




使用selenium进行数据爬取时,遇到了登录验证码,如下所示:
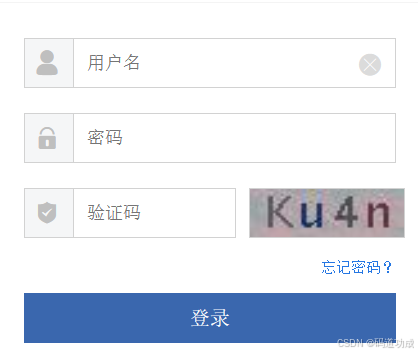
这里使用ddddocr将验证码图片中的文字识别;对于ddddocr的介绍可查看官网地址:GitHub - sml2h3/ddddocr: 带带弟弟 通用验证码识别OCR pypi版
这里介绍下思路:
1、将登录页保存为图片;
2、查找到验证码图片元素,获取到元素的location和size信息,基于上一步的图片裁剪出验证码图片;
3、调用ddddocr进行识别;
其中,第1步和第2步,按理说页可以通过find_element方法查找到验证码图片,再获取src属性并保存的方式处理。
废话不多说,直接上代码:
# pip install ddddocr
import ddddocr
# pip install pillow
from PIL import Image
def login(browser):
login_url = "https://***"
browser.get(login_url)
time.sleep(2)
browser.save_screenshot("currentpage1.png")
# '//*[@id="randimg"]' 为验证码图片的xpath定位
yzm = htmlimg2txt(browser, '//*[@id="randimg"]')
def img2txt(image_path):
ocr = ddddocr.DdddOcr()
image = open(image_path 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











