







 本文通过实例展示了如何使用Python爬虫采集信用中国网站的数据,并详细介绍了如何将获取的数据写入CSV文件、MySQL数据库以及Oracle数据库。同时,文章还提及了检查数据更新的方法。
本文通过实例展示了如何使用Python爬虫采集信用中国网站的数据,并详细介绍了如何将获取的数据写入CSV文件、MySQL数据库以及Oracle数据库。同时,文章还提及了检查数据更新的方法。
效果图


简述
1. 需要用到 requests 库。
2. 利用多进程同步爬取,multiprocessing库。
3. 需要对目标网站做接口分析,找到读取数据的接口。
4. 获取到的数据可以利用正则清洗。
5. 采集的数据保存到csv.
>code
# -*- coding=utf-8 -*-
__author__ = 'ManGe'
'''
信用中国 四川成都 信用代码公示爬虫
地址:http://credit.chengdu.gov.cn/www/index.html#/m///xydm/1/1/%7B10%7D/
'''
import os
import re
import sys
import time
import json
import requests
from requests.exceptions import ReadTimeout, ConnectionError, RequestException
from string import Template
import csv
from multiprocessing import Process
import datetime
defaultencoding = 'utf-8'
if sys.getdefaultencoding() != defaultencoding:
reload(sys)
sys.setdefaultencoding(defaultencoding)
#USER_AGENTS 随机头信息
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
]
#构造请求头
HEADER = {
'User-Agent': random.choice(USER_AGENTS),
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en-US,en;q=0.5',
'Connection': 'keep-alive',
'Accept-Encoding': 'gzip, deflate',
}
#Get网页,返回内容
def get_html( url_path, payload = '', cookies = '',proxies = ''):
try:
s = requests.Session()
r = s.get(
url_path,#路径
headers=HEADER,#请求头
params=payload,#传参 @payload 字典或者json
cookies=cookies,#cookies
verify=True,#SSL验证 @verify False忽略;True开启
proxies=proxies,#代理
timeout=30)#@timeout 超时单位 秒
r.raise_for_status()
#print r.headers#获取响应头
#print r.cookies#获取cookies
return r.text
except HTTPError:
print('HTTPError')
except ReadTimeout:
print('Timeout')
except ConnectionError:
print('Connection error')
except RequestException:
print('RequestException')
#Get网页,返回内容
def post_html( url_path, datas, payload = '', cookies = '',proxies = ''):
try:
s = requests.Session()
r = s.post(
url_path,#路径
headers=HEADER,
data = datas,#请求头
params=payload,#传参 @payload 字典或者json
cookies=cookies,#cookies
verify=True,#SSL验证 @verify False忽略;True开启
proxies=proxies,#代理
timeout=30)#@timeout 超时单位 秒
#r.raise_for_status()
#print r.headers#获取响应头
#print r.cookies#获取cookies
return r.text
except ReadTimeout:
print('Timeout')
except ConnectionError:
print('Connection error')
except RequestException:
print('RequestException')
test_url ="http://credit.chengdu.gov.cn/dr/getCreditCodeList.do"
# 1页分 100 1408145/100 页
# 1页分 1000 1408145/1000 页
# 1页分 10000 1408145/10000 页 141页
#datas_test = {'type': '1', 'page': '1',"pageSize":"1000","keyWord":"","appType":"APP001"}
'''
[
{
"name": "type",
"value": "1"
},
{
"name": "page",
"value": "1"
},
{
"name": "pageSize",
"value": "10"
},
{
"name": "keyWord",
"value": ""
},
{
"name": "appType",
"value": "APP001"
}
]
'''
#html_data = post_html(test_url,datas_test)
#print(html_data)
#获取 options
def get_options(html):
reg = r'\{"time"(.*?)\},'
reger = re.compile(reg)
data = re.findall(reger, html)
return data
#写入 csv
# 2分钟爬 140万数据
def get_all_datas(n_s,n_d):
n=n_s
while n<n_d:
datas_test = {'type': '1', 'page': n,"pageSize":"10000","keyWord":"","appType":"APP001"}
html_data = post_html(test_url,datas_test)
a_dic = json.loads(html_data)
datas_2 = a_dic["msg"]
datas3 = datas_2["rows"]
print('D:/py_test/yibiao_Auto/report/xyzg_data/XYZG_datas_'+str(n)+'.csv')
with open('D:/py_test/yibiao_Auto/report/xyzg_data/XYZG_datas_'+str(n)+'.csv', 'a', newline='', encoding='utf-8') as f:
for datas4 in datas3:
[f.write('{0} , '.format(value)) for key, value in datas4.items()]
f.write('\n')
#print(row)
#writer.writerow(str(row))
n+=1
def main():
#print("主进程执行中>>> pid={0}".format(os.getpid()))
PID_test_number = 15
ps=[]
# 创建子进程实例
for i in range(PID_test_number):
if i == 0:
p=Process(target=get_all_datas,name="get_all_datas"+str(i),args=(0,10,))
else:
p=Process(target=get_all_datas,name="get_all_datas"+str(i),args=(i*10,(i+1)*10,))
ps.append(p)
# 开启进程
for i in range(PID_test_number):
ps[i].start()
# 阻塞进程
for i in range(PID_test_number):
ps[i].join()
if __name__ == '__main__':
main()
写入 CSV
#类型2 机关群团
def get_all_datas_Type_2():
datas_test = {'type': '2', 'page': 1,"pageSize":"2096","keyWord":"","appType":"APP001"}
html_data = post_html(test_url,datas_test)
a_dic = json.loads(html_data)
datas_2 = a_dic["msg"]
datas3 = datas_2["rows"]
print('D:/py_test/yibiao_Auto/report/XYZG_datas_Type2.csv')
with open('D:/py_test/yibiao_Auto/report/XYZG_datas_Type2.csv', 'a', newline='', encoding='utf-8') as f:
for datas4 in datas3:
[f.write('{0} , '.format(value)) for key, value in datas4.items()]
f.write('\n')
#类型3 事业单位
def get_all_datas_Type_3():
datas_test = {'type': '3', 'page': 1,"pageSize":"6554","keyWord":"","appType":"APP001"}
html_data = post_html(test_url,datas_test)
a_dic = json.loads(html_data)
datas_2 = a_dic["msg"]
datas3 = datas_2["rows"]
print('D:/py_test/yibiao_Auto/report/XYZG_datas_Type3.csv')
with open('D:/py_test/yibiao_Auto/report/XYZG_datas_Type3.csv', 'a', newline='', encoding='utf-8') as f:
for datas4 in datas3:
[f.write('{0} , '.format(value)) for key, value in datas4.items()]
f.write('\n')
#类型4 社会组织
def get_all_datas_Type_4():
datas_test = {'type': '4', 'page': 1,"pageSize":"12147","keyWord":"","appType":"APP001"}
html_data = post_html(test_url,datas_test)
a_dic = json.loads(html_data)
datas_2 = a_dic["msg"]
datas3 = datas_2["rows"]
print('D:/py_test/yibiao_Auto/report/XYZG_datas_Type4.csv')
with open('D:/py_test/yibiao_Auto/report/XYZG_datas_Type4.csv', 'a', newline='', encoding='utf-8') as f:
for datas4 in datas3:
[f.write('{0} , '.format(value)) for key, value in datas4.items()]
f.write('\n')
写入 Mysql
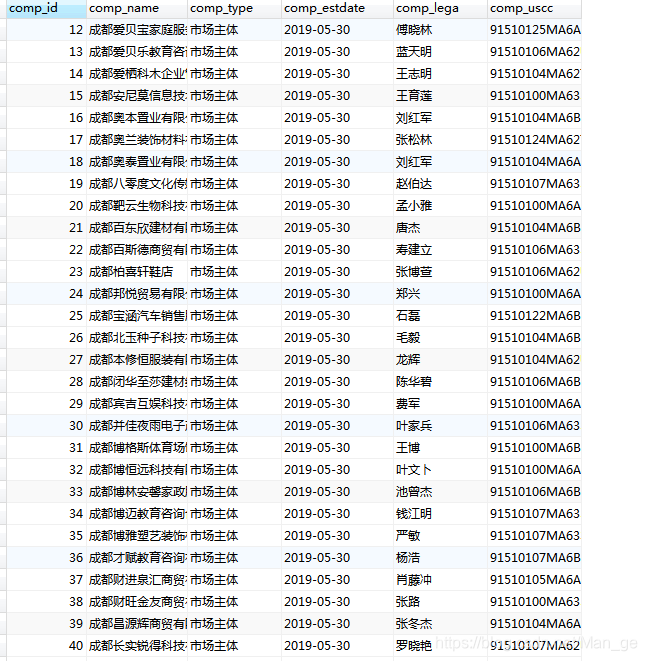
社会主体表
CREATE TABLE `main_c` (
`comp_id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`comp_name` char(250) DEFAULT NULL,
`comp_type` char(10) DEFAULT NULL,
`comp_estdate` char(30) DEFAULT NULL,
`comp_lega` char(250) DEFAULT NULL,
`comp_uscc` char(80) DEFAULT NULL,
PRIMARY KEY (`comp_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1457915 DEFAULT CHARSET=utf8;
import unitys.mysql_do as manmy
def input_to_my_db_4(comp_name_val,comp_type_val,comp_reg_val,comp_lega_val,comp_uscc_val):
mydb = manmy.DB_funtion('127.0.0.1',3306,'cinfo','root','123')
sql="INSERT INTO regime_c (comp_name,comp_type,comp_reg,comp_lega,comp_uscc) \
VALUES ('"+comp_name_val+"','"+comp_type_val+"','"+comp_reg_val+"','"+comp_lega_val+"','"+comp_uscc_val+"');"
mydb.exect(sql)
def input_all_datas_Type_4_to_mysql():
datas_test = {'type': '4', 'page': 1,"pageSize":"12147","keyWord":"","appType":"APP001"}
html_data = post_html(test_url,datas_test)
a_dic = json.loads(html_data)
datas_2 = a_dic["msg"]
datas3 = datas_2["rows"]
for datas4 in datas3:
print(datas4)
#print(datas4["name"])
COMPANY_val = datas4["name"]
print("【公司名称】 = "+COMPANY_val)
COMTYPE_val = "社会组织"
print("【类型】 = "+COMTYPE_val)
REGTYPE_val = datas4["four"]
print("【登记类型】 = "+REGTYPE_val)
LEGALPSN_val = datas4["fr"]
print("【法人代表】 = "+LEGALPSN_val)
USCC_val = datas4["idno"]
print("【统一社会编码】 = "+USCC_val)
print(str(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))))
CRTIME_val = str(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
input_to_my_db_4(COMPANY_val,COMTYPE_val,REGTYPE_val,LEGALPSN_val,USCC_val)
print("\n\n")
def input_to_my_db_3(comp_name_val,comp_type_val,comp_host_val,comp_lega_val,comp_uscc_val):
mydb = manmy.DB_funtion('127.0.0.1',3306,'cinfo','root','123')
sql="INSERT INTO gover_c (comp_name,comp_type,comp_host,comp_lega,comp_uscc) \
VALUES ('"+comp_name_val+"','"+comp_type_val+"','"+comp_host_val+"','"+comp_lega_val+"','"+comp_uscc_val+"')"
mydb.exect(sql)
def input_all_datas_Type_3_to_mysql():
datas_test = {'type': '3', 'page': 1,"pageSize":"6554","keyWord":"","appType":"APP001"}
html_data = post_html(test_url,datas_test)
a_dic = json.loads(html_data)
datas_2 = a_dic["msg"]
datas3 = datas_2["rows"]
for datas4 in datas3:
print(datas4)
#print(datas4["name"])
COMPANY_val = datas4["name"]
COMPANY_val = COMPANY_val.replace("'","")
print("【公司名称】 = "+COMPANY_val)
COMTYPE_val = "事业单位"
print("【类型】 = "+COMTYPE_val)
HOSTUNIT_val = datas4["four"]
print("【登记类型】 = "+HOSTUNIT_val)
LEGALPSN_val = datas4["fr"]
print("【法人代表】 = "+LEGALPSN_val)
LEGALPSN_val = LEGALPSN_val.replace("'","")
USCC_val = datas4["idno"]
print("【统一社会编码】 = "+USCC_val)
print(str(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))))
CRTIME_val = str(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
input_to_my_db_3(COMPANY_val,COMTYPE_val,HOSTUNIT_val,LEGALPSN_val,USCC_val)
print("\n\n")
... ...
数据直接写入 Oracle 数据库
import unitys.man_oracle as mano
mydb = mano.ORACLE_DB_funtion()
def input_to_o_db_4(COMPANY_val,COMTYPE_val,LEGALPSN_val,USCC_val,REGTYPE_val,CRTIME_val):
sql="INSERT INTO CREDITCD (COMPANY,COMTYPE,LEGALPSN,USCC,REGTYPE,CRTIME) VALUES ('"+COMPANY_val+"','"+COMTYPE_val+"','"+LEGALPSN_val+"','"+USCC_val+"','"+REGTYPE_val+"','"+CRTIME_val+"')"
mydb.exect(sql)
def input_all_datas_Type_4_to_oracle():
datas_test = {'type': '4', 'page': 1,"pageSize":"12147","keyWord":"","appType":"APP001"}
html_data = post_html(test_url,datas_test)
a_dic = json.loads(html_data)
datas_2 = a_dic["msg"]
datas3 = datas_2["rows"]
for datas4 in datas3:
print(datas4)
#print(datas4["name"])
COMPANY_val = datas4["name"]
print("【公司名称】 = "+COMPANY_val)
COMTYPE_val = "社会组织"
print("【类型】 = "+COMTYPE_val)
REGTYPE_val = datas4["four"]
print("【登记类型】 = "+REGTYPE_val)
LEGALPSN_val = datas4["fr"]
print("【法人代表】 = "+LEGALPSN_val)
USCC_val = datas4["idno"]
print("【统一社会编码】 = "+USCC_val)
print(str(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))))
CRTIME_val = str(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
input_to_o_db_4(COMPANY_val,COMTYPE_val,LEGALPSN_val,USCC_val,REGTYPE_val,CRTIME_val)
print("\n\n")
... ...
检查更新的方法
def get_max_time_1():
sql="SELECT MAX(ESTDATE) FROM CREDITCD where COMTYPE = '市场主体'"
#print(mydb.execute_sql(sql)[0][0])
#time1= time.mktime()
#print(time1)
return mydb.execute_sql(sql)[0][0]
#print(get_max_time_1())
def time_bijiao(time1,time2):
print("--***数据里最大时间:"+str(time1))
print("--***当前数据的时间:"+str(time2))
d1 = datetime.datetime.strptime(time1, '%Y-%m-%d')
d2 = datetime.datetime.strptime(time2, '%Y-%m-%d')
delta = d1 - d2
print(delta.days)
#如果大于 0 则没有最新的数据
if delta.days >0:
return True
else:
return False
# 信用中国(成都) 检查更新的方法
def input_new_datas_Type_1_to_oracle():
Max_time = get_max_time_1()
n=0
while True:
try:
datas_test = {'type': '1', 'page': n,"pageSize":"1000","keyWord":"","appType":"APP001"}
html_data = post_html(test_url,datas_test)
print(html_data)
print(type(html_data))
if html_data != "":
a_dic = json.loads(html_data)
datas_2 = a_dic["msg"]
datas3 = datas_2["rows"]
for datas4 in datas3:
print(datas4)
COMPANY_val = datas4["name"]
#非法字符处理
#COMPANY_val = COMPANY_val.strip("\'\",","")
print("【公司名称】 = "+COMPANY_val)
if COMPANY_val =="":
COMPANY_val = " "
COMTYPE_val = "市场主体"
print("【类型】 = "+COMTYPE_val)
ESTDATE_val = datas4["time"]
print("【时间】 = "+ESTDATE_val)
LEGALPSN_val = datas4["fr"]
print("【法人代表】 = "+LEGALPSN_val)
USCC_val = datas4["idno"]
print("【统一社会编码】 = "+USCC_val)
print(str(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))))
CRTIME_val = str(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
print("通过时间判断是否是最新内容")
updata_yesno = time_bijiao(Max_time,ESTDATE_val)
print(updata_yesno)
print("\n\n")
if updata_yesno == False:
print("添加最新内容")
input_to_o_db_1(COMPANY_val,COMTYPE_val,LEGALPSN_val,USCC_val,ESTDATE_val,CRTIME_val)
elif updata_yesno == True:
print("\n\n******************** 没有最新内容了 ********************")
exit(0)
else:
print("时间判断出现了异常")
else:
print("访问被限制")
n+=1
#保护程序在网络环境极差的情况下断开,下次循环继续执行上一次的页数, 由游标n 控制页数
except:
print("当前网络异常")
continue


















 4398
4398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









