






前言
在并发编程中,你是否曾困惑为何简单的 a++ 在多线程环境下频繁出错?C++ 的原子操作背后究竟隐藏着怎样的硬件级秘密?当面对四种类型转换时,你是否清楚何时该用 dynamic_cast 而非 static_cast?
本文将带你深入 C++ 的核心机制,从 std::atomic 如何通过一条 CPU 指令实现线程安全,到函数指针如何成为回调机制的基石;从 const 与 extern 对链接属性的微妙影响,到 nullptr 如何彻底解决 NULL 的历史遗留问题。
无论你是希望优化多线程性能,还是需要深入理解类型系统的安全边界,这些底层原理都将为你打开 C++ 高性能编程的新视野。让我们从汇编层面开始,一起揭开这些机制的神秘面纱。


目录
9. C++中如何使用sizeof操作符获取变量或类型的大小?
1. std :: atomic
- 问题:a++ 和 int b=a 在C++中是否是线程安全的?
- 答案:不是
我们来分别进行分析,
例1:
a++,从代码语句层面应该是原子的;但是从汇编层面得到的指令并不是原子的。
其一般对应三条指令,首先将变量a对应的内存搬运到某个寄存器(如eax)中,然后将该寄存器中的值自增1,再将该寄存器中的值搬回a的内存中:
mov eax, dword ptr [a] # (1)/(4)
inc eax # (2)/(5)
mov dword ptr [a], eax # (3)/(6)
我们假设 a 的值为0,现在有两个线程,每一个线程都对变量 a 进行++,我们想要的结果可能是2,但实际上运行的结果是1,这是为什么的?
int a = 0;
// 线程1(执行过程对应上文汇编指令(1)(2)(3))
void thread_func1() {
a++;
}
// 线程2(执行过程对应上文汇编指令(4)(5)(6))
void thread_func2() {
a++;
}
我们的期望可能是上面线程1和线程2的三条指令各自执行,最后得到结果为2,但是由于操作系统的线程调度的不确定性,线程1执行完(1)(2)后,eax寄存器中的值变为1,但此时线程切换回了线程2,执行指令(3)(4)(5),此时寄存器eax的值依然是1;紧接着操作系统有切换回线程1,执行指令6,得到最终的结果1。
例2:
从C/C++语法层面看,int a = b 这一条语句应该是原子的;但是从汇编得到的汇编指令来看,这条语句会对应两条指令:
mov eax, dword ptr [b]
mov dword prt [a], eax
那么同样因为操作系统在线程调度的不确定性,会导致线程不安全。
解决办法:
C++11新标准颁布之后就能够解决这一系列问题,提供了一个对整型变量原子操作的相关库,即std::atomic,这是一个模板类型:
template<class T>
struct atomic:
int a = 0; // 普通int
std::atomic<int> b = 0; // 原子int
a++; // 编译器可能生成非原子指令
b++; // 编译器必须生成原子指令(如lock xadd)
//汇编指令如下:
// 普通int自增(非原子)
mov eax, [counter] // 读取
inc eax // 加1
mov [counter], eax // 写回
// 可能被其他线程打断!
// 原子int自增
lock xadd [counter], 1 // 一条指令完成:锁定总线→读取→加1→写回
// 不会被其他线程打断!简单来说,std::atomic的作用就是强制使用硬件的原子指令,从而实现多线程安全。
其次还有一点就是,如果使用atomic模板类,初始化行为应该注意:
// 初始化1
std::atomic<int> value;
value = 99;
// 初始化2
// 下面代码在Linux平台上无法编译通过(指在gcc编译器)
std::atomic<int> value = 99;
// 出错的原因是这行代码调用的是std::atomic的拷贝构造函数
// 而根据C++11语言规范,std::atomic的拷贝构造函数使用=delete标记禁止编译器自动生成
// g++在这条规则上遵循了C++11语言规范。
2. 什么是函数指针,如何定义,以及其使用场景
函数指针是指向函数的指针变量。可以用来存储函数的地址,允许在运行时动态选择要调用的函数。
// 返回类型 (*指针变量名)(参数列表)
int add(int a, int b) {
return a + b;
}
int subtract(int a, int b) {
return a - b;
}
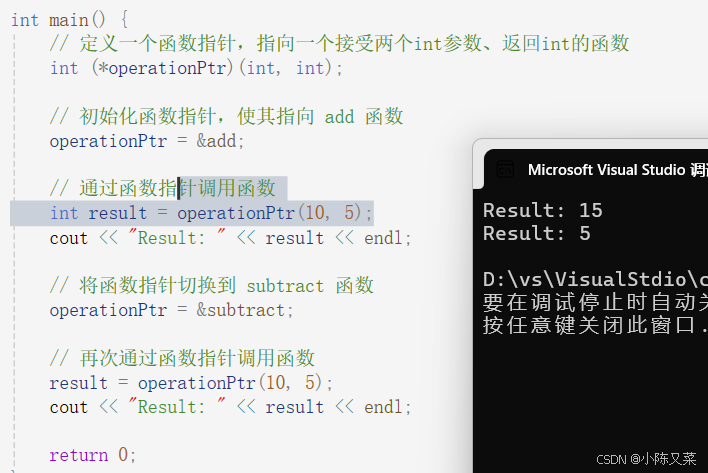
int main() {
// 定义一个函数指针,指向一个接受两个int参数、返回int的函数
int (*operationPtr)(int, int);
// 初始化函数指针,使其指向 add 函数
operationPtr = &add;
// 通过函数指针调用函数
int result = operationPtr(10, 5);
cout << "Result: " << result << endl;
// 将函数指针切换到 subtract 函数
operationPtr = &subtract;
// 再次通过函数指针调用函数
result = operationPtr(10, 5);
cout << "Result: " << result << endl;
return 0;
}
使用场景:
- 回调函数:函数指针常用于实现回调机制,允许将函数的地址传递给其他函数,以便在适当的时候调用。
- 函数指针数组:可以使用函数指针数组来实现类似于状态机的逻辑,根据不同的输入来调用不同的函数。
- 动态加载库:函数指针可用于在运行时动态加在库中的函数,实现动态链接库的调用。
- 多态实现:在C++中,虚函数和函数指针结合使用,可以实现类似于多态的效果。
- 函数指针作为参数:可以将函数指针作为参数传递给其他函数,实现一种可插拔的函数行为。
- 实现函数映射表:在一些需要根据某些条件调用不同的函数情况下,乐意使用函数指针来实现函数映射表。
3. 函数指针和指针函数的区别
- 函数指针是一个指向函数的指针变量,用来存储函数的地址,并在运行时动态选择要调用的函数。常用于回调函数、动态加载库时的函数调用等场景:
int add(int a, int b) {
return a + b;
}
int (*ptr)(int, int) = &add; // 函数指针指向 add 函数
int result = (*ptr)(3, 4); // 通过函数指针调用函数
- 指针函数是一个返回指针类型的函数,用于返回指向某种特定数据类型的指针:
int* getPointer() {
int x = 10;
return &x; // 返回局部变量地址,不建议这样做
}
4. struct和Class
相同点:
- 如果结构体没有定义任何构造函数,编译器会自动生成一个默认的无参构造函数;同样地,如果类没有定义任何的构造函数,编译器也会生成一个默认的无参构造函数。
不同点:
- struct用来表示一组相关的数据;Class用来表示一个封装了数据和相关操作的对象
- struct结构体中的成员默认是公有的(public);Class类中的成员默认是私有的(private)
- struct继承时默认使用公有继承;Class继承时默认使用私有继承
// 使用 struct 定义
struct MyStruct {
int x; // 默认是 public
void print() {
cout << "Struct method" << endl;
}
};
// 使用 class 定义
class MyClass {
public: // 如果省略,默认是 private
int y;
void display() {
cout << "Class method" << endl;
}
};
5. C++强制类型转换
关键字:static_cast、dynamic_cast、reinterpret_cast、const_cast
5.1. static_cast
没有运行时类型检查来保证转换的安全性。
- 进行上行转换(把派生类的指针或者引用转换成基类表示)是安全的
- 进行下行转换(把基类的指针或者引用转化成派生类表示),由于没有动态类型检查,所以是不安全的
5.2. dynamic_cast
在进行下行转换时,dynamic_cast具有类型检查(信息在虚函数中)的功能,相较于static_cast更加安全。
- 转换后必须是类的指针、引用或者void*,基类要有虚函数,可以交叉转换
- dynamic本身只能用于存在虚函数的父子关系的强制类型转换;对于指针,转换失败返回nullptr,对于引用,转换失败会抛出异常
5.3. reinterpret_cast
- 可以将整型转换为指针,也可以将指针转化为数组
- 可以在指针和引用之间肆无忌惮地进行转换,平台移植性价比差
5.4. const_cast
常量指针转换为非常量指针,并且依然指向原来的对象。常量引用被转换为非常量引用,并且依然指向原来的对象。
这个地方解释一下这句话,使用const_cast进行类型转换:
- 对于常量指针:使得指针能够修改指向
- 对于指针常量:使得能够通过指针修改指向的值
- 对于常量引用:使得能够通过引用修改引用的值
6. 请解释C++中const关键字的作用,并给出使用场景
回答:
- 修饰普通变量时:表示该变量的值不能被修改
- 修饰指针时,分为两种情况:
- const int * 代表指针常量,则不能通过该指针修改指向的值
- int * const 代表常量指针,则该指针不能改变指向
- 修饰函数时:const修饰函数是C++的一个扩展,目的是为了保证类的封装性。使用const修饰类的成员函数,该函数不能修改该类的成员变量
- 修饰函数传参事:修饰的参数在函数内不能被修改
7. 解释一下C++中extern关键字的作用
简要回答:
在C++中,extern关键字主要用于声明全局变量或函数,告知编译器这些变量或函数的定义位于其他文件中,从而实现跨文件共享。
- 为了避免重复定义:一般在某个源文件中定义全局变量,在其他文件中声明(使用extern)
- 特殊注意的地方:
如果是一个普通全局变量
// 文件A:
int g_value = 100; // 这是定义
//extern int g_value; 定义的时候加不加都可以
// 文件B:
extern int g_value; // 这是声明如果是const全局变量(特殊)
// 文件A:(必须加extern!)
extern const int MAX_SIZE = 1024; // const全局变量定义要加extern
// 文件B:
extern const int MAX_SIZE; // 声明这是因为,const修饰全局变量默认是内部链接属性!!!
- C++与C混合编程:
// C++文件中使用C库的全局变量
extern "C" {
extern int c_global_var; // 来自C文件的变量
}详细回答:
- 声明全局变量(不分配内存)
- 语法、关键点
// 文件A.cpp
int x = 10; // 定义全局变量x(分配内存)
// 文件B.cpp
extern int x; // 声明x,链接到A.cpp中的定义
void func() {
x = 20; // 使用A.cpp中定义的x
}
声明仅告知变量类型和名称,定义才会分配内存。多个声明是合法的,但是多个定义会导致链接错误。
- 函数的隐式extern
- 函数(全局函数)声明默认带有extern,无须显式写出
- 使得函数在整个程序中可见,也可以被其他文件调用
知识扩展:
- 头文件中不要有extern的定义(避免重复定义):因为头文件可能会被多个源文件包含
- 模板与extern:显示实例化声明
// 声明:告知编译器某个模板实例已在其他文件中定义
extern template class std::vector<int>;
// 定义(另一个文件中)
template class std::vector<int>;
这样的作用是,减少编译时间(避免重复实例化),常用于大型项目
常见面试问题:
- Q1:extern int x ; 和 int x ; 的区别?
- A1:前者是声明,不分配内存,需要链接其他文件的定义;后者是定义,会分配内存
- Q2:如何在C++中调用C函数
- A2:
// 方式1:直接声明
extern "C" void c_function(int);
// 方式2:包含C头文件
extern "C" {
#include <cstdio> // 例如调用printf
}
- Q3:extern和static的关系
- A3:前者使变量或者函数具有外部链接属性(跨文件可见);后者使变量或者函数具有内部链接属性(仅当前文件可见)
8. 请描述C++中的static在不同场景下的作用
简要回答:
- 局部变量:添加static会使得变量的生命周期延长至程序结束,单作用域只是在函数内部,并且只会初始化一次
- 全局变量/函数:将作用域限制为当前文件(因为默认是extern的),避免被其他文件通过extern使用
- 类成员变量/函数:使得其属于类而不是对象实例,所有对象共享一份静态成员,可以通过类名访问
这里补充一些概念:
- 静态与常量的区别:
- static强调存储位置和作用域;const强调不可修改
- 静态常量需要在类内声明,类外初始化,但是普通常量可以直接在类进行初始化
- 静态对象的析构:静态对象的析构函数在程序结束时自动调用,顺序与构造时相反
- 线程安全问题:C++11起,静态局部变量的初始化是线程安全的(即多个线程首次调用函数式时,静态变量只会被初始化一次)
- 静态成员和模板:类模板的静态成员会为每一个实例化的模板类型单独生成一份实例
template<typename T>
class MyClass {
public:
static int count; // 静态成员
};
// 为不同的类型实例化:
MyClass<int> obj1; // 有 MyClass<int>::count
MyClass<double> obj2; // 有 MyClass<double>::count(这是另一个变量!)
MyClass<string> obj3; // 有 MyClass<string>::count(这又是另一个变量!)
// 这三个count是完全不同的变量!9. C++中如何使用sizeof操作符获取变量或类型的大小?
sizeof是C++肿的编译时一元操作符,用于获取变量或类型所占用的字节数。其核心特点如下,
- 语法:
sizeof(type); // 获取类型大小(括号必需)
sizeof(expression); // 获取表达式结果类型的大小
sizeof var; // 获取变量大小(括号可选)
- 返回值:std :: size_t 类型的无符号整数
- 编译期计算:不执行表达式,仅分析类型
- 常见用途:内存分配、数组遍历、跨平台兼容性
补充知识点:
sizeof与表达式
- 不执行表达式:
int func() { return 42; }
sizeof(func()); // 4字节(int类型大小),但不会调用func()
- 引用类型:
int x = 10;
int& ref = x;
sizeof(ref); // 4字节(引用类型的大小等于被引用类型的大小)
- 空类/结构体:
struct Empty {};
sizeof(Empty); // 1字节(C++要求每个对象有唯一地址)
sizeof的局限性
- 动态数组:
int* arr = new int[10];
sizeof(arr); // 8字节(指针大小),而非40字节
- 函数参数中的数组:
void func(int arr[]) {
sizeof(arr); // 8字节(数组退化为指针)
}
常见面试陷阱:
- Q1:sizeof是一个函数还是操作符?
- A1:操作符,编译期计算,不产生运行时代码
- Q2:如何获取动态数组的大小?
- A2:无法通过sizeof获取,必须手动管理
- Q3:以下代码输出什么?
int arr[10];
void func(int arr[]) {
cout << sizeof(arr) << endl;
}
int main() {
cout << sizeof(arr) << endl;
func(arr);
return 0;
}
- A3:输出40和8(假设64位系统),main中arr是数组,func中退化成指针
10. 请解释C++中nullptr和NULL的区别
-
类型上的区别:
- nullptr是C++引入的关键字,表示一种特殊的空指针类型,具体为std :: nullptr_t 线程安全类型,这种类型可以隐式转换成任何类型的指针
- NULL是一个宏定义,通常定义为0或者(void*)0,它的本质还是一个整数常量,可以隐式转换成指针类型,但是可能引发分歧
void func(int );
void func(int *);
int main()
{
func(NULL); // 调用 func(int),因为 NULL 是整数,但是此时NULL可能存在为二义性
func(nullptr); // 调用 func(int*),因为 nullptr 是指针类型
return 0;
}
| 特性 | nullptr | NULL |
|---|---|---|
| 定义 | C++11新增关键字 | 宏,通常为表示整形为0 |
| 类型 | std::nulltpr_t | 整数常量 |
| 类型安全性 | 强 | 弱 |
| 转换为整数 | 不可以 | 可以 |
| 推荐使用 | 是 | 不是 |



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









