




引言:旧技巧失灵,新模型需要新方法
自ChatGPT-5发布以来,数百万用户报告称,即使他们没有改变提示词,获得的结果却比以前更差了。按理说,GPT-5作为一个更强大的模型,相同的提示词应该产生更好的效果,而非更糟。然而,这就是问题的症结所在:OpenAI对GPT-5的架构进行了根本性改变,导致我们旧的提示工程技术在新模型中效果反而变差了。
只有约5%的用户了解OpenAI做出的这一根本性改变。经过一个月的测试,我发现了5个简单的技巧,它们可以显著地改善GPT-5的输出结果。
在深入了解技巧之前,我们必须先理解GPT-5的两大核心变化,这些变化解释了为什么我们需要新的提示策略。
核心洞察:GPT-5的两大根本性改变
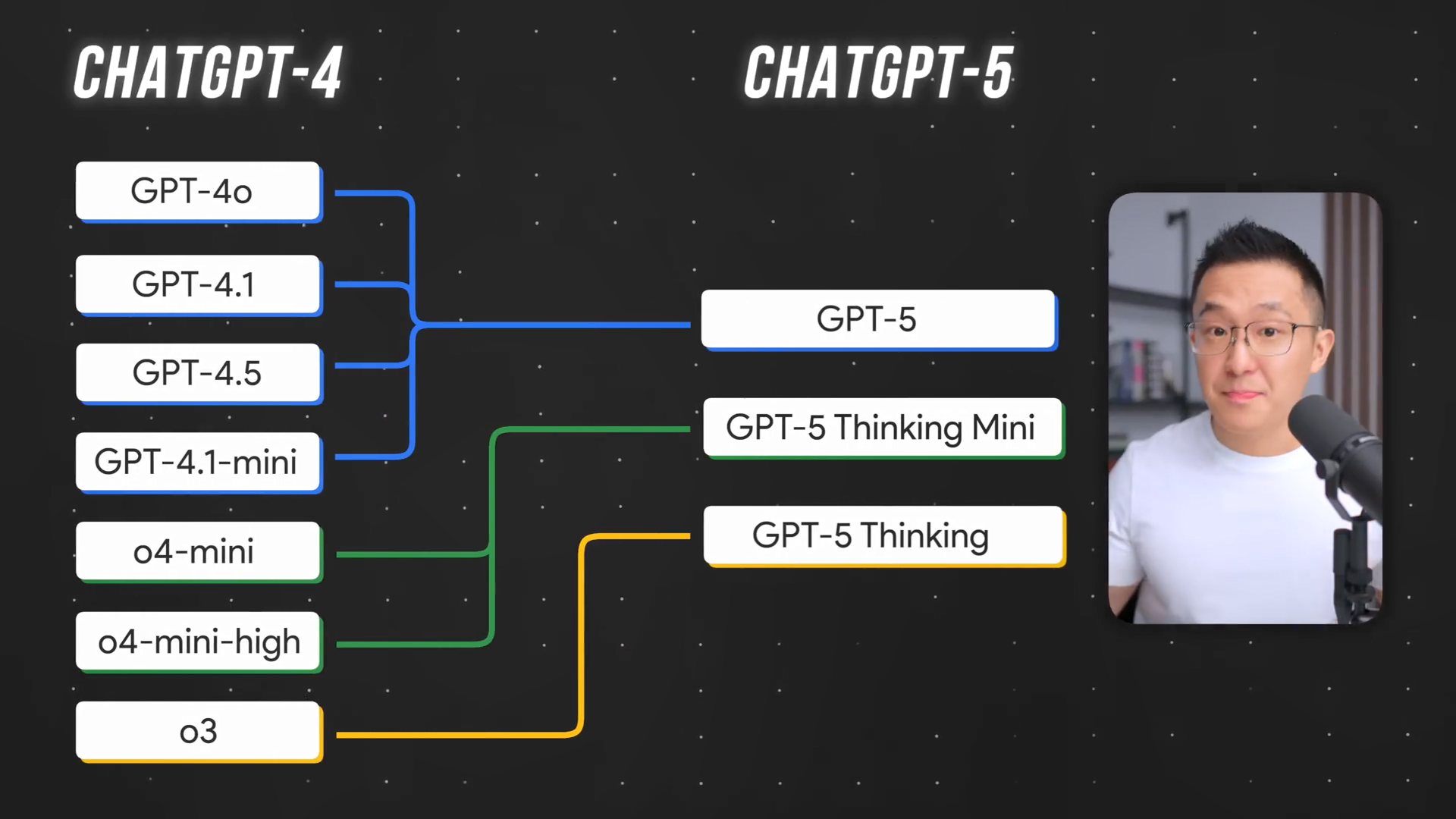
变化一:模型整合与“隐形路由器”
过去,Plus用户可以访问许多不同的模型,但现在只剩下三个:GPT-5、GPT-5 thinking mini 和 GPT-5 thinking。表面上看,选项减少似乎能带来更好的用户体验。
然而,由于这种整合,OpenAI不得不添加一个隐形路由器来决定由哪个模型处理你的请求。这就像致电客服,你解释一遍问题,理论上系统应该将你路由到正确的部门。
问题在于: ChatGPT-5的路由器工作效果不佳。如果你像以前一样只是输入提示词并回车,你可能会随机获得最佳模型的结果,也可能获得最差模型的结果。而且,由于运行更强大的模型成本更高,OpenAI为了自身利益,实际上倾向于让你尽可能使用速度最快、但“最不聪明”的选项。
变化二:对指令的服从能力大幅提高
GPT-5的另一个重大更新是它能更好地遵循指令。OpenAI专门针对AI代理(AI agents)对GPT-5进行
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 195
195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











