







 旷视研究院在ICCV 2019提出VANet,这是一种具备视角感知力的车辆重识别网络,能有效解决因视角变化导致的性能下降问题。VANet采用两个独立的深度度量学习分支,分别处理相似和不同视角关系,通过空间内和跨空间约束提升重识别精度。
旷视研究院在ICCV 2019提出VANet,这是一种具备视角感知力的车辆重识别网络,能有效解决因视角变化导致的性能下降问题。VANet采用两个独立的深度度量学习分支,分别处理相似和不同视角关系,通过空间内和跨空间约束提升重识别精度。

两年一度的国际计算机视觉大会 ICCV 2019 ( IEEE International Conference on Computer Vision) 将于当地时间 10 月 27 至 11 月 2 日在韩国首尔举办。旷视研究院本次大会接收论文主题涵盖通用物体检测及数据集、文字检测与识别、半监督学习、分割算法、视频分析、影像处理、行人/车辆再识别、AutoML、度量学习、强化学习、元学习等众多领域。在此之前,旷视研究院将每周介绍一篇 ICCV 2019 接收论文,助力计算机视觉技术的交流与落地。
本文是第 9 篇,旷视研究院提出具备视角感知力的车辆重识别网络 VANet,它可以克服因被拍摄车辆的视角变化过于巨大所造成的性能严重的削弱问题。

论文名称:Vehicle Re-identification with Viewpoint-aware Metric Learning
论文地址:https://arxiv.org/abs/1910.04104
目录
导语
简介
方法
-
度量学习baseline
具备视觉感知力的度量学习方法
网络架构
实验
讨论
结论
参考文献
往期解读
导语
车辆重识别(Vehicle re-ID)任务旨在匹配城市管理场景中不同监控视角之下的车辆,其对公共安全和智慧交通而言意义重大。目前,车辆重识别任务面临的主要挑战是视角变化问题。
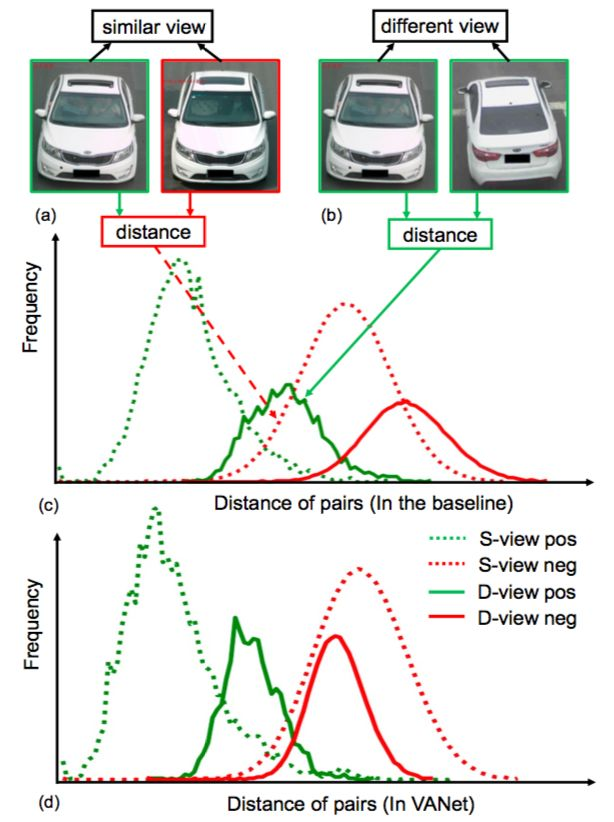
图 1:Vehicle re-ID 多视角图示
如图 1 所示,不同的两辆车从相似视角观察,视觉信息可能非常相似(图 1(a));而同一辆车,从不同视角看,视觉信息却差异较大(图 1(b))。
出于方便考虑,本文使用 S-view 表示相似视角 (similar-viewpoint),D-view 表示不同视角 (different-viewpoint)。在物体识别领域,视角变化问题在一些任务中(如行人重识别和人脸识别)已经多有研究。尽管深度度量学习已经在获取视角变化特征方面取得了一定成功,但是车辆的视角变化非常极端(往往能达到180度),极端视角变化的问题依然充满挑战。
本文用一个深度度量学习的 baseline 做了实验,D-view pos(具有不同视角的同类样本对) 和 S-view neg(具有相似视角的不同类样本对) 的距离分布如图 1(c)所示。经过统计,相较于 S-view neg,D-view pos 的距离往往要更大,这严重降低了重识别的检索精度。
简介
旷视研究院通过学习具备视角感知力(viewpoin
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 308
308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









