




 文章介绍了如何使用Pandas的rolling方法处理序列数据,包括计算平均值、总和,以及自定义聚合函数。还提到了如何处理缺失值,以及如何根据时间窗口进行条件计算。此外,文章展示了如何处理特定时间范围内的数据并排除无效值。
文章介绍了如何使用Pandas的rolling方法处理序列数据,包括计算平均值、总和,以及自定义聚合函数。还提到了如何处理缺失值,以及如何根据时间窗口进行条件计算。此外,文章展示了如何处理特定时间范围内的数据并排除无效值。
一个问题举例
假设有一个5天的收益数据,需要每3天求出一次平均值来达成某个需求:
| date | revenue |
|---|---|
| 2023-05-01 | 10 |
| 2023-05-02 | 20 |
| 2023-05-03 | 30 |
| 2023-05-04 | 40 |
| 2023-05-05 | 50 |
1号、2号和3号的数据求一次平均值,2号、3号和4号的数据求一次平均值,3号、4号和5号的数据求一次平均值,这样的需求该如何计算?
pandas的Series有一个rolling方法,用来专门解决这种移动窗口聚合运算问题,举个简单的使用例子:
import pandas as pd
series = pd.Series([10, 20, 30, 40, 50])
amount = series.rolling(3).mean()
print(amount)
输出如下
0 NaN
1 NaN
2 20.0
3 30.0
4 40.0
dtype: float64
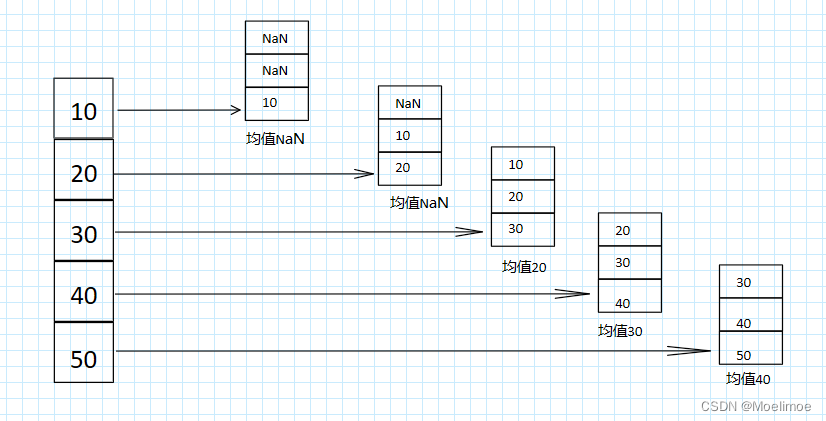
可以看到需求确实如我们所需要的,但是你可能又会说,前两个均值不应该是NaN,少于1天的时候求均值就使用已有天数的数据来计算,别担心,此时只需要指定rolling的参数min_period为1即可:
import pandas as pd
series = pd.Series([10, 20, 30, 40, 50])
amount = series.rolling(3, min_periods=1).mean() # min_period可以指定窗口计算所需要最少的元素,这个值必须小于等于第一个参数窗口的大小3
print(amount)
0 10.0
1 15.0
2 20.0
3 30.0
4 40.0
dtype: float64
结果完美满足需求
然后欠缺考虑周全的产品可能又会跟你说,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









