



Stable
Diffusion是一种基于Latent
Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-
image)模型。它使用来自LAION-5B数据库子集的512x512图像进行训练。
Stable
Diffusion通过在一个潜在表示空间中迭代“去噪”数据来生成图像,然后将表示结果解码为完整的图像,让文图生成能够在消费级GPU上,在10秒级别时间生成图片,大大降低了落地门槛,也带来了文图生成领域的大火
。

想不想跟随小编对SD进一步研究呢?小编最近研究了Lora模型,发现SD的功能很强大,尤其可以通过真人照片来培养自己的Lora模型,AI会让真人摆出各种姿势、自动换装。
1. 训练模型
选择真人模特的个人各种姿势照片,然后:
1.选择Chilloutmix_safetensors模型
2.文生图输入: The best quality, ultra-high definition, extreme detail, 8k,
realistic, 1 boy, solo, detailed ficial features, detailed eyes and mouth,
delicate facial features, fair skin <lora: clear face smile
boy_20230807224121-Num: STRENGTH>
3.负面提示词输入: Fused fingers, too many fingers, extra arms, extra legs
4.迭代步数选择30
5.脚本选择图示要求,即选择所有的输入图片进行模型训练


点击开始,进行模型训练,因为我们选择了STRENGTH值为0.1, 0.2…0.9,
1,由此生成的模型跟真人的相似度比重不同,同时,我们选择了NUM值为000001, 000002…000009,0000010.因此,会生成十个模型。

2. 全新模特姿势
模型建好后,我们选择其中一个模型,然后通过输入不同的提示词,就可以生成不同姿势的模特啦!




3. 模特换装
输入下图中的换装参数(正面指令:Highest quality, masterpiece, 1boy, clear, green shirt, blue
hair, whole body, <lora: clear face smile boy_20230807224121>;负面指令: low
quality,),可以实现各种模特姿势变化以及换装,如果需要更换指定服装,通过PS的一键换装功能,就可以实现各种姿势的换装啦,有了这个功能,以后就不需要现实模特啦,这种技术是淘宝店主的福音,免去雇佣摄影师和模特的花费,如果大家感兴趣,下次小编给大家做PS一键换装的教程!






总结,SD功能强大,配合相关工具,可以大量节省人力资源,大家一起学起来吧!
AI绘画SD整合包、各种模型插件、提示词、GPT人工智能学习资料都已经打包好放在网盘中了,有需要的小伙伴文末扫码自行获取。
写这篇文章的初衷,网上的Stable Diffusion教程太多了,但是我真正去学的时候发现,没有找到一个对小白友好的,被各种复杂的参数、模型的专业词汇劝退。
所以在我学了之后,给大家带来了腾讯出品的Stable Diffusion新手入门手册
希望能帮助完全0基础的小白入门,即使是完全没有代码能力和手绘能力的设计师也可以完全学得会。
软件从来不应该是设计师的限制,设计师真正的门槛是审美。
需要完整版的朋友,戳下面卡片即可直接免费领取了!
目录

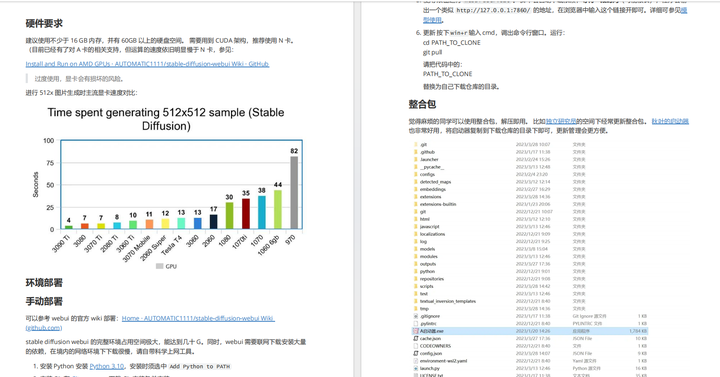
- 硬件要求
- 环境部署
- 手动部署
- 整合包
- …
- 文生图最简流程
- 提示词
- 提示词内容
- 提示词语法
- 提示词模板
- …
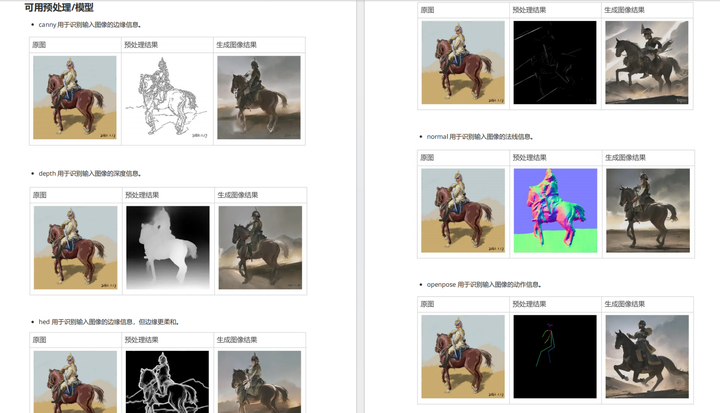
- Controlnet
- 可用预处理/模型
- 多ControlNet合成
- …
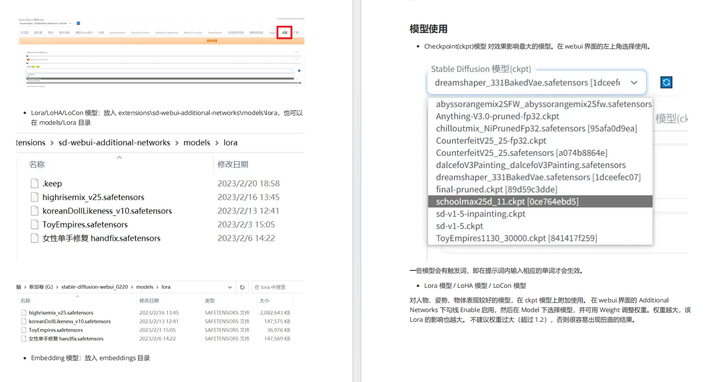
- 模型下载
- 模型安装
- 模型训练
- …
- 训练流程
- 风格训练
- 人物训练
- …
需要完整版的朋友,戳下面卡片即可直接免费领取了!


















 3362
3362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









