




 本文介绍了一个简单的Python爬虫实例,利用requests库抓取网页上的省份及对应邮编信息。通过分析网页结构并使用SAX解析XML来提取所需数据。
本文介绍了一个简单的Python爬虫实例,利用requests库抓取网页上的省份及对应邮编信息。通过分析网页结构并使用SAX解析XML来提取所需数据。
此系列博文是朕在学习网络爬虫课程中的笔记,供自己复习和大家参考
python课程和爬虫建议网上看廖雪峰老师的网站,有很详细的教导
网络爬虫首先需要爬虫工具,初学者先使用requests工具,关于requests可以参考here,引用彼博主的一句话
“requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多”
以下以老师上课讲的爬取各个省份邮编为例,先放总的代码,再逐步解释:
import requests
import xml.etree.ElementTree as ET
from xml.parsers.expat import ParserCreate
class DefaultSaxHandler(object):
def __init__(self, provinces):
self.provinces = provinces
# 处理标签开始
def start_element(self, name, attrs):
if name != 'map':
name = attrs['title']
number = attrs['href']
self.provinces.append((name, number))
# 处理标签结束
def end_element(self, name):
pass
# 文本处理
def char_data(self, text):
pass
def get_province_entry(url):
# 获取文本,并用gb2312解码
content = requests.get(url).content.decode('gb2312')
# 确定要查找字符串的开始结束位置,并用切片获取内容。
start = content.find('<map name=\"map_86\" id=\"map_86\">')
end = content.find('</map>')
content = content[start:end + len('</map>')].strip() #(第一处)
provinces = []
# 生成Sax处理器
handler = DefaultSaxHandler(provinces)
# 初始化分析器
parser = ParserCreate()
parser.StartElementHandler = handler.start_element
parser.EndElementHandler = handler.end_element
parser.CharacterDataHandler = handler.char_data
# 解析数据
parser.Parse(content)
# 结果字典为每一页的入口代码
return provinces
provinces = get_province_entry('http://www.ip138.com/post')
print(provinces)
选择性讲解:
Attention 1: .find()和.strip()的使用
上面代码中使用了.find()函数,实际上就是查找find括号内的字符,举例如下(可以参考http://www.runoob.com/python/att-string-find.html):
描述
Python find() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1。
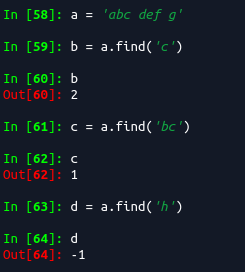
注意索引是从0开始数起的,再举例看看.strip()函数的使用,参考;https://www.cnblogs.com/yyxayz/p/4034299.
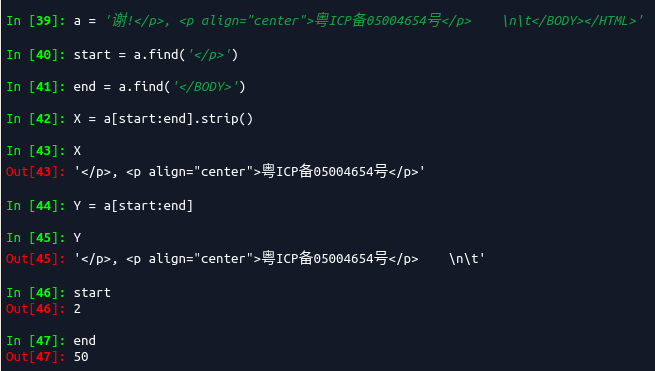
所以.strip()是用来删除’\n’, ‘\r’, ‘\t’, ’ ‘)等的。
凌晨2点了,,,回去睡觉~~~,明天再补充。
更新
注意,代码中第一处位置,在使用.find()函数时得到的是索引值,而[start:end]是不包含end的索引值的,因此需要+len(‘’)将end索引值加入进去

















 1251
1251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









