



一、研究背景与目标
-
作用域是汽车电子控制单元(ECU)之间的通信日志(communication logs, trace),使用 UDP 协议,检测延迟或丢失消息等时间相关异常 (“cycle time anomalies”)。
-
不同于有明确可靠标注的数据集,他们面对的是 标注不一致或不可靠 的情形。规则系统可能标记一些异常,但这些标记不是完全可信的。
-
目标是:用尽可能少的可靠标签 + 模型自身学习正常通信规律,从而能在不可靠标签环境下也能检测异常。
二、数据处理
-
数据采集与字段选取
-
日志来源:测试车辆中的一个 ECU(源),与多个目标设备通信,经由以太网/UDP。用车载 spy logger 拦截 communication traces。
-
每条消息(PDU: protocol data unit)包括若干字段,以下作为输入特征:
-
Name(信号/消息类型)
-
源地址和端口(Source IP + Port)
-
目的地址和端口(Destination IP + Port)
-
时间戳(Timestamp)
-
相对时间差(DeltaTime,即该消息与同型 PDU 上一出现时间的差)
-
动作状态(Activity State,比如正常启动/关闭/未初始化等)
-
-
-
窗口滑动(Sliding Window)
-
将通信 trace 按时间顺序切成窗口(window)来处理。每个窗口包含 W 条消息,其中前部分作为上下文(prompt),后一部分需要预测(prediction),然后滑动步长为 P 消息重新选窗口。上下文与预测部分重叠使用,提高数据利用率。
-
模型在上下文中看到前 W−P 条消息,再尝试预测之后 P 条消息。
-
-
Tokenization(分词/令牌化)
-
使用 Byte Pair Encoding (BPE) 方法自定义词表,因为 ECU 日志“语言”与自然语言不同。BPE 能在字符对频繁出现中生成子词 token,从而兼顾词表大小与表达能力。
-
数值特征(例如 DeltaTime)按字符/数字逐个 token。
-
最终词表大约有 408 个 token。
-
-
训练/验证/测试集划分
-
将日志数据集分为 train / validation / test 三部分(比例大约 0.8 / 0.1 / 0.1)
-
使用滑动窗口产生许多样本,不同模型参数/窗口长度/tokenizer/上下文长度等做对比试验。
-
三、模型与训练流程
| 阶段 | 目标 / Loss / 设置 |
|---|---|
| 预训练阶段(Pre‑Training) | 学习 ECU 通信“语言”即日志序列的正常行为。任务是 next token prediction (NTP)(即给定之前的 token,上下文,预测下一个)。这是标准的自回归 transformer/decoder‑only 模型任务。损失用交叉熵(cross‑entropy)。 |
| 微调阶段(Fine‑Tuning) | 基于预训练模型,加上 LoRA (low‑rank adaptation) 层来适应 anomaly detection 任务;同时加入一个 entropy regularizer(熵正则项),用来让模型对那些被标记为异常/已知异常 tokens 的不确定性(uncertainty)提高,以应对标签不可靠的问题。 |
解释
-
模型架构选的 decoder-only Transformer,使用 Qwen2 架构(Alibaba 的开源系列)。
-
也尝试了一个更小的模型版本 “Mamba‑130M”(130M 参数)以处理较长上下文。
-
在预训练中使用 NTP(next token prediction)任务,词表大小约 408。
-
在微调阶段,设置 LoRA 的秩(rank)为 64,学习率为 5e‑5,entropy regularizer 的权重参数 α = 0.5。
四、异常检测策略与指标
-
Top‑k Metric
在预测下一个 token 时,看 ground truth token 是否在模型预测的前 k 个候选中。如果不在 top‑k 中,则该 token 被视为异常。 -
Perplexity Metric
Perplexity(困惑度)是衡量预测不确定性的标准。如果在某上下文中模型的 perplexity 超过一个预设阈值,则认为对应位置/对应 token 是异常。 -
综合 Loss 包含熵正则化
微调时的目标函数,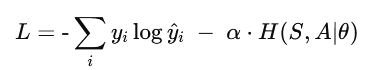 ,第一部分是标准 NTP 的 cross‑entropy,第二部分是熵正则化,用来鼓励模型在标注为异常的 token 上保持预测分布的不确定(entropy 高)。
,第一部分是标准 NTP 的 cross‑entropy,第二部分是熵正则化,用来鼓励模型在标注为异常的 token 上保持预测分布的不确定(entropy 高)。 -
阈值与过滤机制
用滑动窗口得到 metric(例如 perplexity 或 top‑k)对于每一个位置/token。引入过滤器(filter)与阈值 (threshold):例如要连续若干行(行数宽度 = filter‑width)超过阈值/低于阈值才能判断为异常,以减少误报/噪声的影响。
五、实验结果亮点
-
在预训练阶段,用不同模型(Qwen‑1.3B, Qwen‑0.4B, Mamba‑130M)实验 NTP 准确率和困惑度。比如 Mamba‑130M accuracy ~ 95.63,perplexity ~ 1.42;Qwen‑0.4B ~ 97.03 / 1.53;Qwen‑1.3B ~ 98.62 / 1.03。
-
比较不同 tokenizers(如每行一个 token/两 token/BPE 多 token per row)对 NTP 性能的影响。BPE Tokenizer 表现最好。
-
不同 prompt(上下文长度/窗口大小)也影响性能:更长上下文 + 更细粒度 tokenization 带来更好 NTP 准确率和较低 perplexity。
-
在 anomaly detection(微调阶段)中,用 entropy regularizer 的方案在 “regions” 上(即一组连续异常)达到了 recall ≈ 81%,precision ≈ 81%。
-
相比之下,用 contrastive regularizer(另一种目标函数)的 recall / precision 都低很多(recall 0.35, precision ~0.63)
六、小结
优点:
-
能在标注不可靠/不完全的情况下工作,用少量已知异常 + 自学习的正常模式就能做到不错检测效果。
-
Decoder‑only 模型+ LoRA 微调+熵正则化组合是一个有效架构。
-
各种 tokenization、上下文长度、模型规模的对比实验,表明设计选择的重要,特别是上下文长 + 细粒度 tokenization + 大模型能带来性能提升。
局限与可能改进处:
-
虽然标注不可靠,但依然依赖一些已知异常作为线索;完全无异常标注的场景还没验证。
-
Context 长度受到硬件/训练资源限制,目前最大是 4096 token(他们提到这使得只能捕捉大约 25% 的 cycle time 变化)
-
误报(false positives)可能较多,尤其因为标签不一致,模型可能被“惩罚”(regularizer)得不够明确。
-
实验是离线日志;实际部署中的实时检测、延迟、流式处理尚未完整验证。
参考:
Good Enough to Learn: LLM-based Anomaly Detection in ECU Logs without Reliable Labels

















 52
52

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









