







 文章讨论了MQ在系统设计中的重要作用,包括实现异步通信以提高响应速度,通过解耦减少系统间的依赖,以及用于流量削峰保护应用和数据库。同时,也提到了使用MQ可能带来的系统可用性和复杂性问题,强调在架构设计时需谨慎决策。最后,提到了RabbitMQ作为常用的消息中间件的工作模型。
文章讨论了MQ在系统设计中的重要作用,包括实现异步通信以提高响应速度,通过解耦减少系统间的依赖,以及用于流量削峰保护应用和数据库。同时,也提到了使用MQ可能带来的系统可用性和复杂性问题,强调在架构设计时需谨慎决策。最后,提到了RabbitMQ作为常用的消息中间件的工作模型。
为什么要使用MQ
-
实现异步通信
异步是,调用在发出之后,这个调用就直接返回了,所以没有返回结果。也就是说,当一个异步过程调用发出后,调用者不会马上得到结果。而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用
实时转账实际上是异步通信,因为这个里面涉及的机构比较多,调用链路比较长,本行做了一些列的处理之后,转发给银联或者人民银行的支付系统,再转发给接收行,接受行处理以后再原路返回 -
实现系统解耦
耦合是系统内部或者系统之间存在相互作用,相互影响和相互依赖。
比如我们以12306 网站退票为例,在传统的通信方式中,订单系统发生了退货的动作,那么要依次调用所有下游系统的API,比如调用库存系统的API 恢复库存,因为这张火车票还要释放出去给其他乘客购买;调用支付系统的API,不论是支付宝微信还是银行卡,要把手续费扣掉以后,原路退回给消费者;调用通知系统API 通知用户退货成功。
(多线程)
多线程或者线程池是可以实现的,但是每一个需要并行执行的地方都引入线程,又会带来线程或者线程池的管理问题。
所以,这种情况下,我们可以引入MQ 实现系统之间依赖关系的解耦合。
引入MQ 以后:
订单系统只需要把退货的消息发送到消息队列上,由各个下游的业务系统自己创建队列,然后监听队列消费消息。
在这种情况下订单系统里面就不需要配置其他系统的IP、端口、接口地址了,因为它不需要关心消费者在网络上的什么位置,所以下游系统改IP 没有任何影响。甚至不需要关心消费者有没有消费成功,它只需要把消费发到消息队列的服务器上就可以了。
这样,我们就实现了系统之间依赖关系的解耦。 -
实现流量削峰
在很多的电商系统里面,有一个瞬间流量达到峰值的情况,比如京东的618,淘宝的双11,还有小米抢购。普通的硬件服务器肯定支撑不了这种百万或者千万级别的并发量,就像2012 年的小米一样,动不动服务器就崩溃。
如果通过堆硬件的方式去解决,那么在流量峰值过去以后就会出现巨大的资源浪费。那要怎么办呢?如果说要保护我们的应用服务器和数据库,限流也是可以的,但是这样又会导致订单的丢失,没有达到我们的目的。
为了解决这个问题,我们就可以引入MQ,MQ 既然是队列,一定有队列的特性,我们知道队列的特性是什么?
(先进先出FIFO)
这样,我们就可以先把所有的流量承接下来,转换成MQ 消息发送到消息队列服务器上,业务层就可以根据自己的消费速率去处理这些消息,处理之后再返回结果。就像我们在火车站排队一样,大家只能一个一个买票,不会因为人多就导致售票员忙不过来。如果要处理快一点,大不了多开几个窗口(增加几个消费者)。
这个是我们利用MQ 实现流量削峰的一个案例。
如果大家的公司里面有用到MQ 的话,也可以对号入座看看是起到了什么作用。
总结起来:
1) 对于数据量大或者处理耗时长的操作,我们可以引入MQ 实现异步通信,减少客户端的等待,提升响应速度。
2) 对于改动影响大的系统之间,可以引入MQ 实现解耦,减少系统之间的直接依赖。
3) 对于会出现瞬间的流量峰值的系统,我们可以引入MQ 实现流量削峰,达到保护应用和数据库的目的。
所以对于一些特定的业务场景,MQ 对于优化我们的系统还是有很大的帮助的,那么大家想一下,把传统的RPC 通信改成MQ 通信会不会带来一些问题呢?
使用消息队列带来的一些问题
系统可用性降低:原来是两个节点的通信,现在还需要独立运行一个服务,如果MQ服务器或者通信网络出现问题,就会导致请求失败。
系统复杂性提高: 为什么说复杂?第一个就是你必须要理解相关的模型和概念,才能正确地配置和使用MQ。第二个,使用MQ 发送消息必须要考虑消息丢失和消息重复消费的问题。一旦消息没有被正确地消费,就会带来数据一致性的问题。
所以,我们在做系统架构的时候一定要根据实际情况来分析,不要因为我们说了这么多的MQ 能解决的问题,就盲目地引入MQ。
- 消息通信协议
- 常用的消息中间件
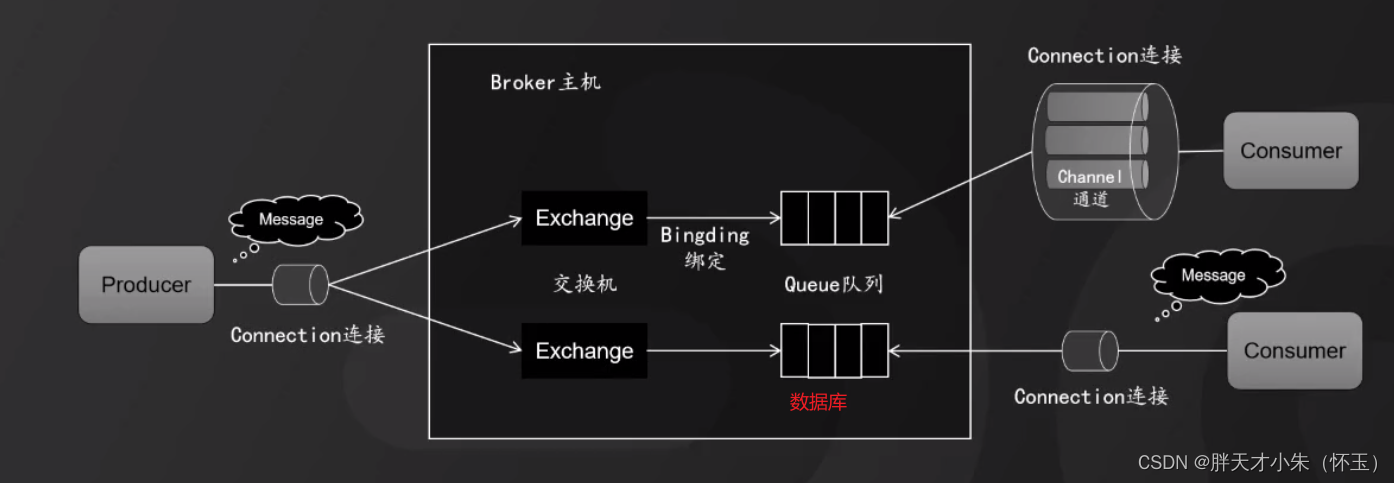
- RabbitMQ工作模型



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











