






如何攻克复杂数据处理难题,构建更强大、适应性更强的智能模型?不妨着眼于前沿的多模态融合与迁移学习技术。
多模态融合将图像、文本等多元数据信息汇聚整合,为模型训练打造全方位的数据基石;迁移学习则依托预训练模型,赋予新模型在小数据环境下依然卓越的性能表现。二者强强联合,不仅能大幅提升模型在各类复杂任务中的准确率与效率,更能拓展模型在不同场景下的应用边界,增强其泛化能力与可解释性。例如,运用多模态迁移学习的医学图像分类模型,借助PubMedCLIP创新性地融合图像与文本模态,在小数据场景下实现了高精度分类,为医学图像分析开辟新路径。
多模态融合与迁移学习的结合,已然成为学术界与工业界炙手可热的研究方向,在医学影像分析、智能交互系统等诸多领域成果斐然,展现出巨大的创新潜力。
为助力科研工作者在该领域取得突破,我精心梳理了【12篇】多模态融合结合迁移学习的前沿论文,并提炼创新要点,为大家的研究提供灵感和思路。
【论文1】A Multimodal Transfer Learning Approach Using PubMedCLIP for Medical Image Classification
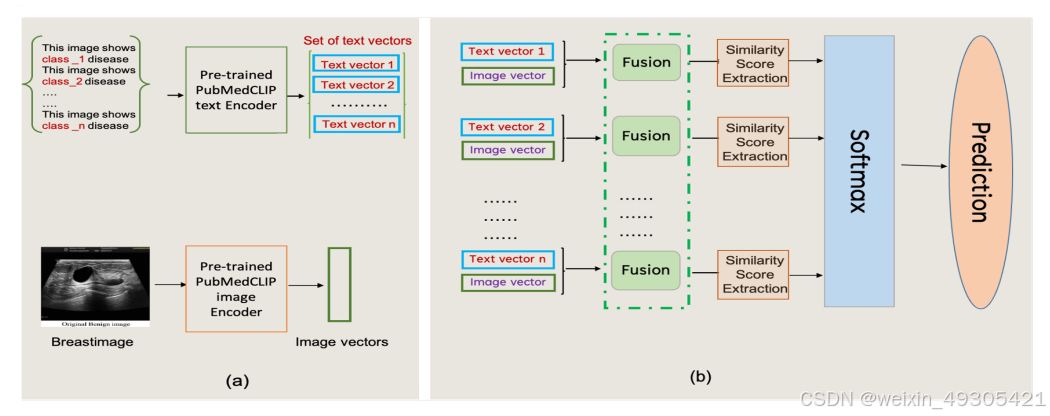
1.研究方法
论文提出了该研究提出的方法是将图像和疾病标签模板作为输入,利用预训练的 PubMedCLIP 模型对图像和文本分别进行编码,得到相应的向量表示,再通过融合模块将其合并为多模态特征向量,用于疾病分类。
2.论文创新点
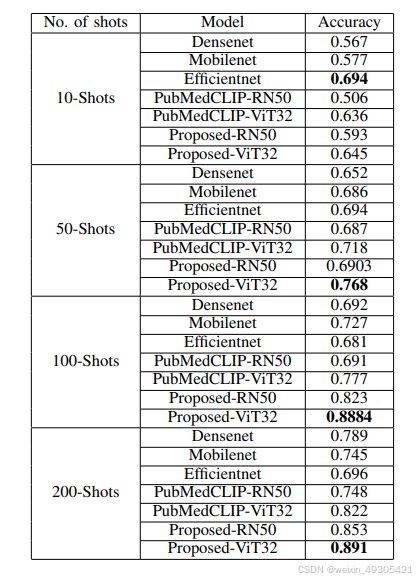
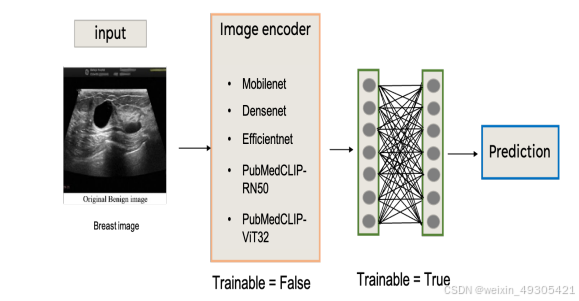
-
多模态融合创新:打破传统单模态局限,创新性地将文本与图像模态结合。利用PubMedCLIP对两种模态进行编码融合,充分发挥多模态信息互补优势,为医学图像分类带来更丰富特征,提升模型性能。
-
小数据表现卓越:借助PubMedCLIP预训练模型,新模型在小数据场景下优势显著。仅需少量训练数据就能实现高精度分类,有效解决医学数据稀缺难题,为资源受限的医学图像分析场景提供可靠方案。
-
拓展预训练模型应用:首次深入挖掘PubMedCLIP多模态预训练模型在医学图像分类任务中的潜力,突破以往仅使用其图像模态的局限,开创多模态联合应用的新方式,为医学图像分类领域提供新思路和方法。
【论文2】CM3T: Framework for Efficient Multimodal Learning for Inhomogeneous Interaction Datasets
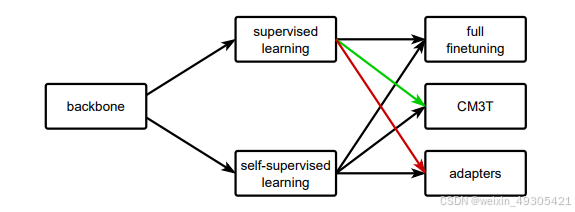
1.研究方法
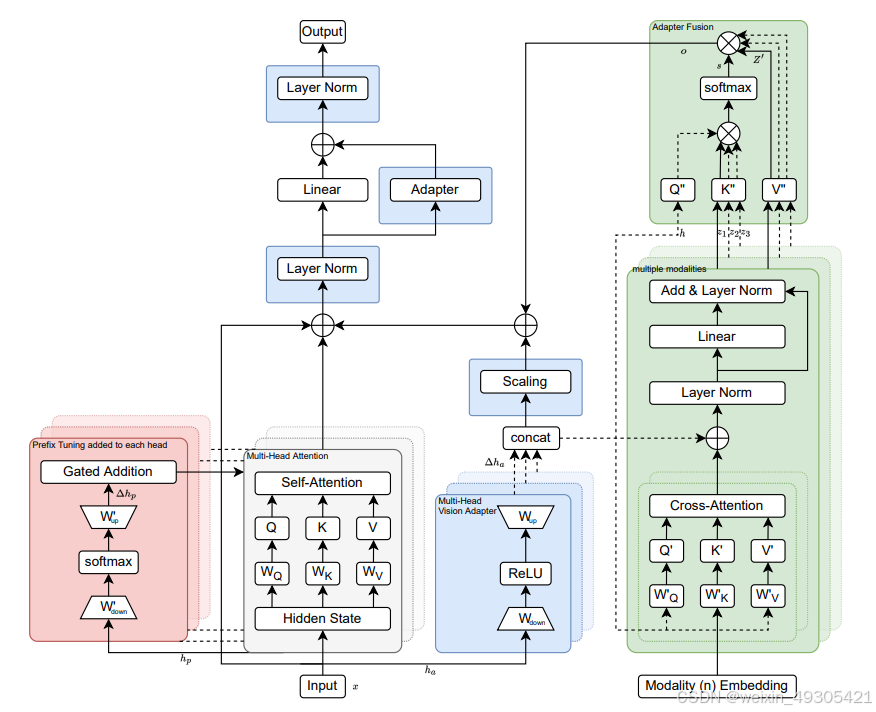
论文提出的CM3T(Cross Multimodal Multi-dataset Multitask Transformer),是一种新的与模型无关的插件架构,用于跨学习。以基于 Transformer 的预训练模型为骨干网络,添加多头视觉适配器和前缀调整,仅训练这些插件以适应新任务和数据集;引入跨注意力适配器,用于融合多模态信息,在不改变骨干网络权重的情况下添加新模态。
2.论文创新点
-
提出新适配器:多头视觉适配器与传统监督预训练配合良好,突破了现有PETL技术的局限,通过将输入按窗口维度划分,提升了模型在不同输入块上的学习能力。
-
改进多模态学习:跨注意力适配器相比传统多模态方法更易修改,通过存储视觉与其他模态关系实现权重共享,有效捕捉多模态间关系,克服了多模态数据处理的挑战。
-
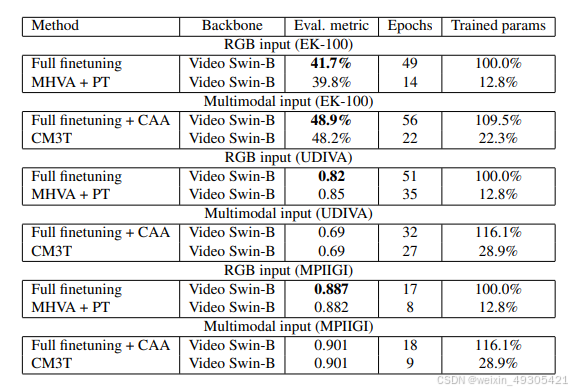
构建有效框架:CM3T框架结合上述技术和前缀调整逼近方法,在多种数据集上仅用少量可训练参数,就达到甚至超越了当前最优模型的性能。
需要论文合集和代码资料的
看我主页【AI学术工坊】

















 2052
2052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









