array([1, 2, 4, 8])
y_pred = np.array([2, 4, 6, 8])
mse = mean_squared_error(y_true, y_pred)
print("均方误差:", mse) # 2.253. RMSE(Root Mean Square Error:均方根误差)
RMSE = MSE均方误差 开根号

root_mean_squared_error = sqrt(mean_squared_error)
示例源码,RMSE一行代码即可实现:
from sklearn.metrics import mean_squared_error
import numpy as np
y_true = np.array([1, 2, 4, 8])
y_pred = np.array([2, 4, 6, 8])
rmse = np.sqrt(mean_squared_error(y_true, y_pred))
print("均方根误差:", rmse) # 1.54. RMSEC(Root Mean Square Error of Calibration:校准均方根误差)

其中,表示真实值,
表示预测值,n表示校准样本集的数量。
5. RMSECV(Root Mean Square Error of Cross Validation:交叉校准均方根误差)
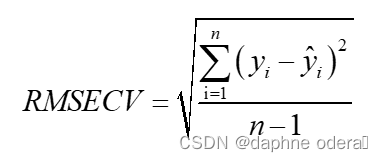
6. RRMSEC(相对校准均方根误差)
其中,表示校准集真实值的均值。
7. RMSEP(Root Mean Square Error of Prediction:预测均方根误差)
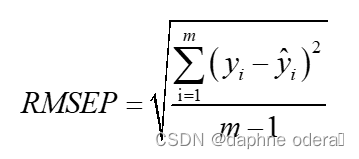
其中,m表示测试样本集的数量。注意此处是预测集,请和RMSEC计算校准集的误差有所区分。
8. RRMSEP(相对预测均方根误差)
其中,表示测试集真实值的均值。
9. Rc(校准相关系数)
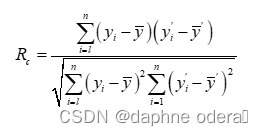
其中, 表示第 i 个样本真实值,
表示校准集中所有样本真实值的平均值,
表示第 i 个样本预测值,
表示校准集中所有样本预测值的平均值,n表示校准样本集的数量。
10. Rp(预测相关系数)
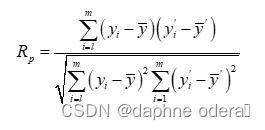
其中, 表示第 i 个样本真实值,
表示测试集中所有样本真实值的平均值,
表示第 i 个样本预测值,
表示测试集中所有样本预测值的平均值,m表示测试样本集的数量。
11. R Squared(R2:决定系数)
R平方也称为决定系数,用于确定数据与拟合回归线的接近程度。

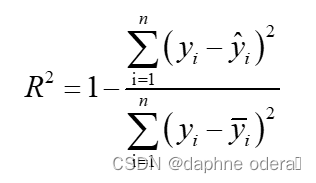
其中,n表示样本集的数量,代表数据集中所有样品实际值的平均值。
“决定系数”的正常取值范围为[0,1],越接近1,表明方程的变量对y的解释能力越强,这个模型对数据拟合的也较好
r_squared = 1 - mean_squared_error / np.var(y_true)
示例源码,R2一行代码即可实现:
from sklearn.metrics import r2_score
import numpy as np
y_true = np.array([1, 2, 4, 8])
y_pred = np.array([2, 4, 6, 8])
r2 = r2_score(y_true, y_pred)
print("决定系数:", round(r2, 3)) # 0.68712. RPD(Ratio of standard deviation of the validation set to standard error of prediction:验证集标准偏差与预测集标准偏差的比值 )
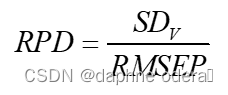
其中,SD 代表验证集所有样本某个待测指标的标准偏差。
二、 图解及汇总
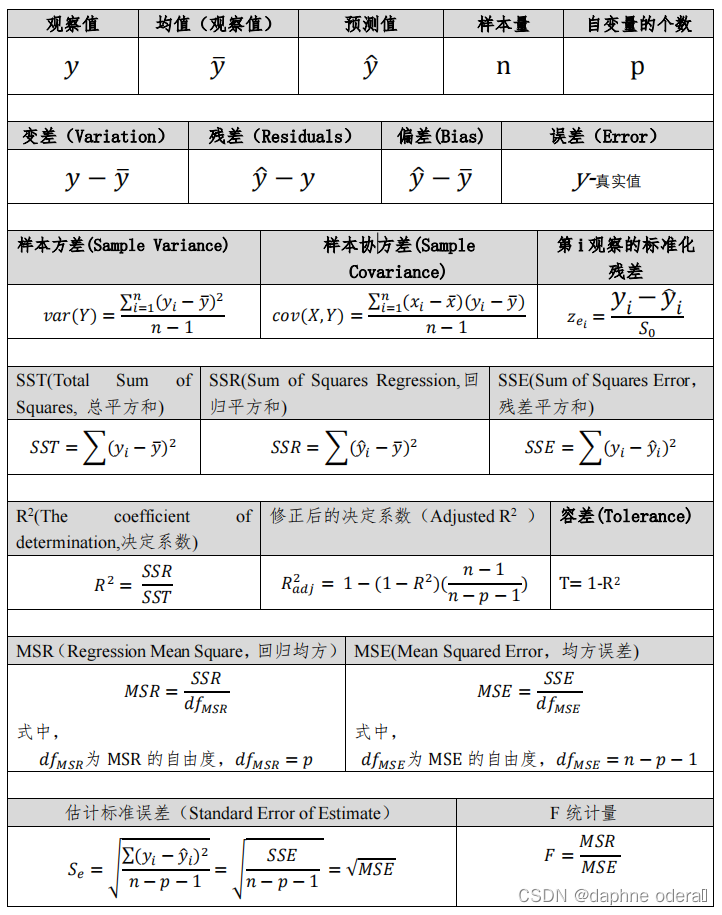
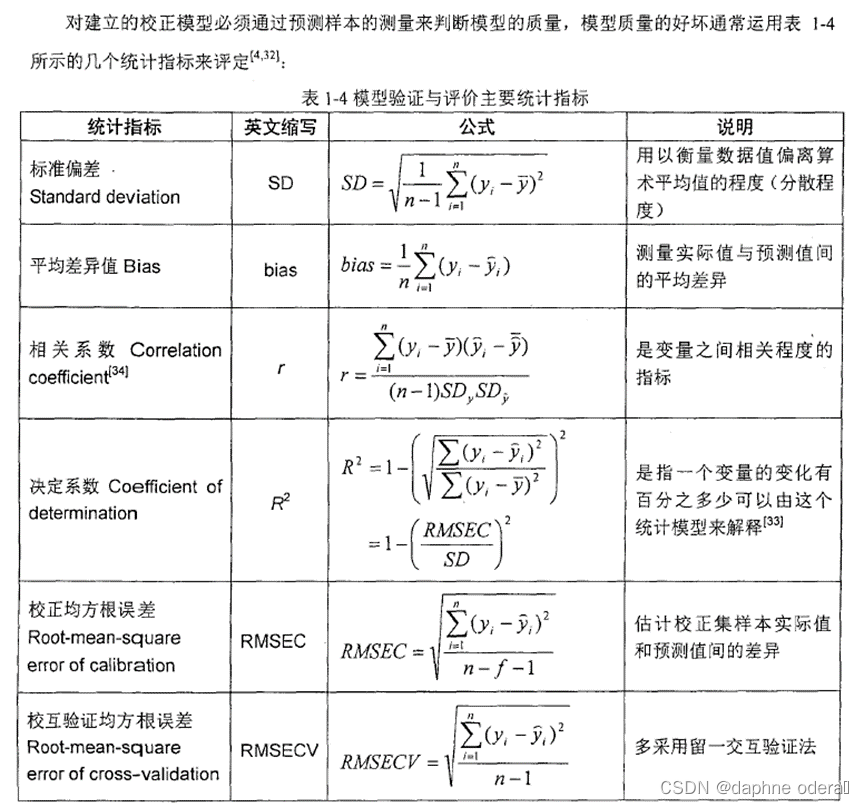
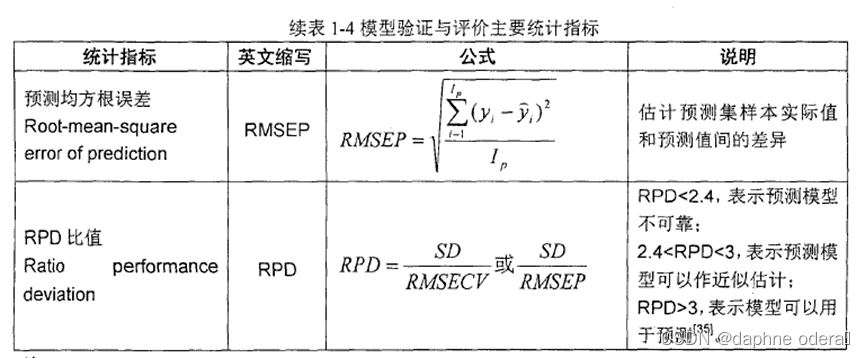
1. 图解
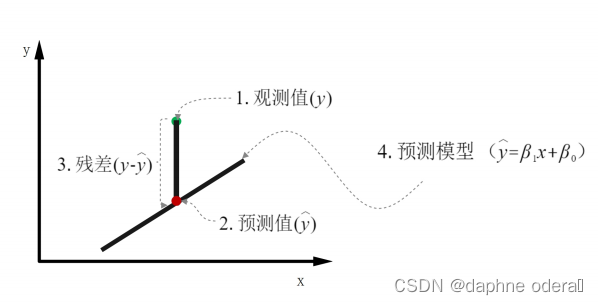
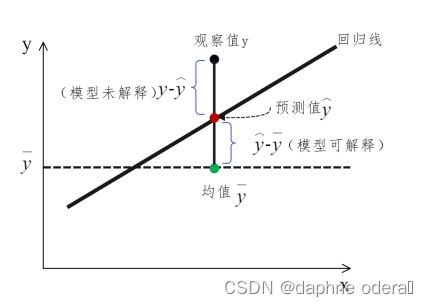
2. 总结

3. 拓展
分类算法评估指标全总结:
三、参考文献
郑权. 基于近红外光谱的柴油硫含量检测方法[D].西南大学,2023.
徐云绯. 基于近红外光谱及模型传递的苹果可溶性固形物含量检测[D].安徽大学,2020.
徐惠荣. 基于可见/近红外光谱的水果糖度检测模型优化及应用研究[D].浙江大学,2010.

















 7748
7748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









