




 本文探讨了机器学习中特征缩放的重要性,详细解释了归一化和标准化两种常见方法。归一化通过最大最小值将特征值缩放到[0,1]区间,加速算法收敛并消除量纲影响;标准化则通过平均值和标准差调整特征分布,使其符合标准正态分布。两者在不同场景下各有优势。
本文探讨了机器学习中特征缩放的重要性,详细解释了归一化和标准化两种常见方法。归一化通过最大最小值将特征值缩放到[0,1]区间,加速算法收敛并消除量纲影响;标准化则通过平均值和标准差调整特征分布,使其符合标准正态分布。两者在不同场景下各有优势。
一. 为什么需要特征缩放
对于大多数的机器学习算法和优化算法来说,将特征值缩放到相同区间可以使得获取性能更好的模型。就梯度下降算法而言,例如有两个不同的特征,第一个特征的取值范围为1-10,第二个特征的取值范围为1-10000。在梯度下降算法中,代价函数为最小平方误差函数,所以在使用梯度下降算法的时候,算法会明显的偏向于第二个特征,因为它的取值范围更大。再比如,k近邻算法,它使用的是欧式距离,也会导致其偏向于第二个特征。
常用的特征缩放算法有两种,归一化(normalization)和标准化(standardization)。
二. 归一化(normalization)
1. 什么是归一化
归一化是利用特征的最大值,最小值,将特征的值缩放到[0,1]区间,对于每一列的特征使用min - max函数进行缩放。
2. 为什么需要归一化
- 消除纲量,加快收敛
不同特征往往具有不同的量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据归一化处理,以解决数据指标之间的可比性。原始数据经过数据归一化处理后,各指标处于[0,1]之间的小数,适合进行综合对比评价。 - 提高精度
3. 归一化的方法
-
线性归一化
利用数据集每个特征的最大值,最小值,将特征的值缩放到[0,1]区间:
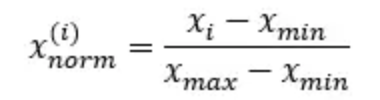
我们发现,如果数据集确定,那么max(x)与min(x)就是固定值,那么线性归一化本质上就是一个压缩和平移的过程。 -
非线性归一化
经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括 log、指数,正切等。需要根据数据分布的情况,决定非线性函数的曲线,比如log(V, 2)还是log(V, 10)等。
三. 标准化(standardization)
1. 什么是标准化
标准化是通过特征的平均值和标准差,将特征缩放成一个标准的正态分布,缩放后均值为0,方差为1。但即使数据不服从正态分布,也可以用此法。特别适用于数据的最大值和最小值未知,或存在孤立点。
2. 为什么要标准化
标准化是为了方便数据的下一步处理,而进行的数据缩放等变换,不同于归一化,并不是为了方便与其他数据一同处理或比较。
3. 标准化的方法
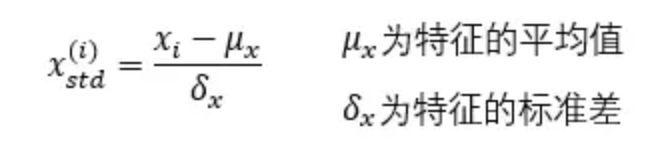
四. 归一化与标准化的区别
目的不同,归一化是为了消除纲量压缩到[0,1]区间;标准化只是调整特征整体的分布。
归一化与最大,最小值有关;标准化与均值,标准差有关。
归一化输出在[0,1]之间;标准化无限制。

















 870
870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









