




 ModelWhale教学平台进行了一系列功能升级,包括自动评估作业的改进、团队协作功能增强、作业预览与修改、Notebook提交优化等,旨在提升教学效率并支持数据科学教育。
ModelWhale教学平台进行了一系列功能升级,包括自动评估作业的改进、团队协作功能增强、作业预览与修改、Notebook提交优化等,旨在提升教学效率并支持数据科学教育。
冬至时节,2023 已进入尾声,ModelWhale 于今日迎来新一轮的版本更新,与大家一起静候新年的到来。
本次更新中,ModelWhale 主要进行了以下功能迭代:
- 自动评估作业
- 新增 提交代码(团队版✓ )
- 新增 作业在线预览、手动改分(团队版✓ )
- 优化 Notebook 内提交作业代码(自动评估作业、实训作业、大作业)(团队版✓ )
- 新增 作业项必填/非必填设置(团队版✓ )
- 新增 作业评阅进度表(团队版✓ )
- 优化 数据引用信息自动配置(基础版✓ 专业版✓ 团队版✓ )
- 优化 在线发票开具(基础版✓ 专业版✓ 团队版✓ )
1、自动评估作业,新增 提交代码(团队版✓ )
为促进高校教改,依据 OBE 成果导向的教育模式,ModelWhale 教学平台帮助学生真实 Coding、逐步形成数据科学思维,也提供老师丰富的案例教材、教学工具、作业系统(实践作业、分组作业、自动评估作业等),协助教学课程的搭建。其中,自动评估作业通过预先设置的“评审指标/脚本”、“答案文件”自动化即时评分,为避免可能的作弊情况,现新增提交代码:可由老师手动核查(抽查)学生代码。
Tips:除“关联代码”外,老师也可以要求学生额外提交“文本”。

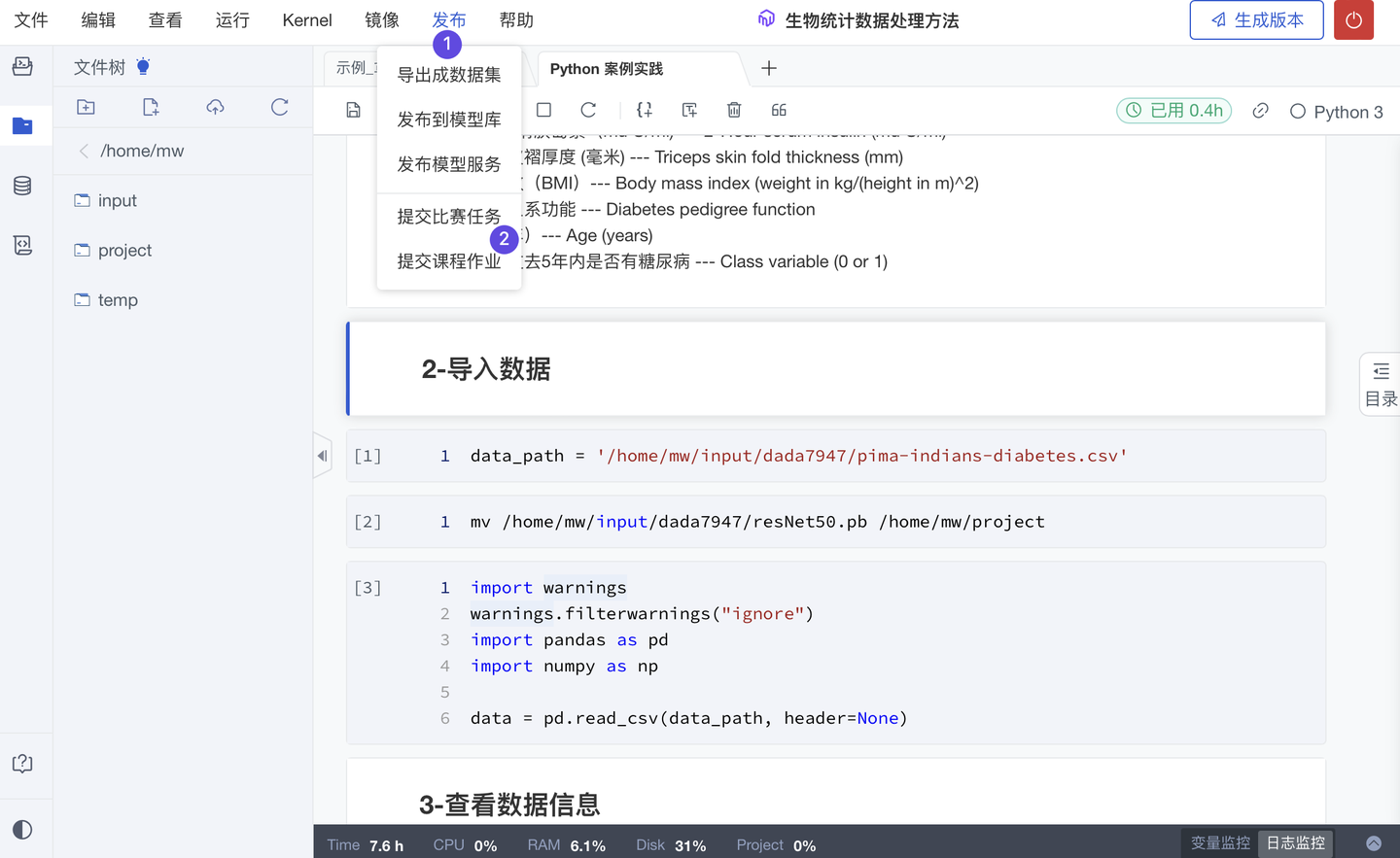
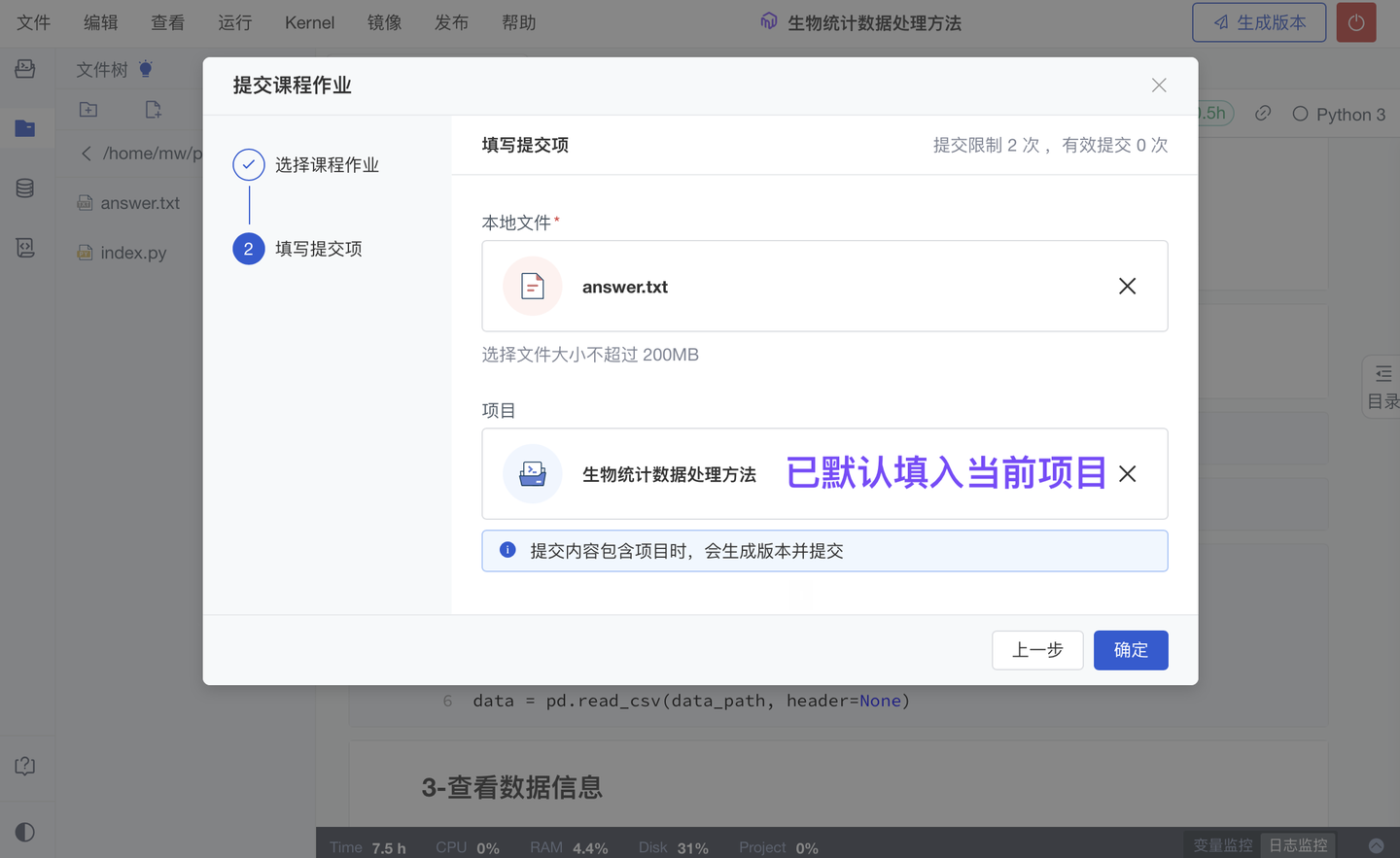
2、自动评估作业,新增 作业在线预览、手动改分(团队版✓ )
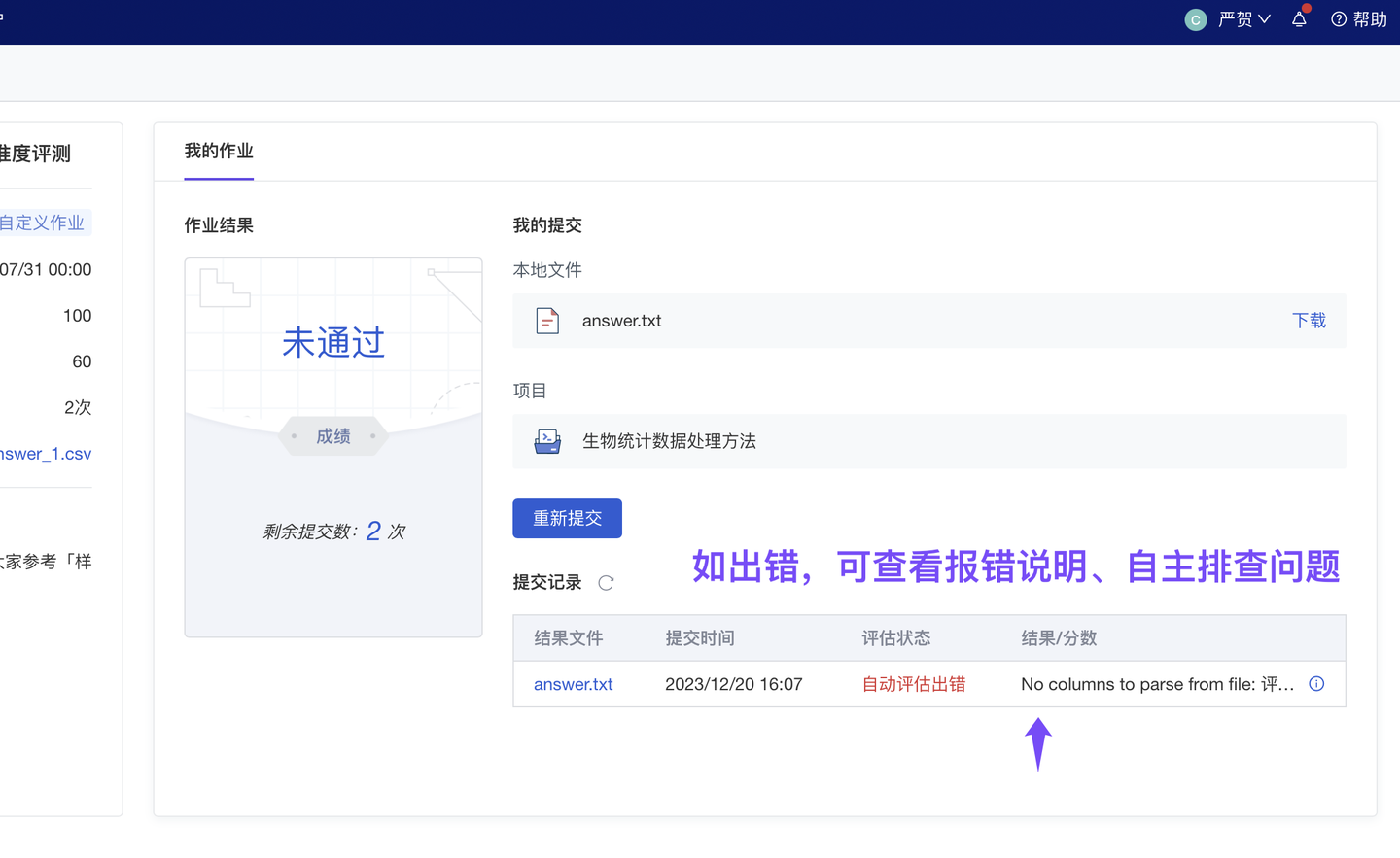
承上,为减轻老师的评审压力、避免“每次评审作业都需要把全班所有学生的代码文件下载、运行,再评出作业分”,自动评估作业也像其他作业(实训作业、分组作业)一样:支持在线预览学生 Notebook 代码、在线运行学生 Notebook;作业文件(如 py, pdf, html, txt, office 文件)也支持在线预览。
如发现作弊情况,现也已支持手动改分,更改由“评审指标/脚本”自动计算出的分数。
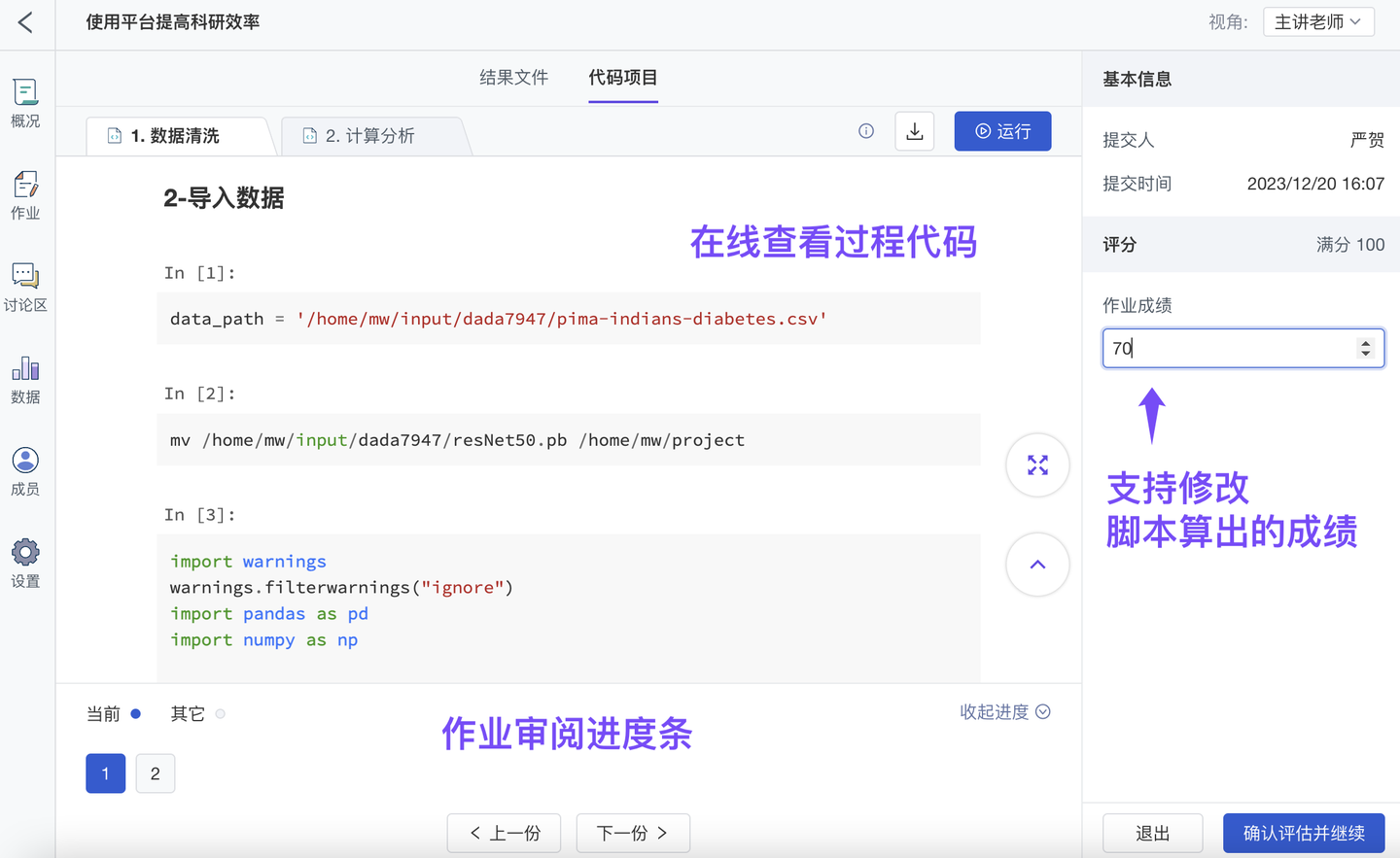
3、优化 Notebook 内提交作业代码(自动评估作业、实训作业、大作业)(团队版✓ )
ModelWhale 教学平台除提供【课程】模块供教材的汇总展示外,还为每位学生准备了专属的研究分析工作台以便真实上手实践、感受代码运行效果。完成作业后,学生现可以在 Notebook 运行时内便捷完成多种作业类型的提交,包括“案例实训作业”、“课程大作业”及其他“手动评估作业”(不再仅局限于“自动评估作业”)。
在 Notebook 内提交作业时,学生除了可以提交当前项目的“运行结果文件”外,现还支持提交关联的“代码项目”(我们会自动填入当前的“代码项目”)。
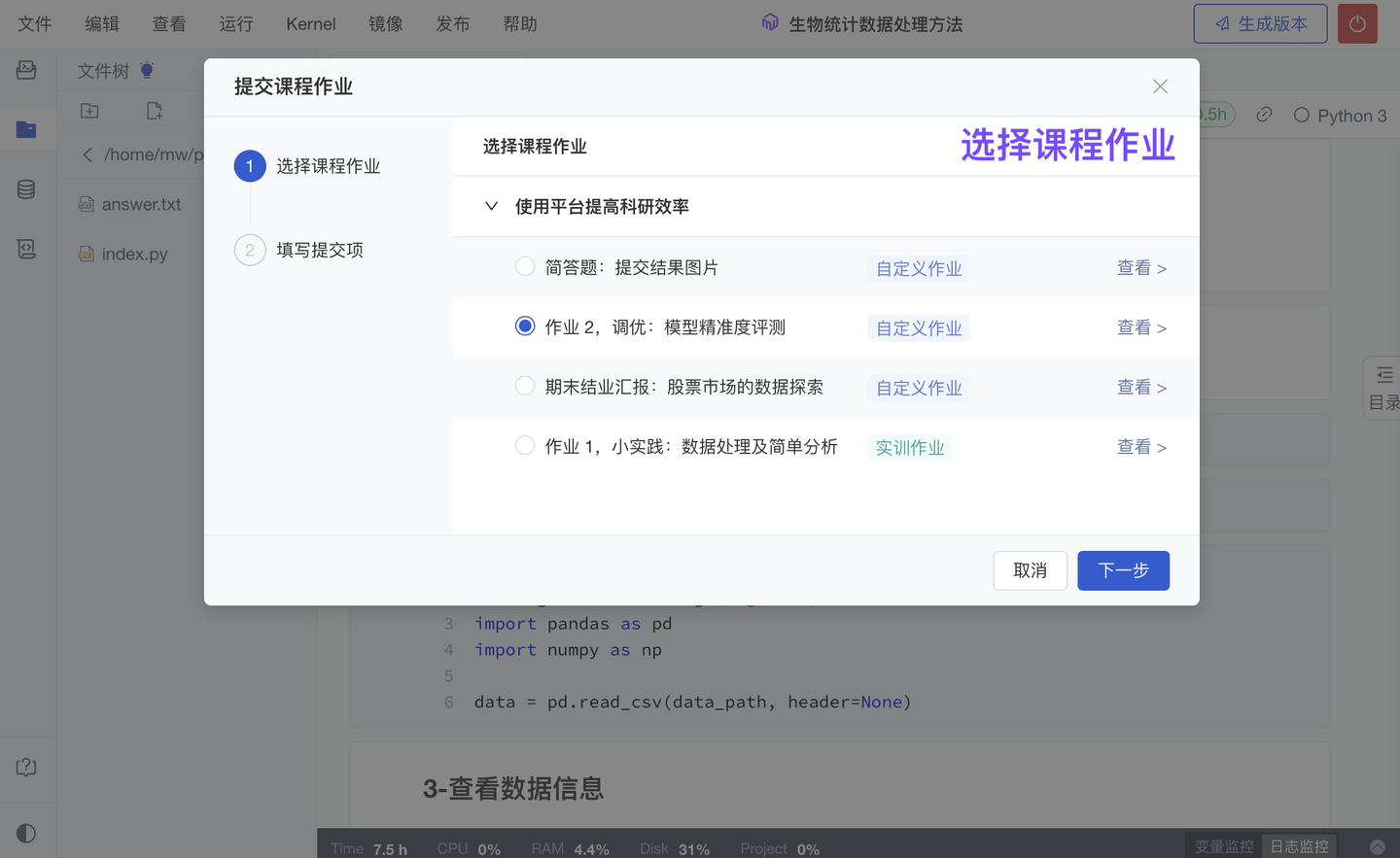
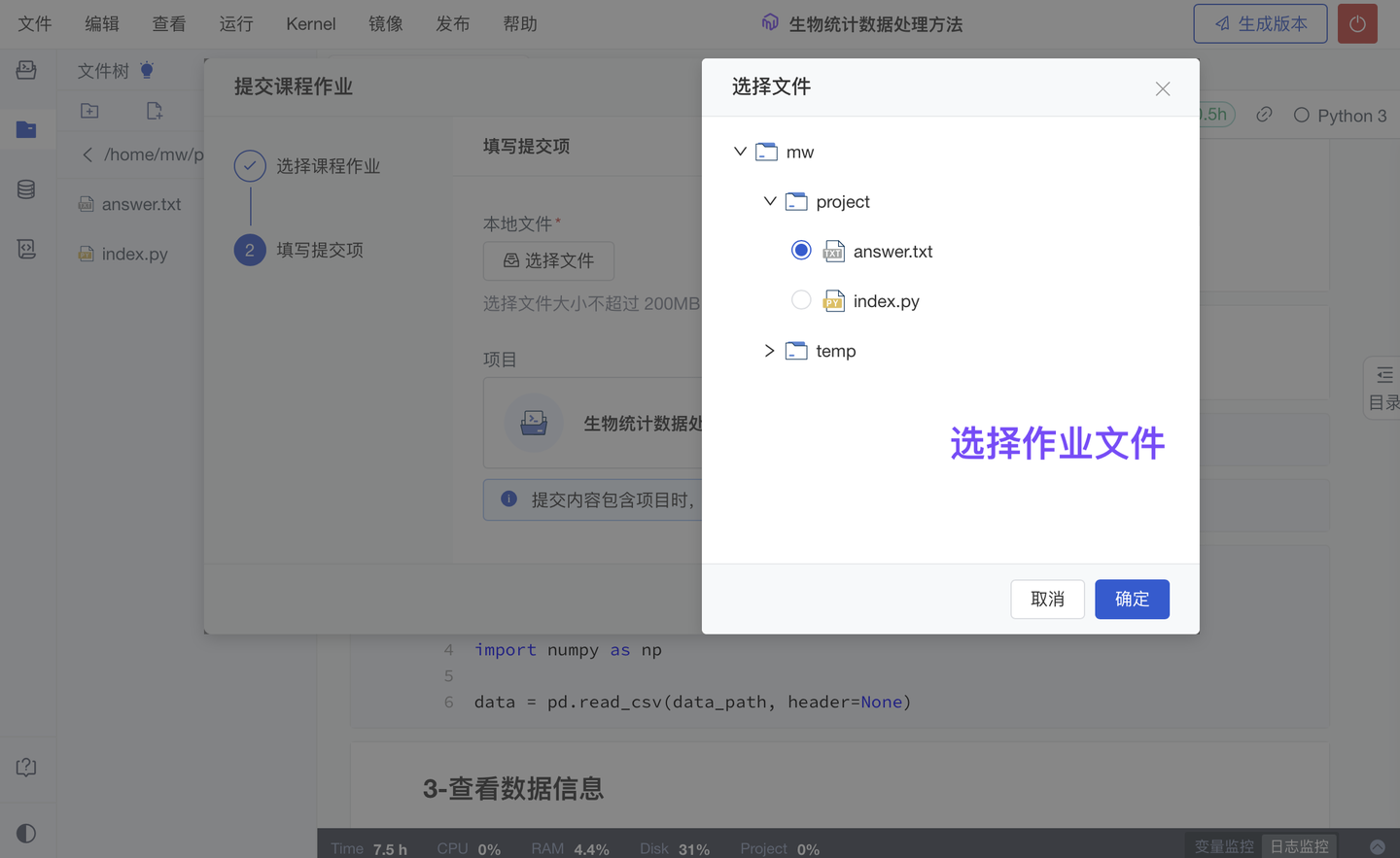
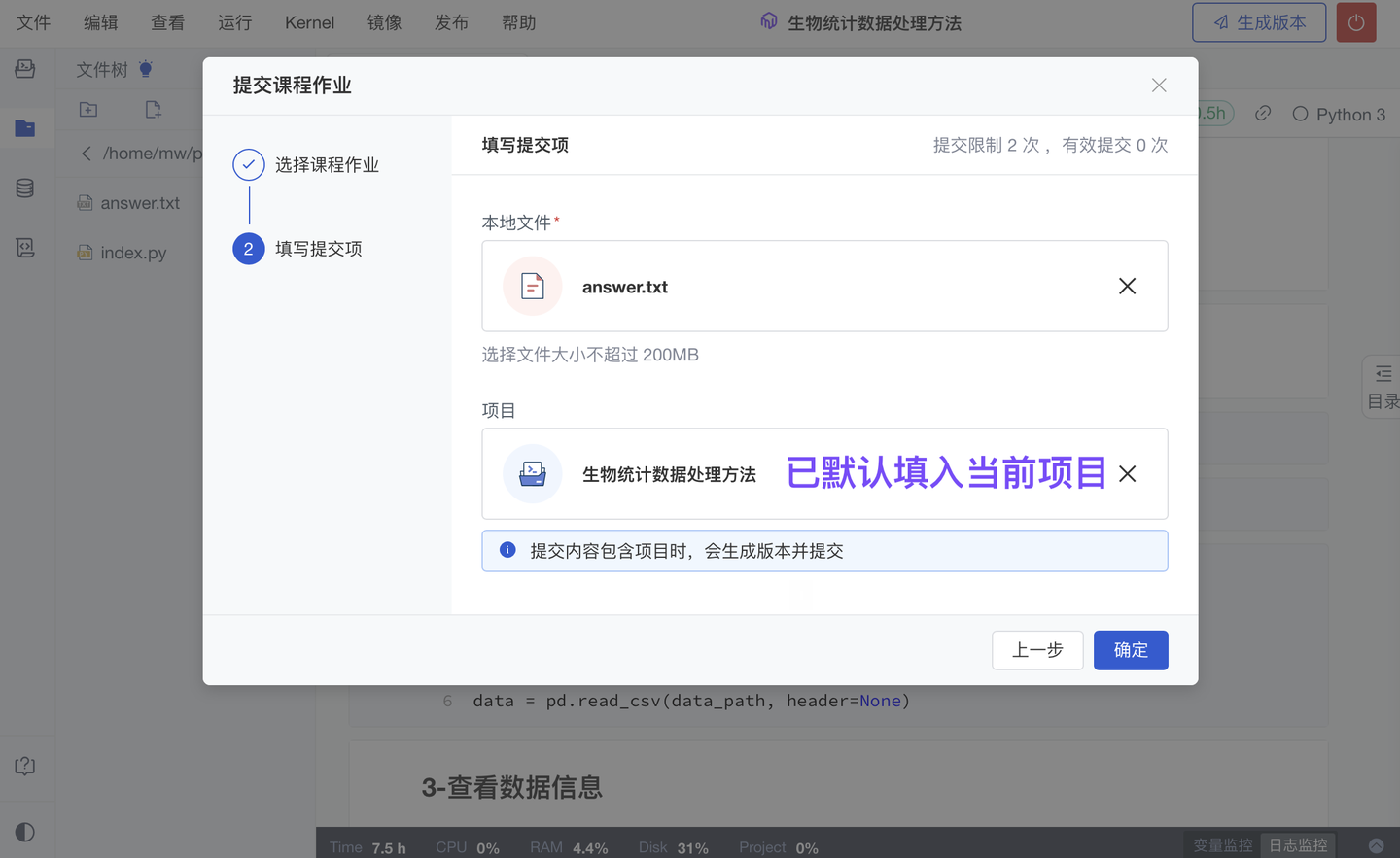
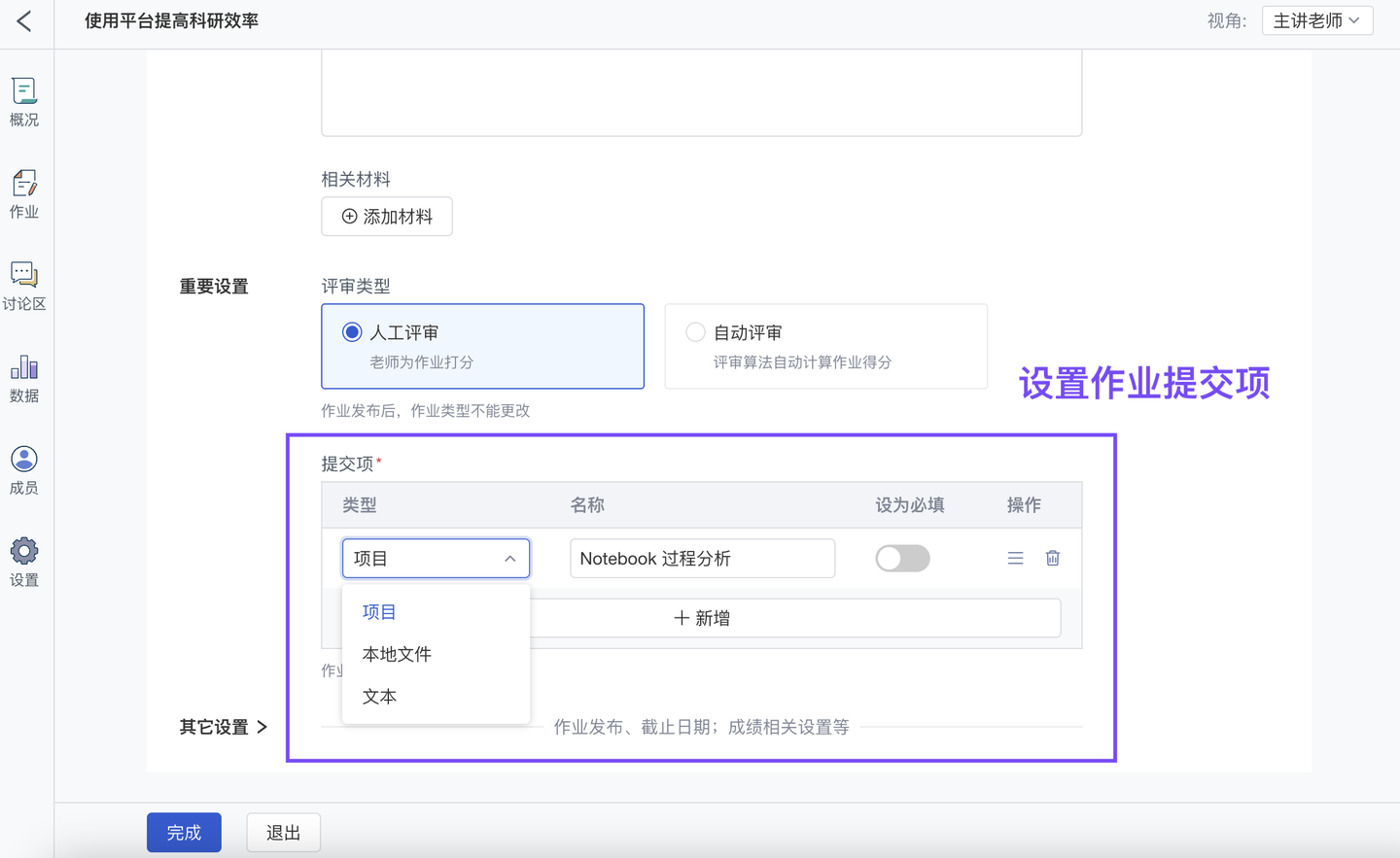
4、新增 作业项必填/非必填设置(团队版✓ )
ModelWhale 教学平台配有用于开展“数据科学实训教学”的作业系统,除支持快捷创建“试卷测验”、“实训作业”、“分组作业”外,还支持老师自定义作业,包括“评审方式(人工评审、自动评审)”、“作业提交项”。其中“作业提交项”支持多种类型,可要求学生提交:在线 Notebook 项目、代码结果文件、本地 PPT 及其他 office 文件、Markdown 文本等,现老师还可以设置这些“提交项”是否“必填”,规范学生的作业提交内容。
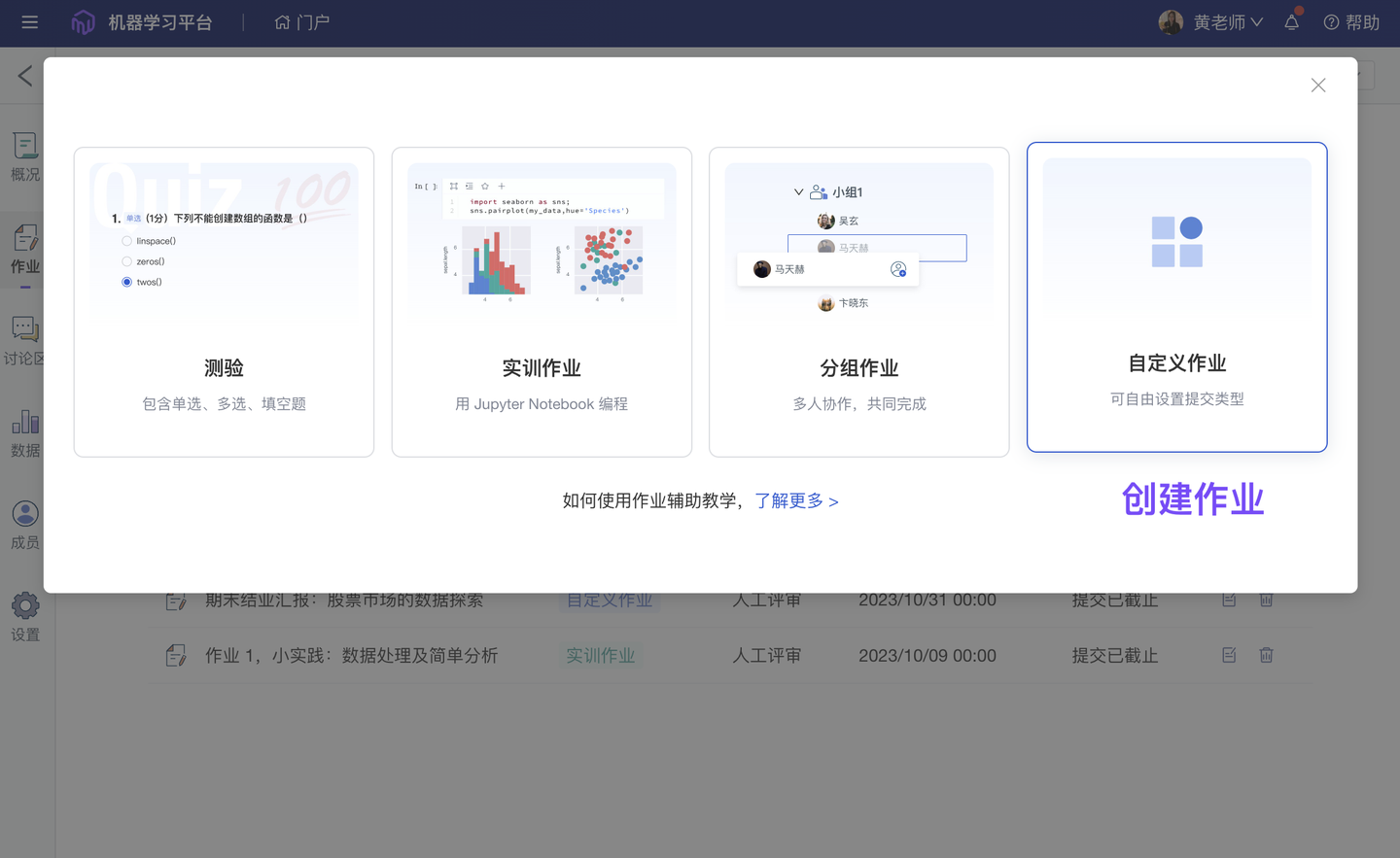
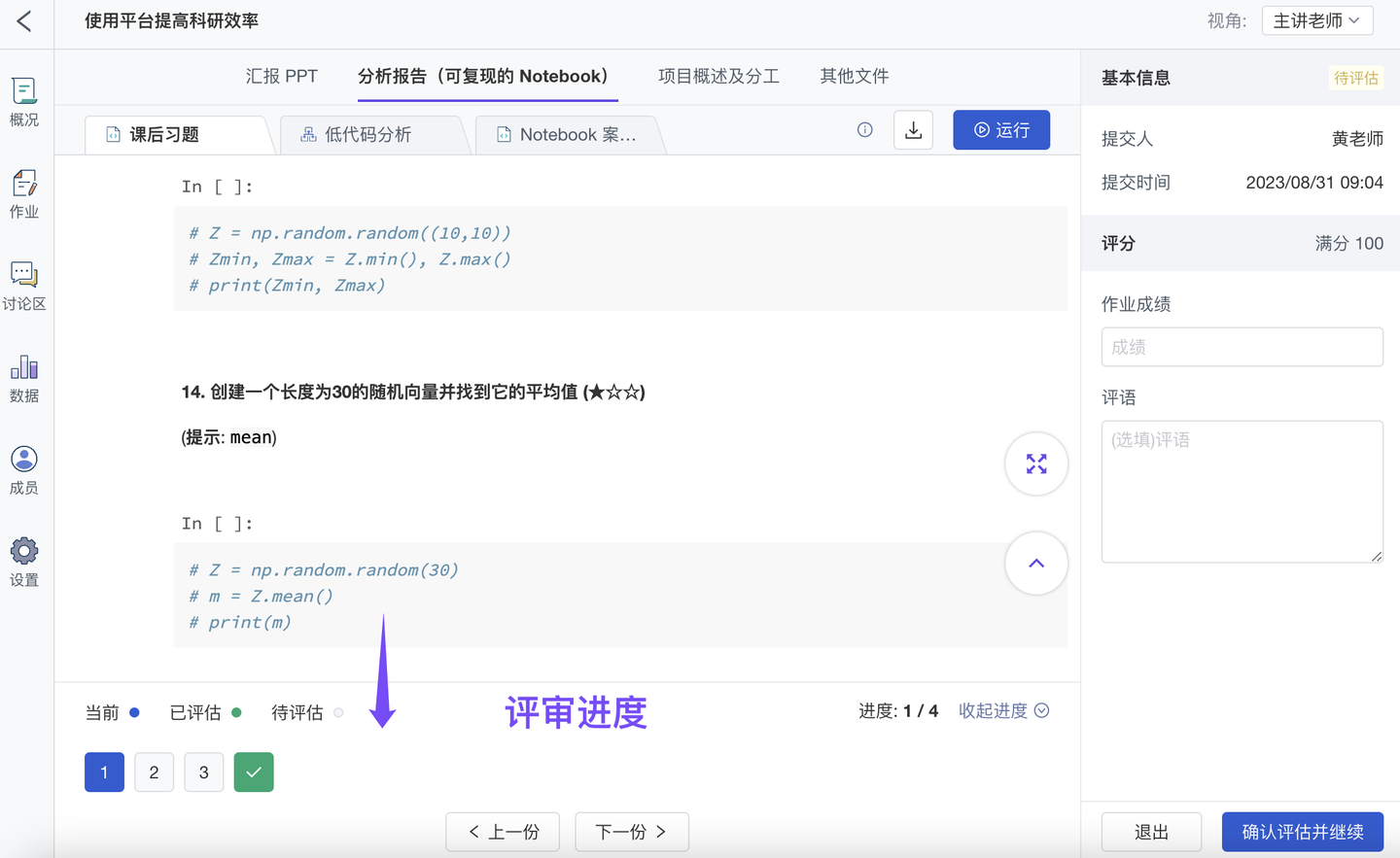
5、新增 作业评阅进度表(团队版✓ )
ModelWhale 教学平台可供老师在线预览、运行、批改学生作业。现新增作业评阅进度表,可供老师随时了解批改进度(哪些作业已评估、哪些未评估)、也支持优先批改/暂不批改的快捷操作。
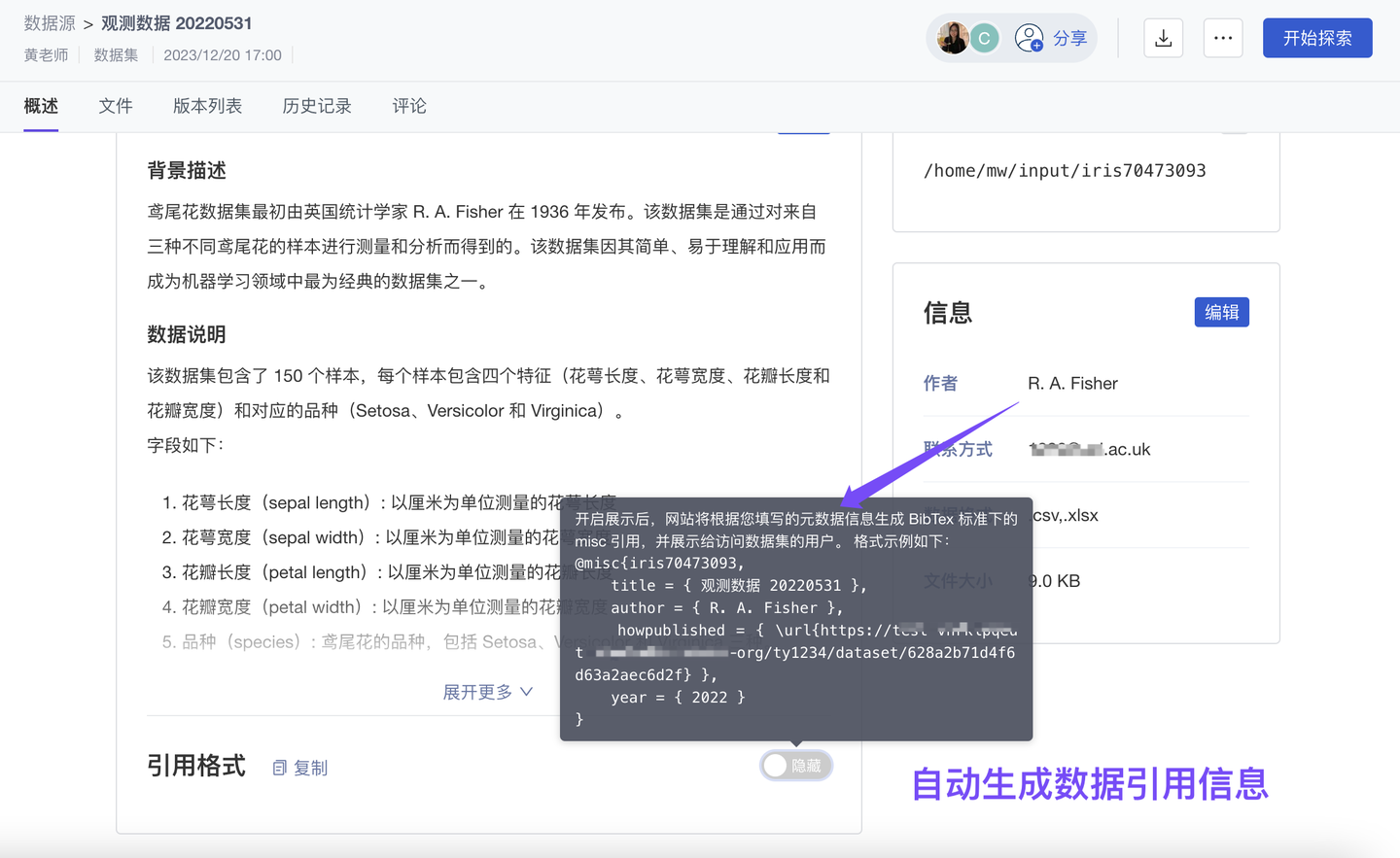
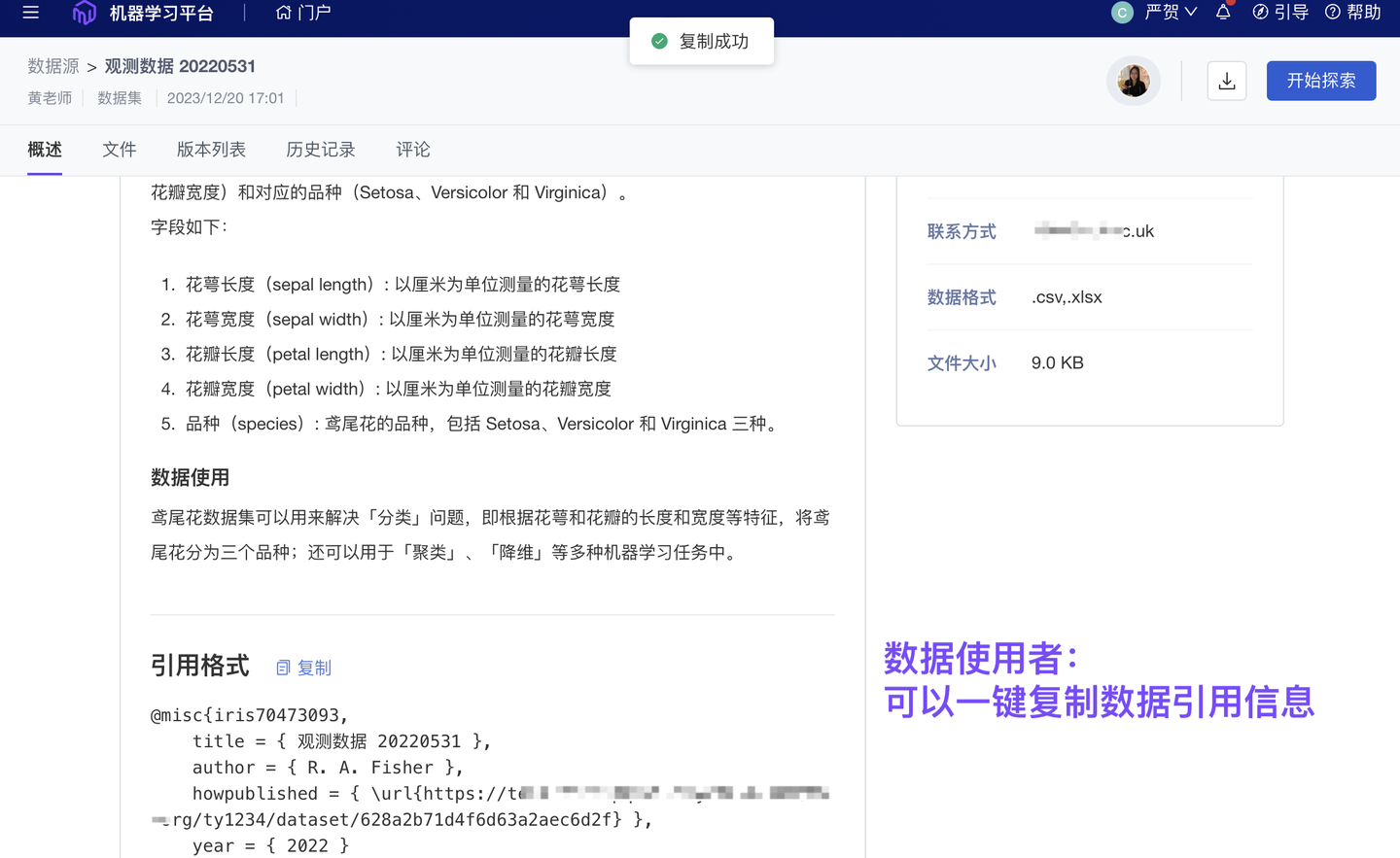
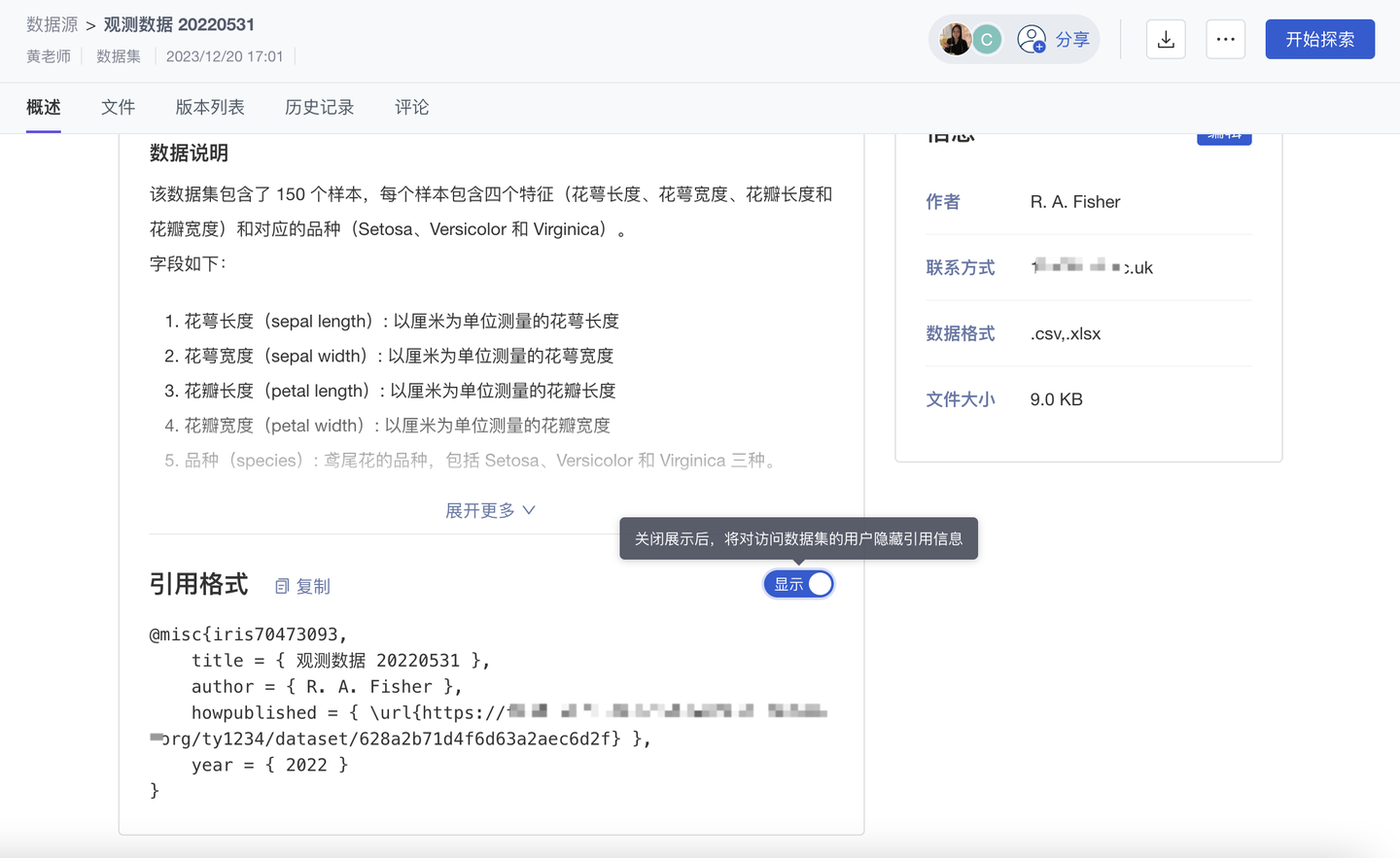
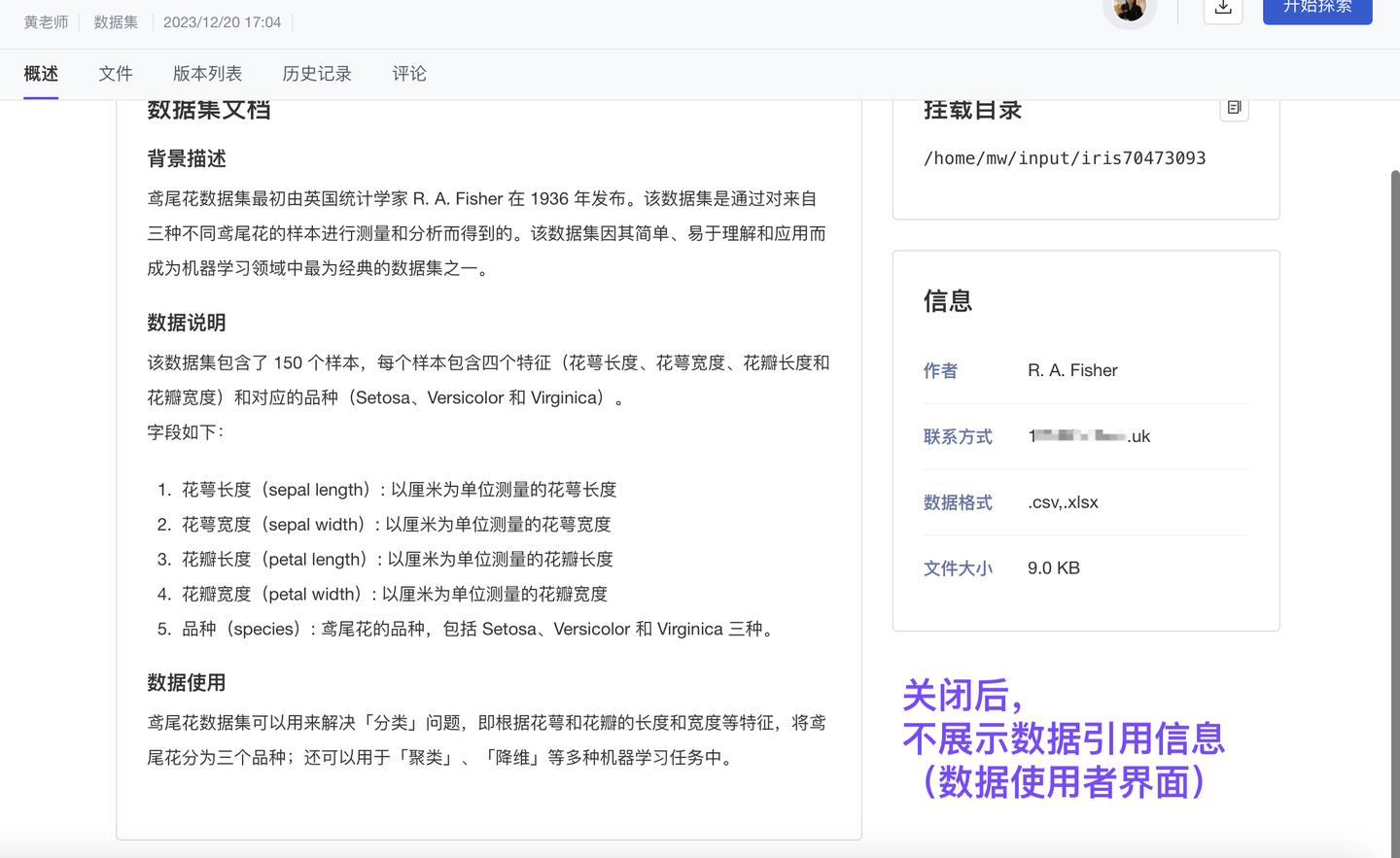
6、优化 数据引用信息自动配置(基础版✓ 专业版✓ 团队版✓ )
为实现科学数据更规范的管理、展示、使用,ModelWhale 应用 FAIR 原则:通过“元数据体系”,保证数据资产的可发现(Findable)、可访问(Accessible)、可互操作(Interoperable)、可重用(Reusable)。我们也支持数据引用信息的自动生成,以便数据使用者可以更便捷、更规范地标记数据来源。
数据创建者打开“引用信息”的展示开关后,ModelWhale 将根据已配置的“元数据信息”自动生成“引用信息”(你无需再二次配置)。
更多详见:ModelWhale 数据引用信息
注:本次更新中,该开关入口由“数据编辑页”调整至“数据详情页”。
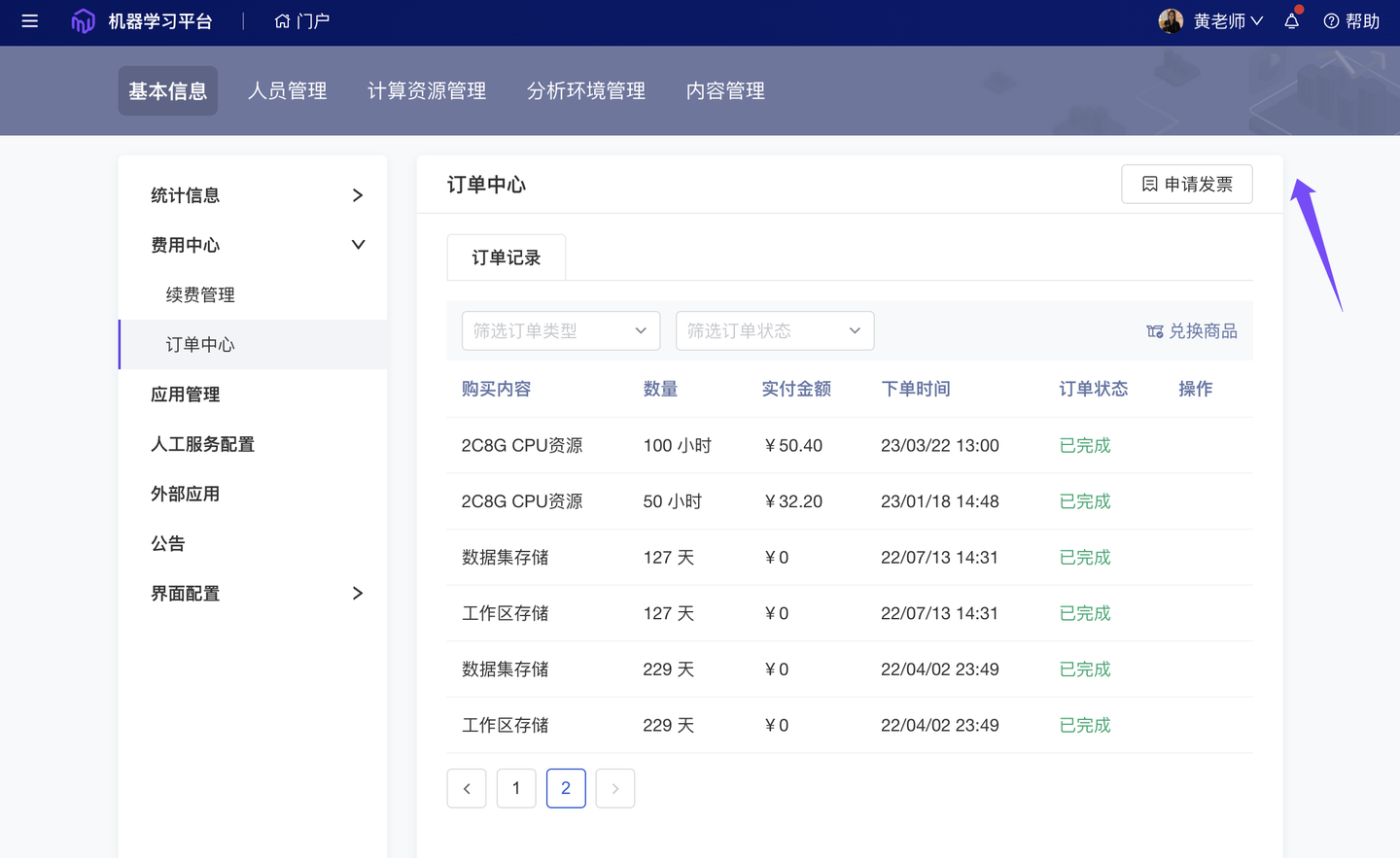
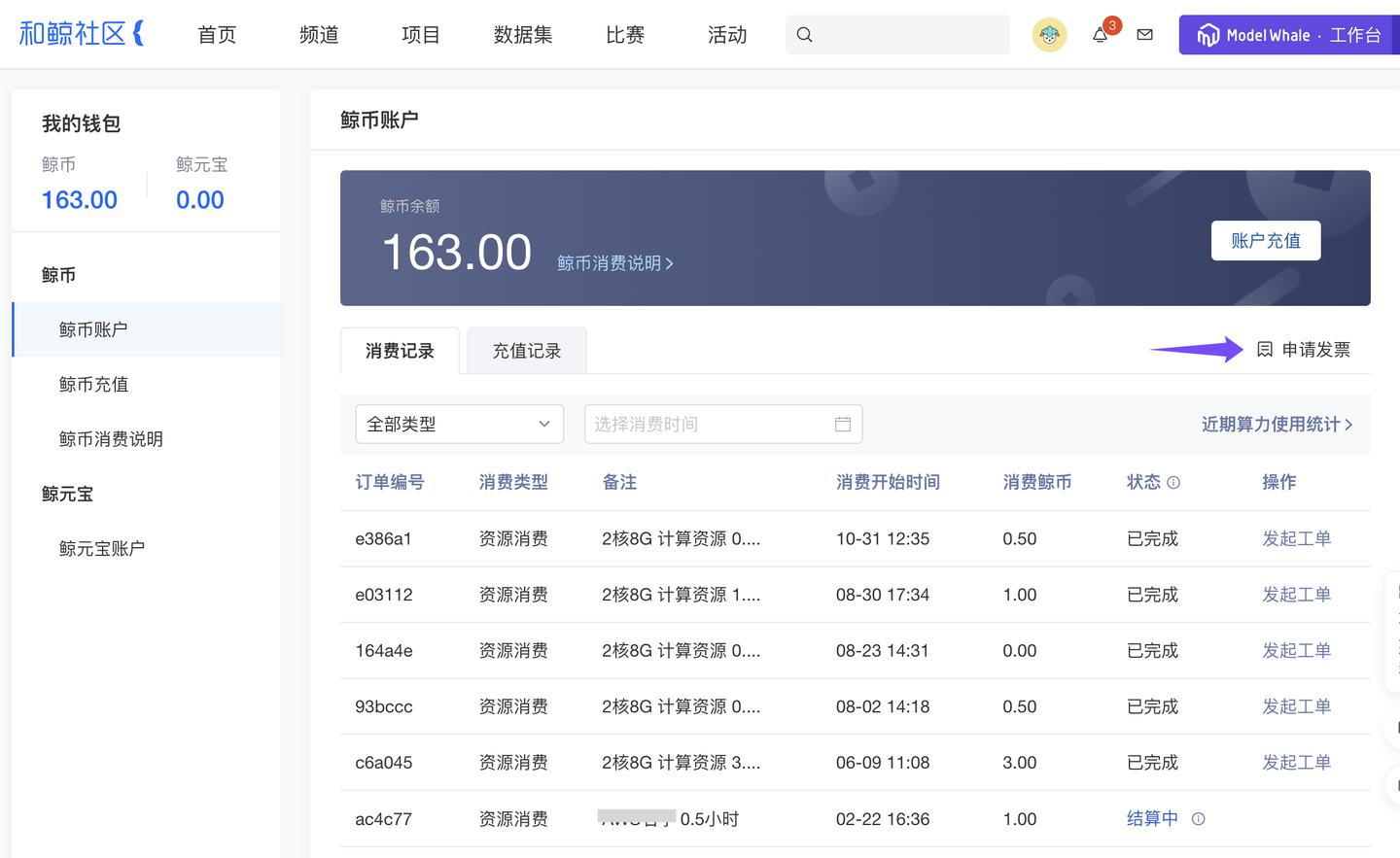
7、优化 在线发票开具(基础版✓ 专业版✓ 团队版✓ )
越来越多来自各行各业的科研人员、企业用户、高校师生选择 ModelWhale 作为数据科学的研究工具、资产管理平台。如在采购 ModelWhale 公有云的功能模块、存储空间、资源算力等服务后,希望开具发票报销,现已支持在线提出开票申请,简化申请流程、提高开票效率。Tips:组织订单、社区鲸币,均支持线上开票。
- 组织订单
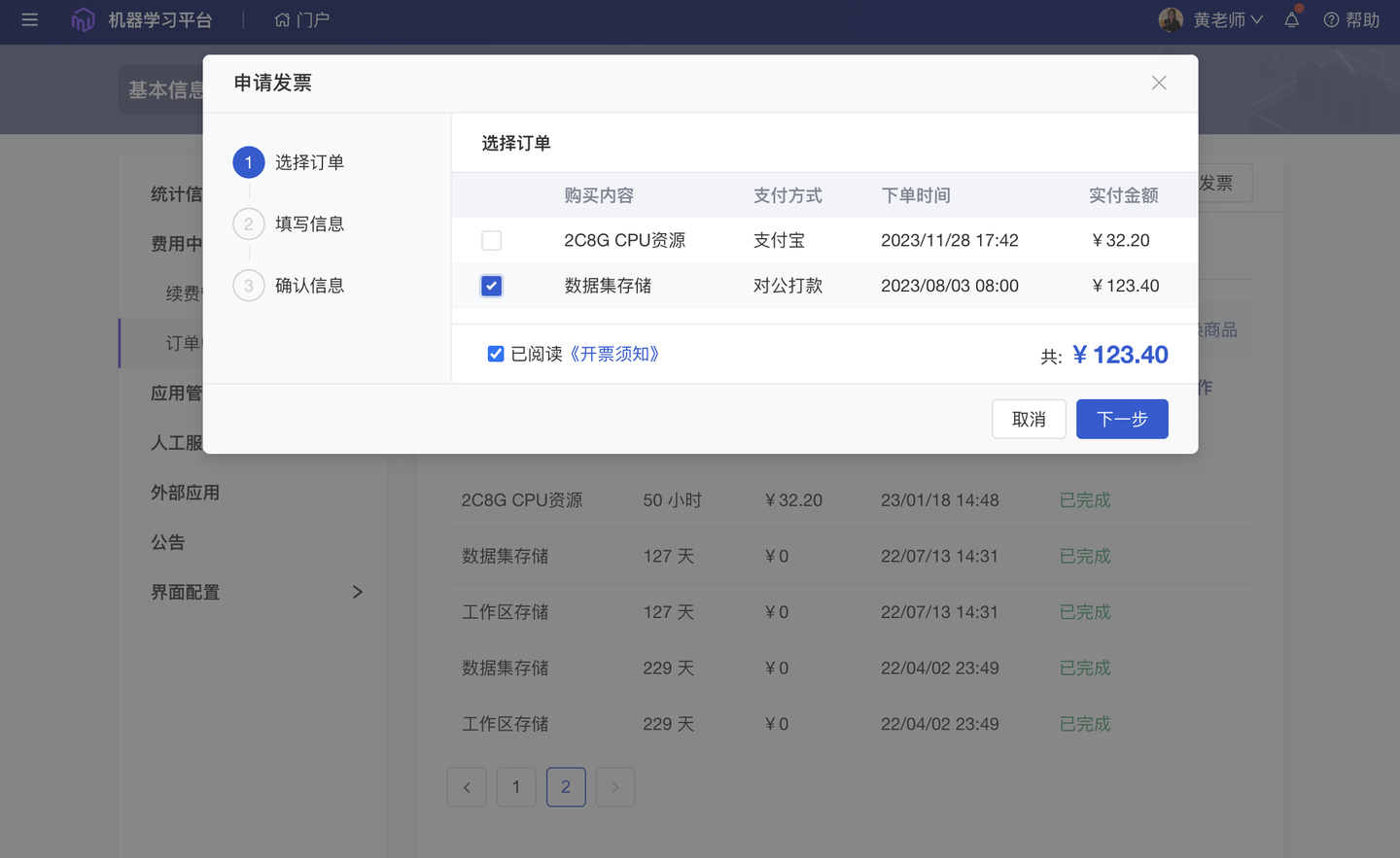
- 社区鲸币
以上,就是本期 ModelWhale 版本更新的全部内容。
进入 Modelwhale 官网,免费试用 Modelwhale 专业版(个人研究)或团队版(组织协同),获赠 CPU、GPU 算力!(建议使用 pc 端体验试用)
若对 ModelWhale 有任何建议、疑问,或有试用续期需求,欢迎点击【联系产品顾问】,MoMo 很高兴为你服务、与你交流(咨询备注“产品咨询”)。

















 751
751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









