 理解编译原理:自展法与编译器自举
理解编译原理:自展法与编译器自举




 本文介绍了编译原理中的自展法和编译器自举概念。自展法通过将语言拆分成多层,逐步构建编译器,简化了直接用机器语言编写编译器的复杂性。编译器自举则是用编译器自身语言编写编译器,使语言成为自编译语言。文章以Pascal编译器为例,阐述了自举过程,并探讨了为何编译语言的反编译难度较大,主要源于编译后的中间代码优化导致源代码难以还原。
本文介绍了编译原理中的自展法和编译器自举概念。自展法通过将语言拆分成多层,逐步构建编译器,简化了直接用机器语言编写编译器的复杂性。编译器自举则是用编译器自身语言编写编译器,使语言成为自编译语言。文章以Pascal编译器为例,阐述了自举过程,并探讨了为何编译语言的反编译难度较大,主要源于编译后的中间代码优化导致源代码难以还原。
前言
新兴语言井喷,实际上都是踩在前辈肩膀上进行功能特化的结果,本系列从编译的角度找到语言的共性和不同语言的联系。
编译器是将源语言(通常指高级语言)转换成目标语言的程序,这个程序也是由某种语言写成并运行的。通常我们希望一个语言的编译器能够运行在裸机上而不依赖其他编译器才能运行,即机器语言。但直接用机器语言实现编译器实在太过麻烦,可以通过自展法一步步简化编写。
一个由语言L编写的,将语言X程序文件翻译成语言Y程序文件的翻译程序称为编译器,记作![]()
自展法
直接用语言A(assembly)完成![]() 的全部内容可能比较复杂。现在考虑到一个特点:
的全部内容可能比较复杂。现在考虑到一个特点:
一个语言L本身是可分割的,内部可以再抽出多层作为单独的语言,比如L1,L2,L3……,L1是整个L的核心,可以编写出等价的L2实现的功能,L1(和L2)可以编写出L3实现的功能,如此递归地包裹多层最后构成整个L。
实现前,可以单独先实现![]() ,然后用L1编写
,然后用L1编写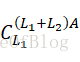 此步已经比直接用A写
此步已经比直接用A写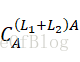 简单了;将这个编译器经过
简单了;将这个编译器经过![]() 编译得到;如此迭代最终得到
编译得到;如此迭代最终得到![]()
编译器自举
编译器自举指用本编译器被编译的语言来编写本编译器。编译器自举一般都是编译器开发的一个里程碑事件。
编译器自举意味着被编译的语言荣升成自编译语言,而且编译器拥有自举能力对实现语言的语法语义本身没有限制。
以上文例子,将语言L变成自编译语言需要如下步骤
- 使用其他高级语言或者汇编(统一记作A)实现
 (可用自展法)
(可用自展法) - 实现
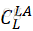 ,用编译后,若测试两者编译效果相同,进行下一步
,用编译后,若测试两者编译效果相同,进行下一步 - 用的可执行程序编译自己,自举完成
举个例子
Pascal编译器,其第一版编译器是用Fortran写的,而这也是常见的编译器自举过程的几乎必走的一条路,即最开始使用X语言(如Fortran)实现Y语言(如Pascal)的编译器,即解决鸡与蛋的问题,所以你的问题二是不正确的,因为我们先要使用其它语言构建出我们的第一版编译器,之后成熟以后,就可以完全使用已经生成好的编译器来编译出我们的新编译器。
作者:蓝色
链接:https://www.zhihu.com/question/28513473/answer/41123883
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
为什么编译语言的反编译那么难?
个人理解,从编译后端分析:中间代码对源代码进行转换,中间代码进行的代码优化策略取决于编译器,如果不知道优化模式,甚至即使知道优化模式,由于优化过程中精简信息,此步就可能导致难以还原。

















 1453
1453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









