



引言
去年年初,特斯拉率先上线端到端技术,这一动作迅速引发全行业跟进热潮,直接推动城市领航辅助功能在新车型中实现规模化普及。
刷到理想、小鹏的新车宣传里反复提“VLA”?刷到机器人能精准执行“把水杯放桌上”的指令?这个听起来很技术的词,其实藏着未来生活的密码。今天用大白话拆解VLA:它到底是什么、能做什么,又会带我们走向何方?


【VLA不是黑科技,是会思考的执行者】
VLA的全名叫“视觉-语言-动作模型”,光看名字就知道它的核心能力——把“看得到”“听得懂”变成“做得对”,像给机器装了“眼睛+大脑+手脚”。

打个比方,传统自动驾驶像只会执行固定指令的机器人,而VLA更像能灵活应变的司机:看到前方施工(视觉),听懂导航说“绕行”(语言),立刻减速变道(动作),全程不用人操心,还会告诉你“因为前方施工,正在变更车道”。
不少人好奇:VLA 加 “语言” 这一步,到底图啥?
其实答案藏在传统端到端架构的一个短板里 ——它的 “心思” 太难猜了。你能看到它最终做出的决策,比如 “减速避让” 或 “保持车道”,但完全摸不透它是怎么分析路况、怎么一步步推导到这个结论的。这也是业内把它叫做 “黑匣子” 的核心原因。
平心而论,端到端驾驶在多数常规场景下表现很亮眼:比传统逻辑堆叠的智驾反应更果断,操作也更贴近人类司机的习惯。可一旦遇上没见过的 “奇葩情况”,比如突然出现的临时施工区域、形状怪异的障碍物(像掉在路中间的大型纸箱),它就有可能 “判断失误”,做出让人捏把汗的操作。
最麻烦的是后续调试:工程师没法像改代码那样,直接定位问题、修正错误,只能靠 “喂数据”—— 给系统输入大量正确处理这类场景的案例,让它自己慢慢 “学乖”。但问题来了:到底要喂多少数据才能教会它?没人能说准。就像 “薛定谔的猫” 一样,你不知道喂到哪一步它突然就懂了,也不知道是不是还漏了什么特殊情况。
哪怕最后它的准确率能做到 99.99% 甚至更高,也永远没法保证 100% 不出错。换句话说,面对端到端架构的问题,很多时候只能 “治标”—— 靠数据缓解特定场景的漏洞,却很难 “治本”—— 彻底杜绝所有意外情况的发生。而 VLA“语言” 工序的加入,正是为了尝试打开这个 “黑匣子”,让智驾的决策过程更透明、更可控。
【车不仅会开,还会“沟通”】
Wayve的“解说型”驾驶:这家英国公司的LINGO-2模型能边开车边“讲解”,遇到行人减速时会说“因为行人过马路,正在避让”,目前已经和Uber合作测试Robotaxi,计划2027年装到量产车上。
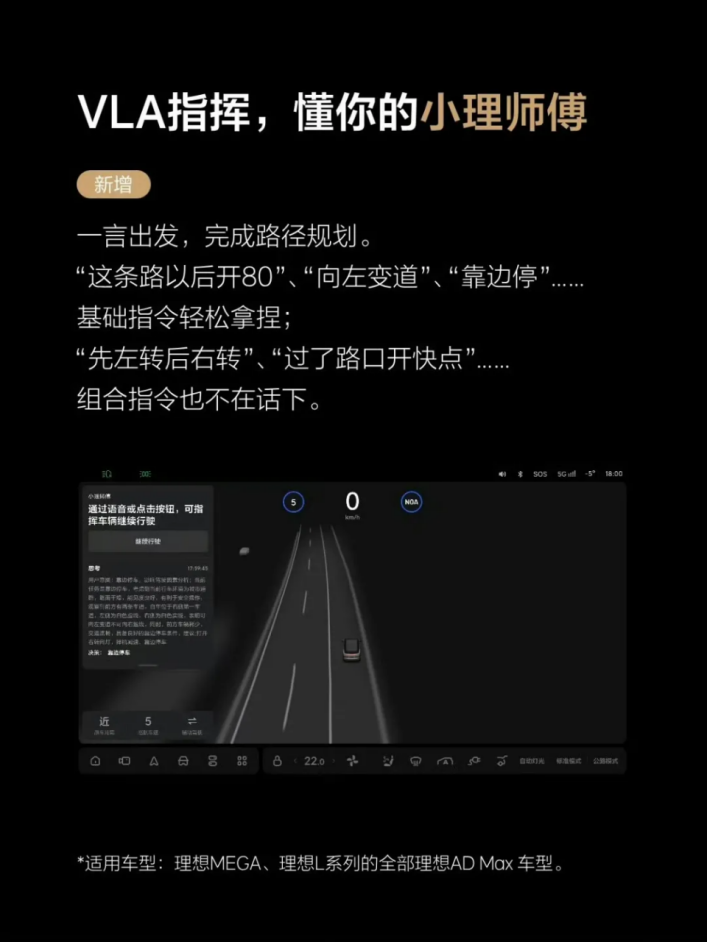
理想的“车载大脑”:新车型上的MindVLA司机大模型不用高精地图,带来多维度提升,比如VLA指挥,语音控制完成路径规划。靠多摄像头就能构建3D路况,还能预测周围车辆的轨迹,同时在混乱环岛里也能选对路线,“这条路线以后开60”、“靠边停”、“过了路口开快点”组合指令也不在话下。
小鹏的“全场景覆盖”:VLA更懂安全,推出的遇事故标识预判风险、预判遮挡盲区“鬼探头”、防御性驾驶功能,从容应对各种路况。同时能让车自己记路、建停车场3D模型,雨天见积水自动减速,夜间还能预判“开门杀”风险。
【写在最后】
从特斯拉用端到端技术打开智驾新局,到理想 MindVLA 实现 “语音控路径、预判车辆轨迹”,再到小鹏 VLA 能防 “开门杀”、自动避积水,我们正实实在在见证一场 “机器懂人” 的变革。
VLA 最关键的价值,就是让车跳出 “只会执行指令的工具” 角色 —— 它既能像人类司机一样灵活应对路况,又能用 “语言” 解释决策,彻底打破了传统端到端 “黑匣子” 的困境。就像 Wayve 的 Robotaxi 边开车边说 “避让行人”,小鹏 VLA 提前预警盲区风险,这些场景都在证明:VLA 不是遥远的概念,而是已经让出行更安全、更贴心的现实。
如果你也对 AI 如何重塑生活?科研如何推动技术落地项目感兴趣。
欢迎大家在评论区留言互动~

















 825
825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









