




本文探索了一类新的基于 Transformer 的扩散模型 Diffusion Transformers (DiTs)。本文训练 latent diffusion models 时,使用 Transformer 架构替换常用的 UNet 架构,且 Transformer 作用于 latent patches 上。
网络结构
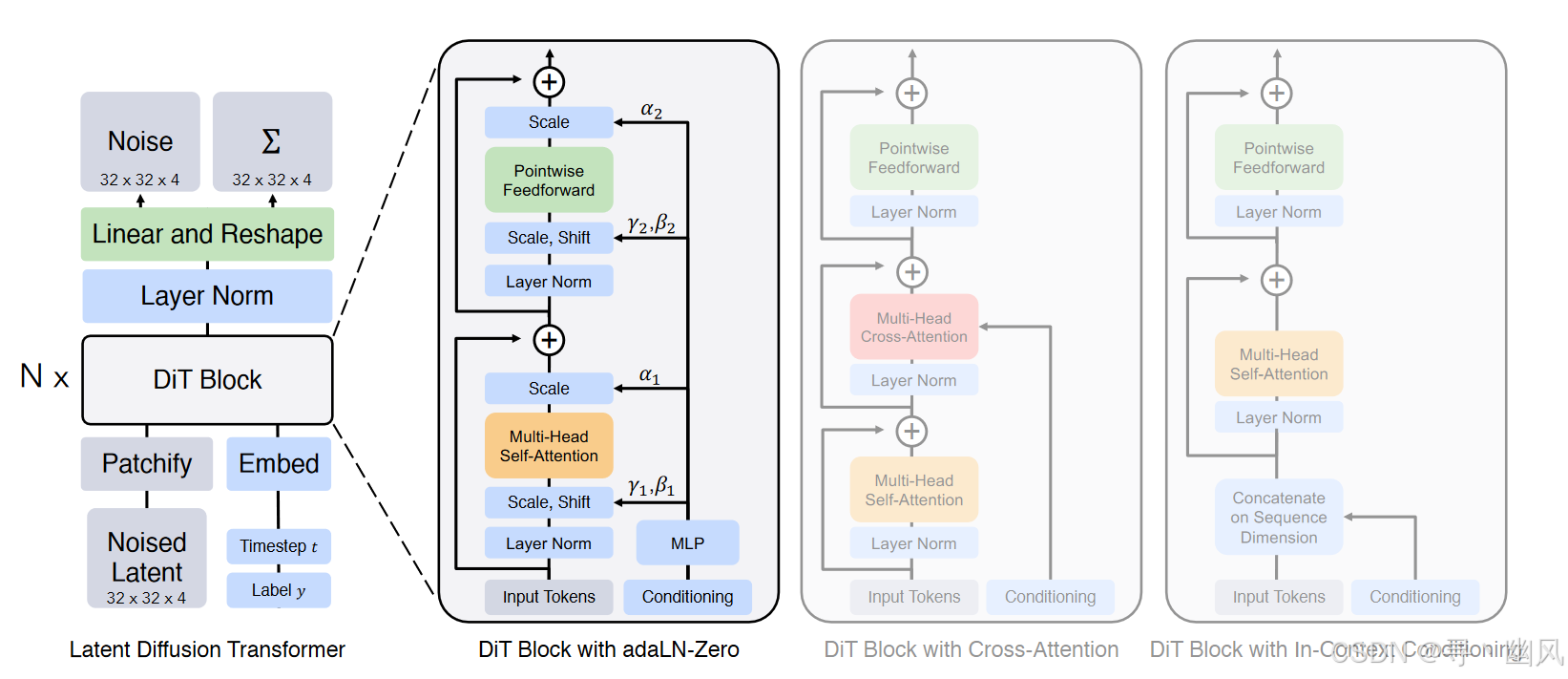
对输入进行 Patchify 后,应用标准的 ViT 频率位置编码(sin-cos)
- 上下文条件:将时间步长 t 和类别标签 c 作为两个额外 token 附加到输入序列
- 交叉注意力:将 t 和 c 的 Embedding 链接为一个长度为 2 的序列,且区分于 image token 序列,在 Transformer Block 后添加一个 Cross-Attention 块,此操作带来的额外 GFLOPs 约为 15%
- adaLN:遵循 GAN 的自适应归一化层设计,通过 t 和 c 回归得到位移参数 γ,β\gamma, \betaγ,β
- adaLN-ZERO:对每个 Block 的第一个卷积进行 Zero-Intialization,得到缩放参数 α\alphaα
代码实例
时间步长和类别标签的嵌入
class TimestepEmbedder(nn.Module):
"""
Embeds scalar timesteps into vector representations.
"""
def __init__(self, hidden_size, frequency_embedding_size=256):
super().__init__()
self.mlp = nn.Sequential(
nn.Linear(frequency_embedding_size, hidden_size, bias=True),
nn.SiLU(),
nn.Linear(hidden_size, hidden_size, bias=True),
)
self.frequency_embedding_size = frequency_embedding_size
@staticmethod
def timestep_embedding(t, dim, max_period=10000):
"""
Create sinusoidal timestep embeddings.
"""
# 参考 OpenAI 的 glide 实现
# https://github.com/openai/glide-text2im/blob/main/glide_text2im/nn.py
half = dim // 2
freqs = torch.exp(
-math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half
).to(device 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3428
3428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









