




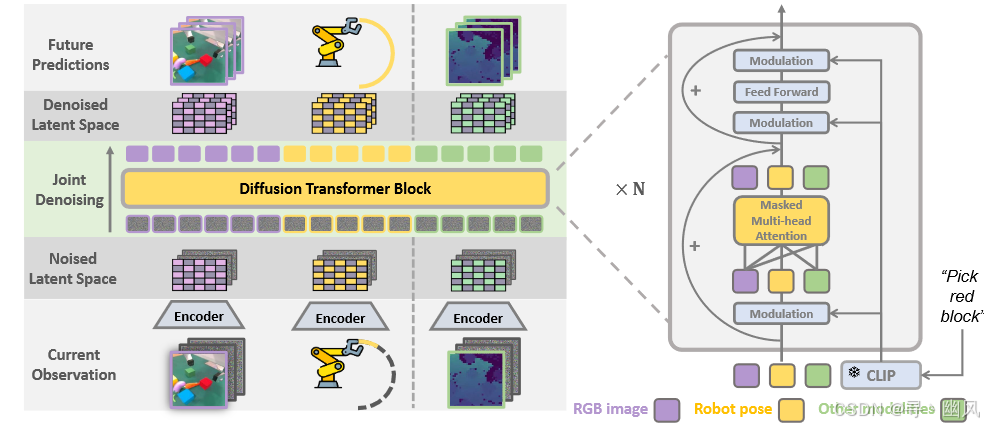
以前的 method 是输入视频输出视频或者输入视频和 action 学习 action,该方法认为 action,video 和 other condition 具有一定联系,所以一次性对所有的进行 joint denoise。
网络结构采用 Masked Multi-head Attention 关联不同模态,使用 DiT 的 backbone。
以前的 method 是输入视频输出视频或者输入视频和 action 学习 action,该方法认为 action,video 和 other condition 具有一定联系,所以一次性对所有的进行 joint denoise。
网络结构采用 Masked Multi-head Attention 关联不同模态,使用 DiT 的 backbone。
 2万+
6401
7363
7479
1335
960
2万+
6401
7363
7479
1335
960





















 到【灌水乐园】发言
到【灌水乐园】发言







