



目录
编辑释义1 :无返回值不需要添加void,并且构造函数的函数名称要和类名一致
编辑释义4:C++编译器会自动生成一个无参的默认构造函数,但如果用户显示定义构造函数,那么编译器将不再生成默认的构造函数
编辑释义5:无参构造函数和全缺省构造函数都被称之为默认构造函数,但是默认构造函数只能有一个
构造函数
1.构造函数的定义
构造函数是一种特殊的成员函数,它在创建对象时由编译器自动执行,其主要作用是初始化对象。
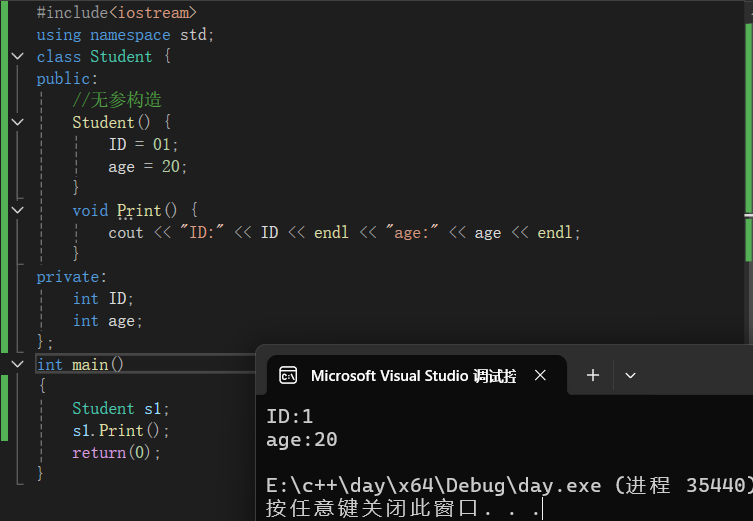
学生类展示:
class Student { public: Student() { ID = 01; age = 20; } void Print() { cout << "ID:" << ID << endl << "age:" << age << endl; } private: int ID; int age; }; int main() { Student s1; s1.Print(); return(0); }
2.构造函数的性质
- 无返回值不需要添加void,并且构造函数的函数名称要和类名一致
- 构造函数可以重载
- 对象被实例化时编译器自动调用对应构造函数
- C++编译器会自动生成一个无参的默认构造函数,但如果用户显示定义构造函数,那么编译器将不再生成默认的构造函数
- 无参构造函数和全缺省构造函数都被称之为默认构造函数,但是默认构造函数只能有一个
 释义1 :无返回值不需要添加void,并且构造函数的函数名称要和类名一致
释义1 :无返回值不需要添加void,并且构造函数的函数名称要和类名一致
如下无参构造函数示例:
释义2:构造函数可以重载
构造函数的重载类型:
1.按照参数进行分类:有参构造和无参构造
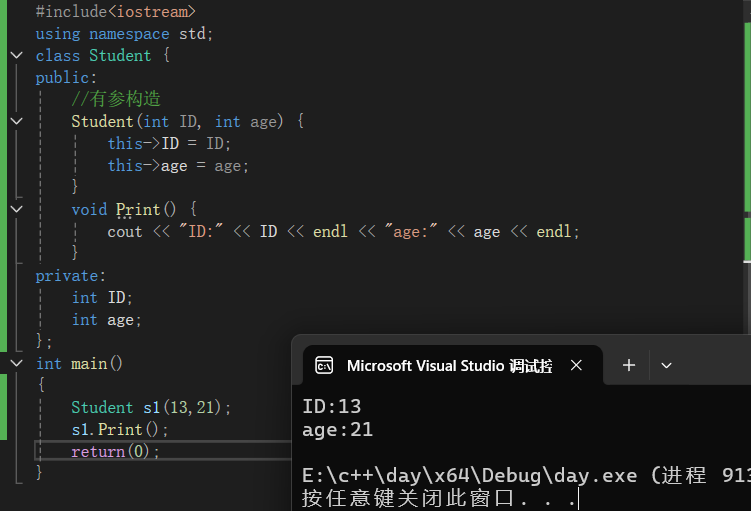
//无参构造 Student() { ID = 01; age = 20; } //有参构造 Student(int ID, int age) { this->ID = ID; this->age = age; }无参构造结果展示:
有参构造结果展示:
初始化列表:
初始化列表是构造函数中的一种语法糖,用于在对象创建时直接初始化成员变量,而不是在构造函数体内赋值,这样做会更加高效,而且在某些情况下是必须的,比如const成员变量和引用类型必须在初始化列表中初始化:
class Student { public: Student(int ID, int age):ID(ID),age(age) { } void Print() { cout << "ID:" << ID << " " << "age:" << age << endl; } private: int ID; const int age; };
2.按照类型进行分类:普通构造函数和拷贝构造函数
拷贝构造函数:是一种特殊的构造函数,具有一般构造函数的特性。可以实现用现有对象去完成对新建对象的赋值操作,使用const修饰。
拷贝构造函数声明:
ClassName(const ClassName& other);其中:
- ClassName 是类的名称,other 是另一个同类型实例对象的引用
代码展示:
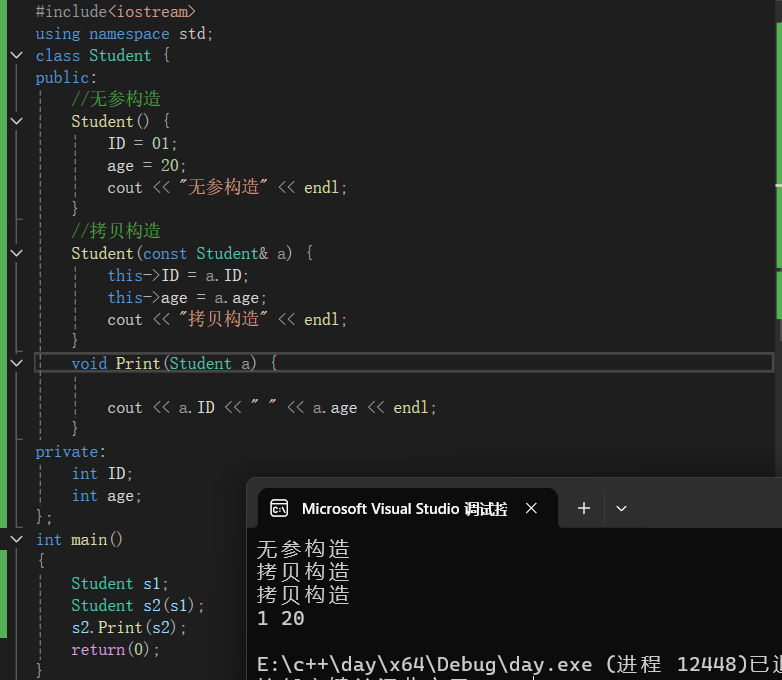
//无参构造 Student() { ID = 01; age = 20; cout << "无参构造" << endl; } //拷贝构造 Student(const Student& a) { this->ID = a.ID; this->age = a.age; cout << "拷贝构造" << endl; }代码结果展示:
从图中我们不难看出:
首先使用无参构造实例化变量s1,初始化s1的ID为1,age为20;接着使用拷贝构造对实例对象s2进行初始化赋值操作,使s2的ID为1,age为20;最后我们调用Print函数输出ID和age,此时注意!!!
我们在调用Print函数时,使用的是值传递的方式,因此会再创建一个Student对象的副本用于传参,这时又触发了拷贝构造函数,使得输出了两次“拷贝构造”。
如果我们希望最后调用Print函数的时候,能够减少拷贝构造函数的调用,该怎么做呢?
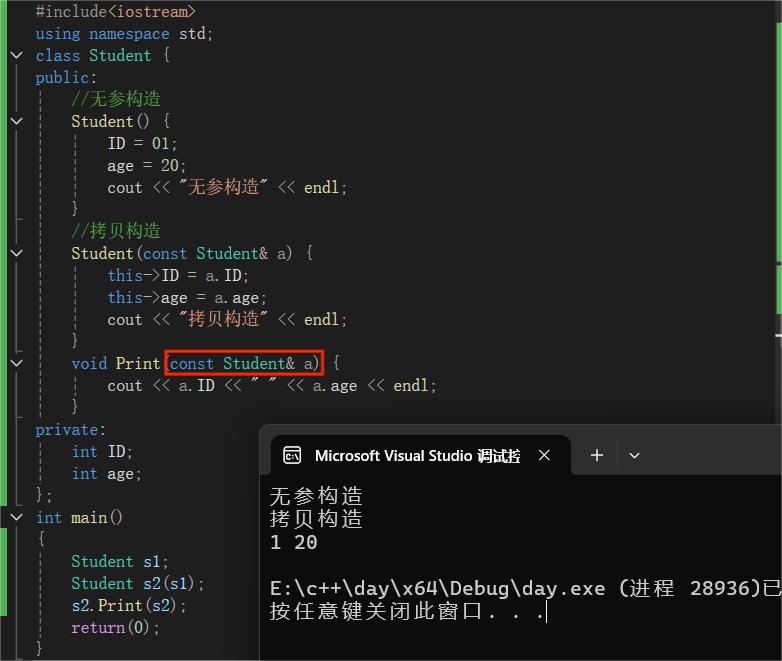
可以考虑将Print函数的参数改为引用传递。
改为引用传递后的结果展示:

释义3:对象被实例化时编译器自动调用对应构造函数
首先,我们需要知道构造函数的调用方法:
- 括号法
- 显示法
- 隐式转换法
1.括号法
语法:
类名 对象名 (参数值);
Student a(2,21);
//有参构造
Student(int ID) {
this->ID = ID;
age = 20;
cout << "1个参数的有参构造" << endl;
}
Student(int ID, int age) {
this->ID = ID;
this->age = age;
cout << "2个参数的有参构造" << endl;
}
int main()
{
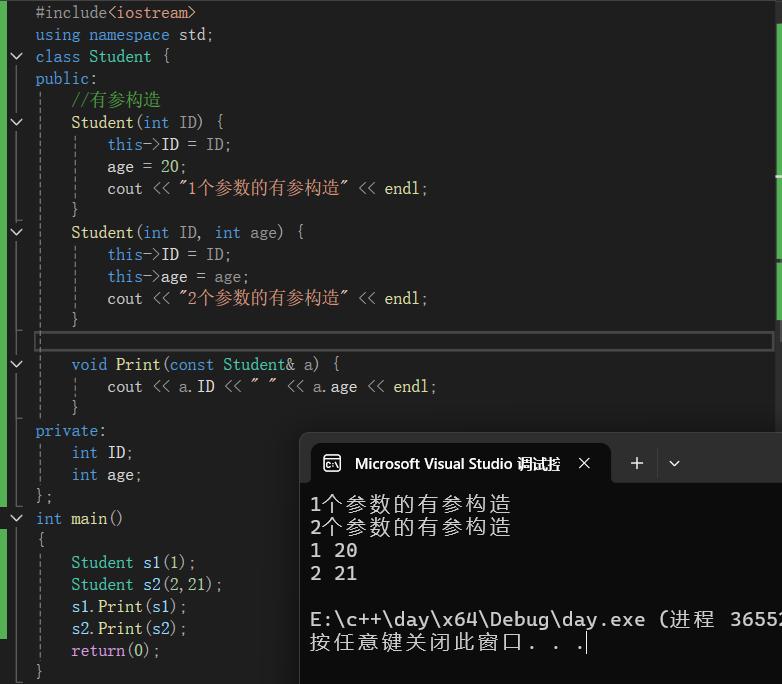
Student s1(1); //括号法调用有参构造
Student s2(2,21); //括号法调用有参构造
s1.Print(s1);
s2.Print(s2);
return(0);
}代码结果展示:
由图可知:
编译器会根据括号中传入的参数个数,自动匹配对应的有参构造函数,从而初始化实例对象。
2.显示法
语法:
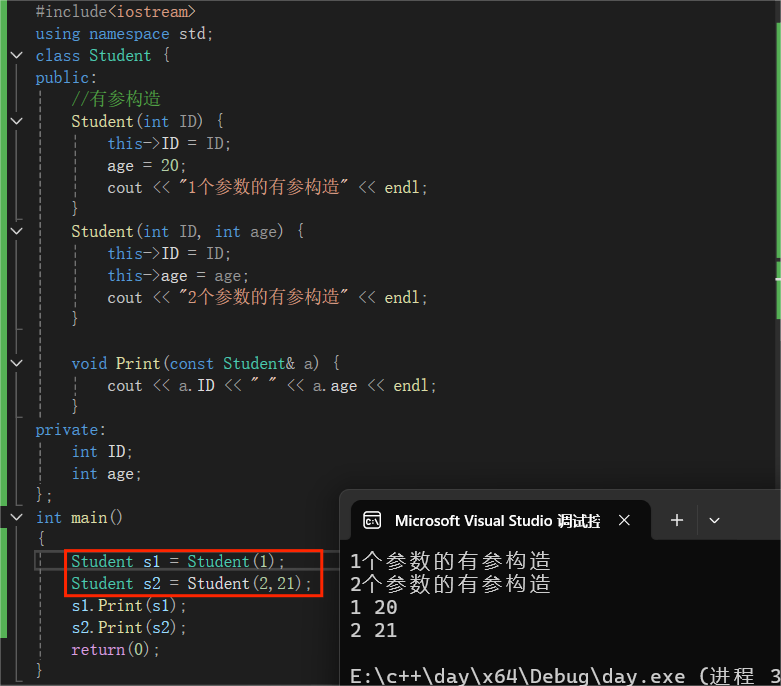
类名 对象名 = 类名(参数值);
Student a = Student(2,21);
代码方面只有创建实例对象时不同:
int main() { Student s1 = Student(1); Student s2 = Student(2,21); s1.Print(s1); s2.Print(s2); return(0); }代码结果展示:
3.隐式转换法
注意:对于隐式转换法来说,多参数的不适用
语法:
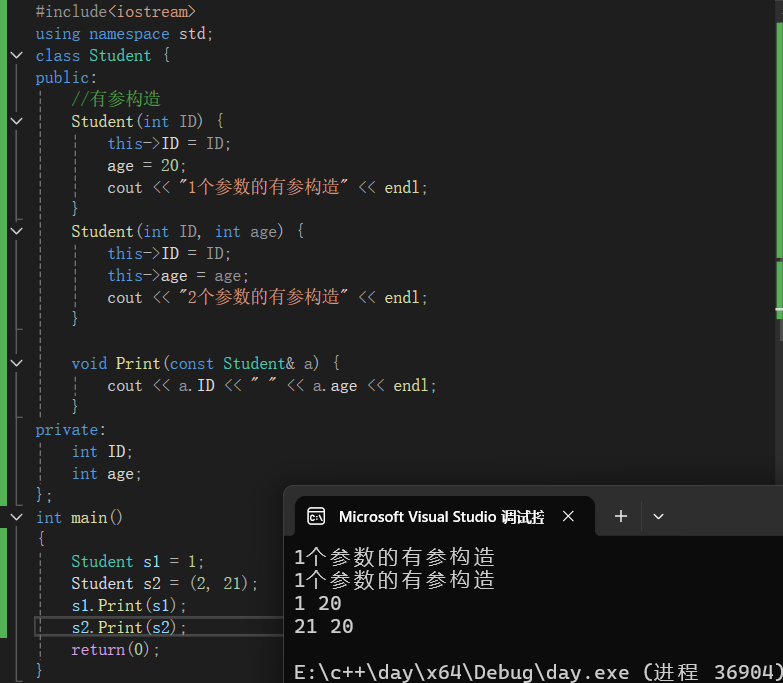
类名 对象名 = 数值;
Student a = 1;
代码展示:
int main() { Student s1 = 1; s1.Print(s1); return(0); }结果展示:
对于图可知:
从结果上可知,我们调用了两次“1个参数的有参构造”,这是因为:
隐式转换法不可以用于多参数,原因是“,”的运算符的运算规则指挥返回最后一个表达式的值,即返回了(2,21)中的21,因此不可以用于多参数。
释义4:C++编译器会自动生成一个无参的默认构造函数,但如果用户显示定义构造函数,那么编译器将不再生成默认的构造函数
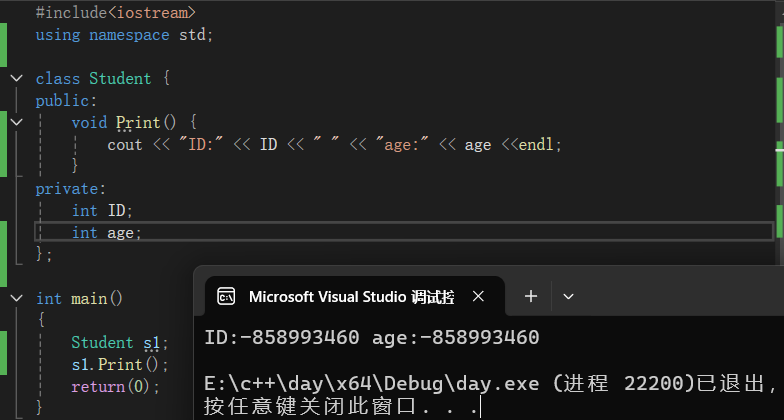
如果我们自己不去显示定义构造函数,使用编译器默认的构造函数:
class Student { public: void Print() { cout << "ID:" << ID << " " << "age:" << age <<endl; } private: int ID; int age; }; int main() { Student s1; s1.Print(); return(0); }
可知输出值为随机值。那么为什么编译器会产生默认构造函数?又为什么会输出随机值呢?那么,我们先来了解一下默认构造函数 :
默认构造函数类型:
- 编译器默认生成的构造函数,是默认构造函数
- 无参构造函数,是默认构造函数
- 全缺省函数,是默认构造函数
C++会把变量分为两种类型:
1.内置类型:int,char,double,指针......2. 自定义类型:class,struct等自己定义的类型对象
C++默认的构造函数不会对内置类型变量进行处理,只有对自定义类型的变量才会进行处理。这就是为什么刚刚没有对ID和age进行初始化处理,因为其是内置类型变量(int类型的变量)
代码示例:
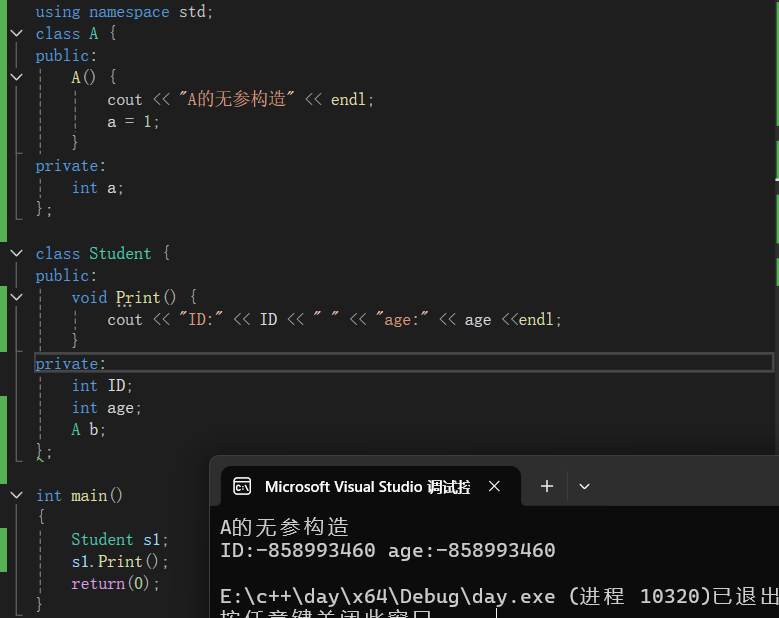
首先,我们创建一个自定义类A,含有成员变量a,并且无参构造对a进行初始化
class A { public: A() { cout << "A的无参构造" << endl; a = 1; } private: int a; };接着,我们将A类作为自定义类型加入到Student的成员变量中
class Student { public: void Print() { cout << "ID:" << ID << " " << "age:" << age <<endl; } private: int ID; int age; A b; }; int main() { Student s1; s1.Print(); return(0); }运行结果展示:
由图可知:
编译器先是调用了类A的无参构造;对于s1.ID和s1.age的值,返回的是随机值;可知,默认构造函数对自定义类型才会进行处理,也就是说,当出现内置类型时,我们就需要自己写构造函数了。
释义5:无参构造函数和全缺省构造函数都被称之为默认构造函数,但是默认构造函数只能有一个
默认构造函数类型:
- 编译器默认生成的构造函数,是默认构造函数
- 无参构造函数,是默认构造函数
- 全缺省函数,是默认构造函数
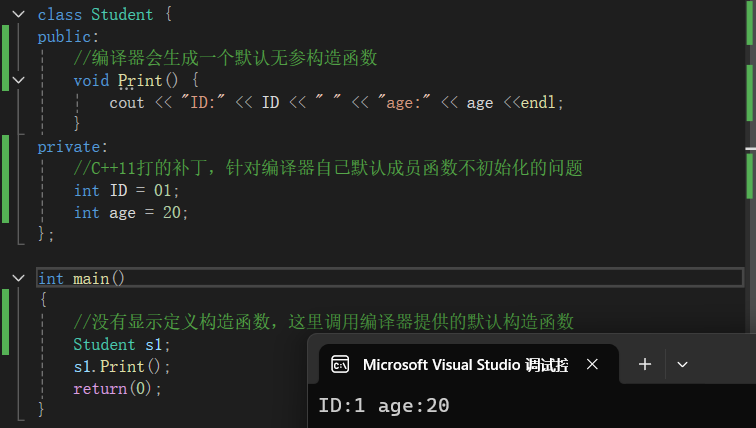
我们可以通过直接在创建类的时候就对成员变量进行赋值初始化,从而达到即使不显示编写构造函数,也可以对内置类型进行处理:
class Student { public: //编译器会生成一个默认无参构造函数 void Print() { cout << "ID:" << ID << " " << "age:" << age <<endl; } private: //C++11打的补丁,针对编译器自己默认成员函数不初始化的问题 int ID = 01; int age = 20; }; int main() { //没有显示定义构造函数,这里调用编译器提供的默认构造函数 Student s1; s1.Print(); return(0); }
总结:
- 构造函数是类中默认就有的,即使自己没有显式定义,但日常最好自己显式定义一个默认构造函数,注意不要使无参和全缺省构造函数同时存在。
- 如果使用默认构造函数,内置类型的变量不会被初始化,会得到一个随机值;自定义类型的变量会调用默认构造函数;如果不想出现随机值,可以在内置类型声明的时候就进行初始化。
析构函数
1.什么是析构函数?
析构函数:与构造函数功能相反,析构函数不是完成对象的销毁,局部对象销毁的工作是由编译器完成的,而对象在被销毁时会自动调用析构函数,完成类的一些资源清理工作。
2.析构函数特性?
- 析构函数的函数名是在类名前面加上~
- 无参无返回值
- 一个类只有一个析构函数,如果用户没有显示定义析构函数,系统会提供默认析构函数;并且编译器默认生成的析构函数,会对自定类型成员调用它的析构函数
- 对象生命周期结束时,编译器自动调用析构函数
举例析构函数:
~Student() {
cout << "~Student" << endl;
}举例实例:
class Student {
public:
Student(int ID, int age):ID(ID),age(age) {
}
~Student() {
cout << "~Student" << endl;
}
void Print() {
cout << "ID:" << ID << " " << "age:" << age << endl;
}
private:
int ID;
const int age;
};
int main()
{
Student s1(2,21);
s1.Print();
return(0);
}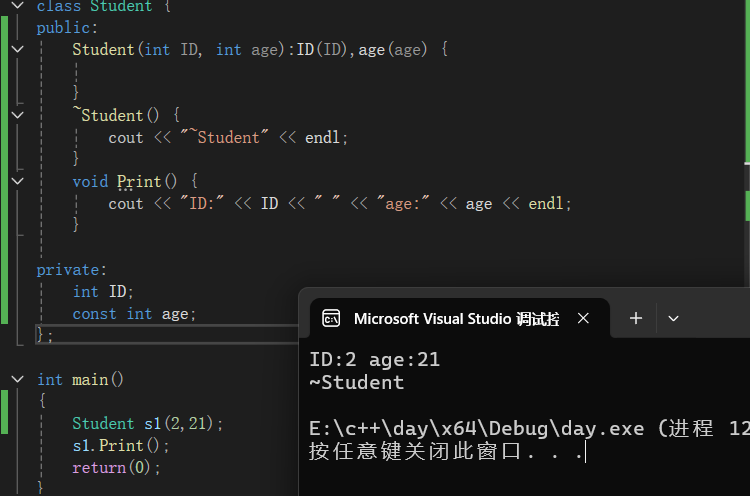
如图可知,最后在对象生命周期结束后,编译器调用了析构函数,输出了“~Student”;
那么,析构函数的目的是完成资源清理,它清理的是什么内容呢?对于我们定义的ID和age这些变量就不需要清理,因为其出了函数栈就被销毁,真正需要析构函数清理的是malloc,new,fopen等等。
3.析构函数的被调用顺序
析构顺序规则:
- 成员变量的析构:首先,对象的非静态成员变量的析构函数会被调用。这些成员变量的析构顺序与它们在类定义中声明的顺序相反。
- 基类的析构:如果对象是某个类的派生类实例,基类的析构函数会被调用,对于多层继承,基类的析构函数调用顺序与继承顺序相反,即从最派生类到最基类。
- 局部对象的析构:在函数作用域中,局部对象的析构顺序与它们被创建的顺序相反,这意味着先创建的对象后被析构。
实例代码:
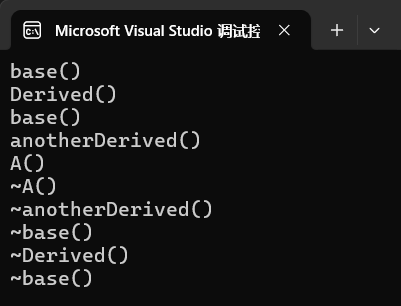
class base { public: base() { cout << "base()" << endl; } ~base() { cout << "~base()" << endl; } }; class Derived :public base{ public: Derived() { cout << "Derived()" << endl; } ~Derived() { cout << "~Derived()" << endl; } }; class anotherDerived :public base { public: anotherDerived() { cout << "anotherDerived()" << endl; } ~anotherDerived() { cout << "~anotherDerived()" << endl; } }; class A { public: Derived d; anotherDerived ad; A() { cout << "A()" << endl; } ~A() { cout << "~A()" << endl; } }; int main() { A a; return(0); }代码结果展示:
析构顺序分析:
- 先销毁A对象a:实现调用A的析构函数
- 再销毁成员变量ad:然后调用anotherDerived的析构函数,并且调用基类base的析构函数
- 最后销毁成员变量d:最后调用Derived的析构函数,并且调用基类base的析构函数
之所以先调用ad的析构函数,再调用d的析构函数,是因为在类A中,我们先定义了成员变量“Derived d”再定义了“anotherDerived ad”,因此可知。

















 5369
5369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









