







在近期举办的 AWS 中国峰会上,NVIDIA 聚焦于“NVIDIA 全栈加速代理式 AI 应用落地”,深入探讨了代理式 AI (Agentic AI) 技术的前沿发展以及在企业级应用中的深远影响。本文将为您详细介绍此次分享的技术亮点及实践应用。
AI Agent 技术发展现状
随着人工智能技术的不断演进,从感知式 AI 到生成式 AI,再到代理式 AI,我们正见证全新工作方式的诞生。代理式 AI 不仅使更强大的 AI 应用成为可能,而且正迅速成为解决特定业务问题的关键工具。数据显示,到 2025 年,约有一半的组织将使用 AI 智能体 (AI Agent) 帮助解决特定业务问题。随着技术发展,每个人都可以创建自己的 AI Agent。一些工作流可使周期时间缩短 40%。根据 Gartner 报告,到 2028 年,约三分之一的企业级软件开发将引入 AI Agent,而 2024 年这一数字不到 1%,可见相关方面发展迅速。
AI Agent 工作原理与架构
AI Agent 的运行需要人类撰写 prompt,设定角色、场景、任务及需要 AI 执行的操作,并告知整体信息。之后,大语言模型自行生成计划,确定工具,甚至协同调动其他 Agent。经过一系列分析和生成后,需通过批判总结决定 Agent 是继续迭代还是返回结果给用户。
首先,Agent 需持续学习和迭代。通过建立飞轮系统,让模型在实际应用中学习,反哺模型迭代,提高模型鲁棒性和适应性。其次,作为企业级应用,安全性和隐私保护至关重要。需保证结果可靠性,尽量避免大语言模型幻觉。同时,人机或用户与 AI 的交互应尽可能友好,以发挥最佳效果。
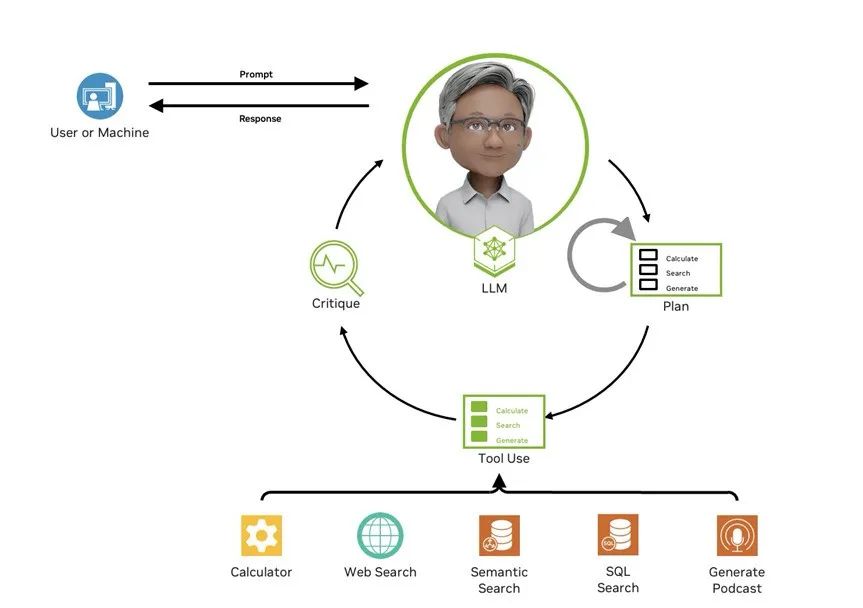
图 1 AI Agent 工作原理
AI Agent 技术框架与实现
一、AI Agent 构建模块
构建 AI Agent,有三个重要组成部分,从下往上看:
NVIDIA NIM 是预构建的容器工具,使用非常简单,只需几分钟即可部署企业级安全稳定的大语言模型推理服务。通过 docker 拉取一个 docker 镜像,完成下载模型等前置工作后,就可以通过一个 Open AI API 或其他行业标准的 API 格式来调用,从而得到一个线上生产环境可用的、安全稳定的大语言模型推理服务。NIM 集成了优化的推理引擎,如 TensorRT-LLM、vLLM 等,这些推理引擎可以帮助优化首 token 延迟、吞吐等指标,在 TCO 可控的情况下,尽量提高吞吐和整体细分表现。此外 NIM 可以在任意地点便捷部署和扩展,包括数据中心、工作站,甚至云上或边缘(如公有云、混合云、私有云等)。NVIDIA 也与国内外的云厂商进行集成,如亚马逊云科技等,可在云上快速使用产品。
NVIDIA NeMo 是一套数据飞轮框架,涵盖模型训练和应用的多个模块。通过该数据飞轮,我们可以持续优化迭代模型和应用。
与 AI Agent 最为紧密的是 NVIDIA AI Blueprint,它是我们提供的工作流,可向开发者展示如何快速构建安全的、企业级应用。NVIDIA AI Blueprint 涵盖 PDF 转音频、视频搜索与总结等多模态模型和工具,可以通过“搭积木”的方式,将多个 Blueprint 模块化的组成一个工作流来解决复杂问题。同时也可以调用外部工具,使整个应用场景或覆盖面更加全面。典型应用包括 AI 研究助理 Agent、客服机器人、安全 AI Agent 等,均作为参考,用户可通过 NeMo 构建符合应用场景的内容。
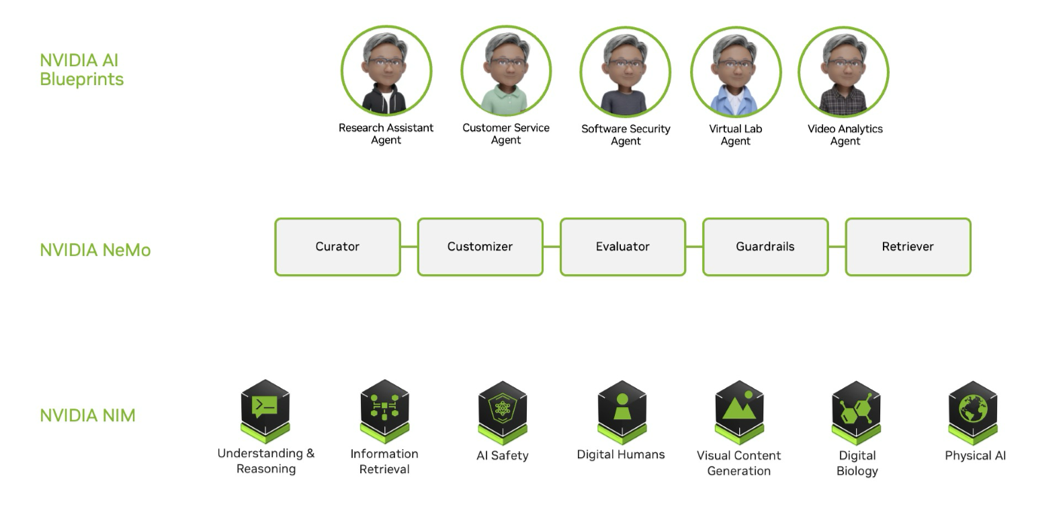
图 2 代理式 AI 的构建模块
二、生成式 AI 数据飞轮:
数据飞轮是一种反馈循环机制,通过从交互或流程中收集数据,持续优化 AI 模型,进而产生更优的结果和更有价值的数据。
NVIDIA NeMo 是一个生成式 AI 的框架,其中:
-
NeMo Curator:在模型预训练阶段需获取大量数据集,但是从网上获取的海量数据集质量往往参差不齐。需要进行质量筛选和去重等步骤。通过集成的 GPU 加速模块,对于十分耗时的质量检测、去重等步骤,可以通过 NeMo Curator 快速实现。
-
NeMo Customizer:模型数据收集完成后,可通过 NeMo Customizer 开始模型训练或微调。
-
NeMo Evaluator:模型训练好后,由 NeMo Evaluator 评估其质量,判断其是否符合预期、满足业务需求。
训练好的模型上线部署后,我们将其构建成更复杂的工作流,将单个 NIM 和其他工具总结成 Blueprint,以服务我们的业务场景。
在 RAG(检索增强生成)或 Agent 过程中,向量检索是一个十分重要的技术模块。NVIDIA cuVS 集成了 GPU 加速的 ANN (Approximate Nearest Neighbors) 算法,可以提高向量检索的效率。作为企业级应用,安全性和隐私保护至关重要,NVIDIA Guardrails 作为 AI 护栏,可以检测生成过程中比较危险或不太友好的内容,使线上服务更加安全可靠。
经过上述链路,最后线上验证过的数据通过回路回到数据集,这部分数据再经过 NeMo Customizer 进行训练微调,就完成了数据闭环。通过这样一步一步的迭代,线上数据反哺回模型训练。
三、面向企业应用的大语言模型定制
我们的模型能力不断增强,使得线上服务效果更加安全可靠。Customizer 涵盖的能力多元,从最初的简单微调、复杂的 sft,到现在常用的强化学习方法。我们还可根据企业特定场景进行相应微调。
以 DeepSeek-V3 训练为例,Transformer Engine 集成了类似 DeepSeek-V3 的 FP8 block wise 算子和 recipe。在 Megatron-Core 层面,基于 DeepSeek-V3 特定架构,支持了 MLA 结构。同时,对 MTP 也有较好支持,还有负载均衡和路由策略。除了支持外,还有相关优化。
DeepSeek-V3 使用 DualPipe 流水线并行策略,Megatron-Core 中也有类似策略,称为 1F1B (F: Forward, B: Backward)。通过 1F1B 的流水线机制,很好地将 MoE 计算与通信进行 overlap,减小训练延迟,提高训练效率。
同时,对于 DeepSeek 开源的内容,我们也有较好集成。在并行方面,Megatron-Core 擅长并行,我们做了 MoE parallel folding。这是指在一个模型里既有 Attention 层,也有 MoE 层,我们针对不同层进行处理。可以使用 parallel folding 方法,将其并行策略解耦,即 Attention 部分和 MoE 层分别采用不同的并行策略,以达到整体更好的效率。NeMo,即更面向用户的层面,除了支持 DeepSeek 的 sft,同时也支持把 DeepSeek-R1 蒸馏到小模型。
四、加速推理的优化技术
如今模型越来越大,参数达到千亿级,需要更强的推理算力。同时,这些模型都是推理模型,逻辑推理需要更多的思考时间,甚至需要超过 100 倍的思考 token。此外,我们的模型现在也支持更长的上下文窗口,在使用过程中,无论是对话系统中的多轮对话,还是 Agent 使用过程中的 Agent-to-Agent、human-to-Agent 等交互手段,都会使上下文 context 变得更长,甚至达到百万级输入 token 以上,这些都对计算推理提出了更多的挑战,也推动着新型优化技术的诞生。
1. 分离式部署 (PD 分离):
大语言模型的推理分为两个阶段。第一个是预填充 (Prefill) 阶段,这是一个计算密集 (Compute-Bound) 阶段,需要较多算力。第二个是解码 (Decode) 阶段,在这个阶段,随着吐出的 token 越来越多,它进入了一个内存密集 (Memory-Bound) 阶段。为了更好地利用预填充和解码的相关特性来优化首 token 延迟和吞吐,分离式部署是比较适应大语言模型推理场景的部署技术。将预填充和解码两个阶段分开,结合其计算特点,分配适合其特定型号的 GPU,并针对不同特性制定不同策略,结合线上 SLA 服务标准,分配不同数量的节点,以优化首 token 延迟和吞吐。
2. NVIDIA Dynamo:
NVIDIA Dynamo 是针对分离式部署或大规模分布式部署的框架,具备以下特点:
-
分布式部署:支持便捷地扩充至上千卡 GPU 的线上部署。
-
GPU 管理及调度(GPU 规划器):可根据线上实时请求变化或 SLA 服务标准动态调整预填充节点或解码节点的数量,以更好地满足服务需求。
-
智能路由:在多个节点的情况下,可以结合 KV Cache 等指标,将 decode 任务分配给最佳节点。
典型应用场景案例
一、AI 研究助理 Agent
AI 研究助理 Agent 执行 PDF 转音频的任务。将论文、博客等文档输入到模型中,通过工具转换为 markdown 文件。在此过程中,需要为 Agent 提供复杂的 prompt。首先,按照要求整理出文件大纲,然后根据大纲将脚本分段,进行深入探索并总结有思考性的内容。然后,对整体脚本进行优化,并将多个部分组合输出整理成结构化文本。在这个过程中,人类需要做的是梳理出多个 prompt,并在多个阶段调用不同尺寸的模型来处理不同任务。文档输入时内容庞杂,使用尺寸更大的模型来处理复杂任务。总结时可使用尺寸更小的模型来提高工作流的经济效益。通过这一系列步骤后,输出文本再通过类似 ElevenLabs 的 TTS 服务或 TTS 模型合成为音频文件,返回给用户。
二、软件安全检测 Agent
随着 CVE.org 记录的漏洞突破 20 万大关,软件安全补丁管理面临严峻挑战。传统人工分析、日常扫描漏洞需耗时数日,而基于事件驱动 RAG 技术的软件安全检测 Agent 可将缓解时间压缩至秒级,通过实时检测新软件包或漏洞特征,智能判定组件风险,并自主执行全流程检查清单,最终向安全团队提交包含可操作建议的分析报告。
三、视频分析 Agent
用于视频搜索和总结的 Agent 每天可分析 10 万 PB 级的视频数据。该 Agent 使用 NVIDIA Cosmos Nemotron 的视觉语言模型,可以从视频数据中提取文本信息,再通过 NeMo Retriever Embedding 抽取为 embedding,形成向量数据库。同时,并行流程通过分析从视频中提取的信息构建图数据库。当有新视频输入时,就可通过召回链路查询上述数据库,再通过大模型进行总结生成,完成整个视频分析链路。
总结
从 AI 研究助理、软件安全检测到大规模视频分析,这些应用场景正切实推动代理式 AI 落地,在解决复杂业务问题、提升工作效率方面发挥关键作用。NVIDIA 通过全栈解决方案和工具,助力企业构建安全、稳定、高效的代理式 AI 应用。
查看构建 AI 助手指南,可复制链接至浏览器获取电子书:
https://www.nvidia.cn/lp/ai-data-science/generative-ai/building-intelligent-ai-chatbots-with-rag-ebook/?ncid=partn-274398


















 572
572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









