







使用xpath取出来的是空,爬取到本地的html,时间的标签如下,内容也是是空的
<em id="publish_time" class="rich_media_meta rich_media_meta_text"></em>经过查找发现网页使用的是时间戳,通过xpath获取时间戳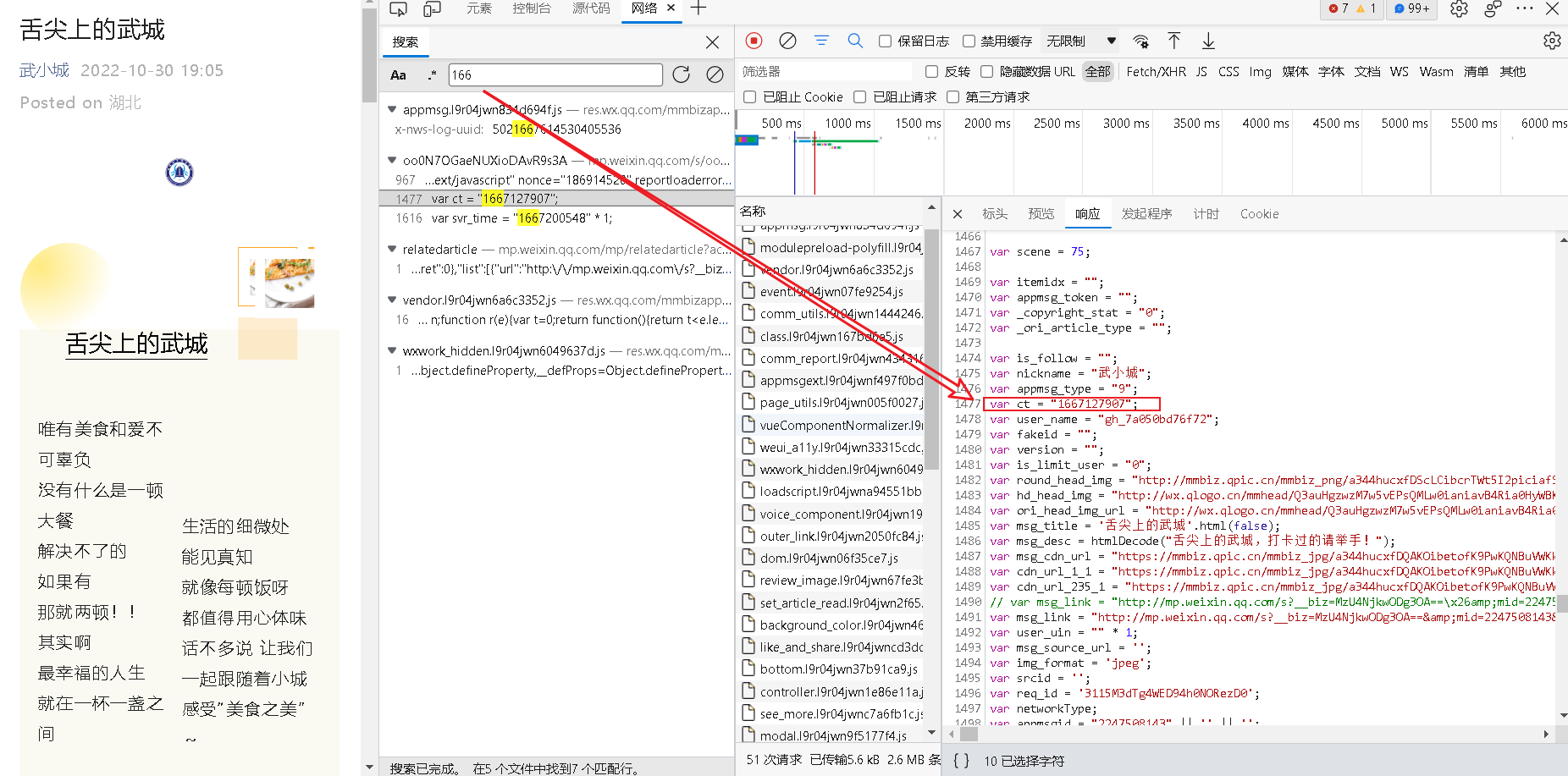
pat1 = r"var ct = \"(\d+)\""
date1 = re.search(pat1, reponse).group(1)
date1 = int(date1)
#转换为其他日期格式,如:"%Y-%m-%d %H:%M:%S"
timeArray = time.localtime(date1)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)

















 1354
1354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











