




 本文介绍了一种集成多种最新深度学习组件的优化器Ranger21,并通过Imagenette和CIFAR-10数据集上的实验对比了其与SGD的表现。尽管Ranger21在准确率上有优势,但在训练后期可能会出现验证集损失增大的问题。
本文介绍了一种集成多种最新深度学习组件的优化器Ranger21,并通过Imagenette和CIFAR-10数据集上的实验对比了其与SGD的表现。尽管Ranger21在准确率上有优势,但在训练后期可能会出现验证集损失增大的问题。
这两天看到了一个叫Ranger21(github / arxiv)的训练器,写的是将最新的深度学习组件集成到单个优化器中,以AdamW优化器作为其核心(或可选的MadGrad)、自适应梯度剪裁、梯度中心化、正负动量、稳定权值衰减、线性学习率warm-up、Lookahead、Softplus变换、梯度归一化等,有些技术我也没接触过,反正听着很厉害。
于是在Imagenette(github),Imagenette是Imagenet中10个易于分类的类的子集,训练集每类大概900多张,验证集每类大概400张左右,用Xception试了一下,如下图所示:
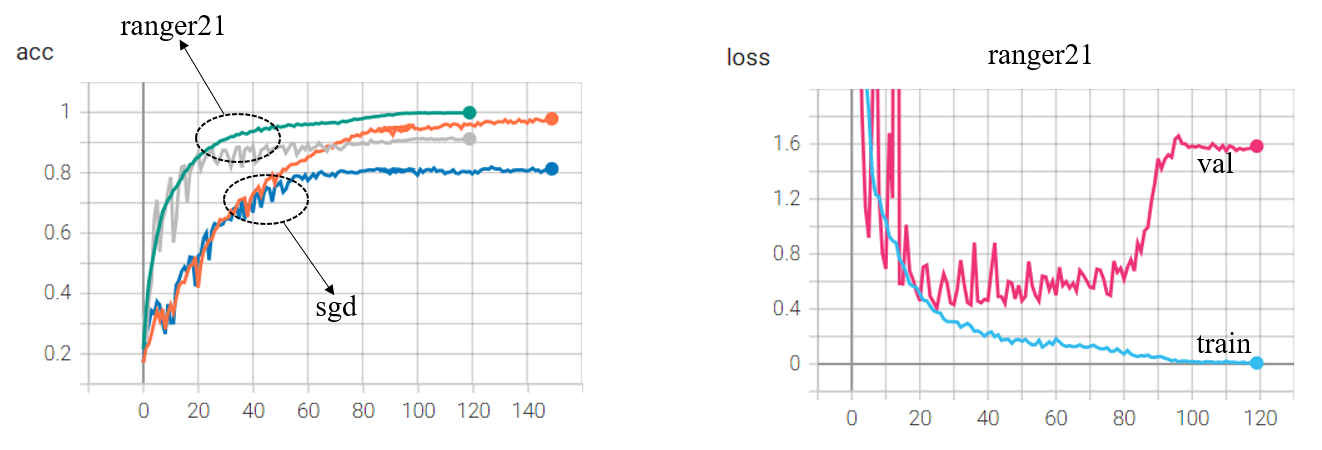
acc方面ranger21可以超过90%,而sgd只有81%(没仔细调参),似乎用起来比sgd更简单一点,不仅快而且泛化性还强(注:二者用一样的学习率,ranger21自带的学习率策略是warmup – stable – warmdown,sgd用的余弦退火),但是几次实验下来发现ranger21总是在训练末期,验证集上的损失会上升,百度了一下可能原因是这个,意思是模型过于极端,在个别预测错误的样本上损失太大,因此拉大了整体损失,但不怎么影响准确度。
之后还是在cifar10上进行了一下实验,模型采用的是pre-activation的resnet18(但其实记得论文说pre-act对浅层用处不大),并加上了squeeze-excitation模块,即se-preact-resnet18代码如下所示:
import torch
from torch import nn
class SEBlock(nn.Module):
def __init__(self, in_planes, planes, stride=1):
super(SEBlock, self).__init__()
self.residual = nn.Sequential(
nn.BatchNorm2d(in_planes),
nn.ReLU(inplace=True),
nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(planes),
nn.ReLU(inplace=True),
nn.Conv2d(planes, planes, kernel_size=3 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 485
485




 到【灌水乐园】发言
到【灌水乐园】发言







