




 本文介绍了SQL中的group by和partition by的区别。通过创建和操作tb_Student表,展示了如何使用group by按班级分组求总成绩,以及partition by如何在每个班级内部进行窗口函数计算。group by返回每个分组的独特结果,而partition by在每个分区内保留所有行。同时,使用partition by时,select后的字段可以包含*,但需配合聚合函数,而group by则需与分组字段匹配。
本文介绍了SQL中的group by和partition by的区别。通过创建和操作tb_Student表,展示了如何使用group by按班级分组求总成绩,以及partition by如何在每个班级内部进行窗口函数计算。group by返回每个分组的独特结果,而partition by在每个分区内保留所有行。同时,使用partition by时,select后的字段可以包含*,但需配合聚合函数,而group by则需与分组字段匹配。
group by 与 partitionby的区别
总结:
一、首先创建一个表
CREATE TABLE [dbo].[tb_Student](
[ID] [int] NOTNULL,
[stuName][nvarchar](50) NOT NULL,
[grade] [int] NOTNULL,
[age] [int] NOTNULL,
[classID] [int] NOTNULL,
)
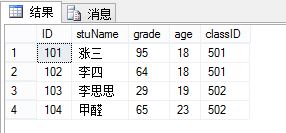
原表中有这些数据
二、用group by按照班级进行分组
select classID,SUM(grade) from tb_Student group byclassID
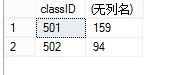
三、
用partition by按照班级进行分组
select classID,SUM(grade) over(partition by classID) fromtb_Student
总结:
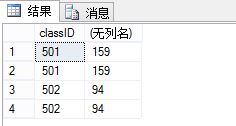
(1) 你会发现partition by中每个学生都会被划分出来,并在每个学生后面加上班级编号和班级总成绩,而groupby只会取一次,班级编号和班级总成绩 ,当然以上的重复项你可以使用distinck来进行删除重复项,像这样
select DISTINCT classID,SUM(grade) over(partition by classID)from tb_Student
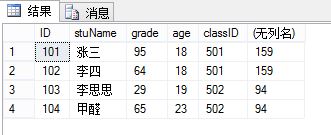
(2) 当用group by 进行分组时select 后面的字段必须是group by后面所存在的字段,如果不是这样就会出错,
而,partition by中则select 后面可以是 * ,但*后面必须要有聚合函数,否则会出错
select *, SUM(grade) over(partition by classID) fromtb_Student 正确,如下所示
select * over(partition by classID) from tb_Student 错误
他们还有其它用法与区别,我目前只知道这些

















 1856
1856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









