







【导读】
在人工智能前沿研究中,【Mamba与Transformer】的融合是当下备受瞩目的焦点。
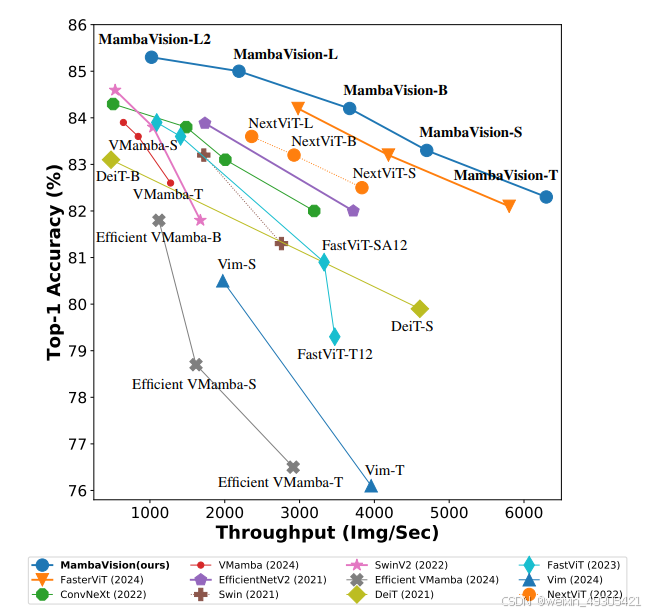
计算机视觉领域,英伟达团队研发的MambaVision成功入选顶级会议CVPR - 2025。其采用分层架构,前两阶段借CNN层快速提取高分辨率特征,后两阶段融合Mamba与Transformer模块Mamba模块经创新改造,将因果卷积替换为常规卷积并新增对称分支。这一设计使MambaVision在Top - 1精度和图像吞吐量上超越同类模型,实现新SOTA。
自然语言处理方面,腾讯发布的Hunyuan - TurboS作为首款超大型混合Transformer - Mamba MoE模型备受关注。它整合Mamba高效处理长序列及Transformer深度理解上下文的优势,解决传统Transformer长文本处理效率瓶颈,在训练优化及奖励系统上也有创新。与以往模型相比,二者创新性地融合Mamba与Transformer,在各自领域独树一帜。
目前该领域研究热度极高,成果众多。我整理了12篇论文能助力读者了解这一前沿趋势,为大家科研和论文写作提供有价值的参考。
【论文】MambaVision: A Hybrid Mamba-Transformer Vision Backbone
1.研究方法
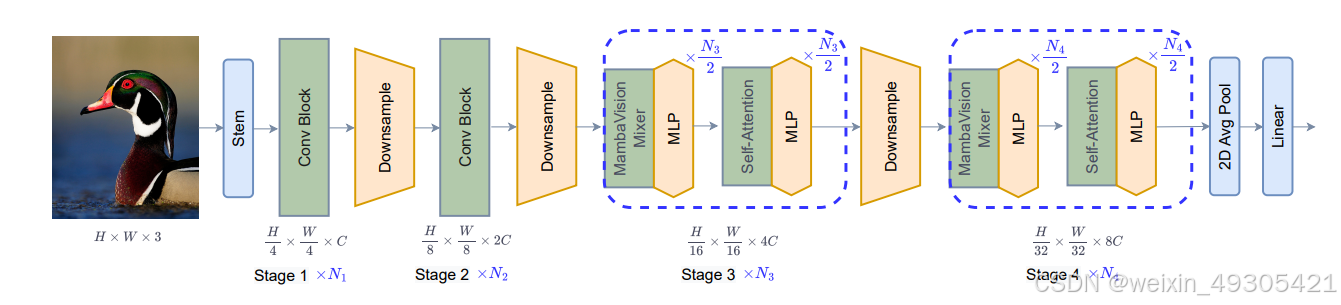
The architecture of hierarchical MambaVision models.
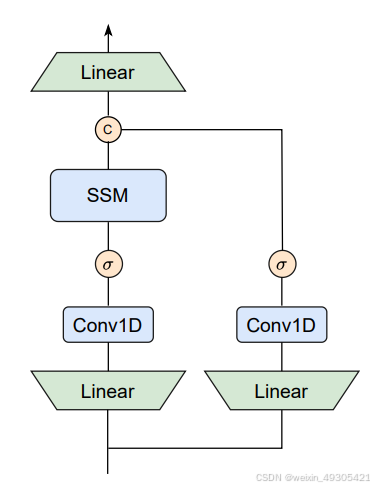
论文提出的MambaVision采用独特的分层架构作为理论方法,共4个阶段。前两个阶段借助基于CNN的层,在高分辨率输入下快速提取特征,其中CNN块遵循特定的残差块公式;后两个阶段集成MambaVision和Transformer模块。图像输入后先转换为重叠补丁并投影到嵌入空间,各阶段间利用批归一化的3×3 CNN层下采样以降低分辨率。微观架构上,重新设计Mamba模块,将因果卷积替换为常规卷积,新增无SSM的对称分支,两者输出连接后投影,同时采用通用多头自注意力机制,以此提升模型在视觉任务中的性能 。
2.论文创新点
-
重新设计Mamba块:改进了原始Mamba架构,使其更适用于视觉任务,在精度和图像吞吐量上优于原始架构。
-
探索混合架构:系统研究了Mamba和Transformer块的集成模式,发现最后阶段融入自注意力块可显著提升捕捉全局上下文和长距离空间依赖的能力。
-
性能优势显著:MambaVision在ImageNet - 1K数据集上,实现了Top - 1准确率和图像吞吐量的SOTA帕累托前沿,超越了基于Mamba、CNN和ViT的模型。在下游任务,如目标检测、实例分割和语义分割中,也优于尺寸相当的骨干网络。
【腾讯Hunyuan-TurboS】首款超大型混合Transformer-Mamba MoE模型震撼发布
1.研究方法
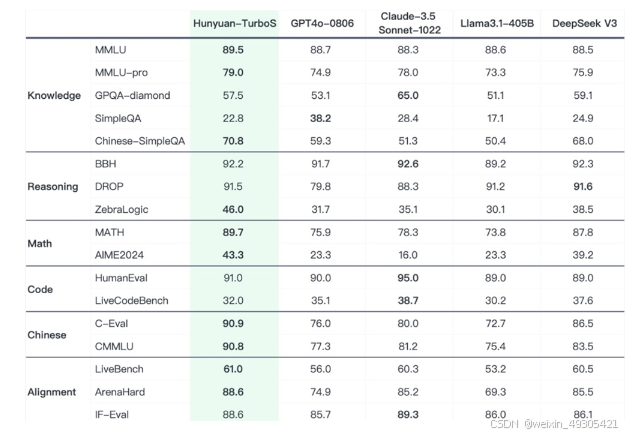 这款混
这款混
-
架构融合:融合Mamba与Transformer,Mamba降低长文本处理复杂度至O(n),减少缓存占用,Transformer负责上下文理解,构建出兼具高效与强理解能力的混合架构,且在超大型MoE模型中无损应用Mamba 。
-
训练优化:引入慢思考集成提升数理推理能力,通过精细化指令调优增强模型与人类需求的契合度,针对英语训练以提升通用性能。
-
奖励升级:用规则评分、代码沙箱反馈及生成式奖励,保障输出质量,提升特定领域准确性,优化问答与创意任务表现 。
2.论文创新点
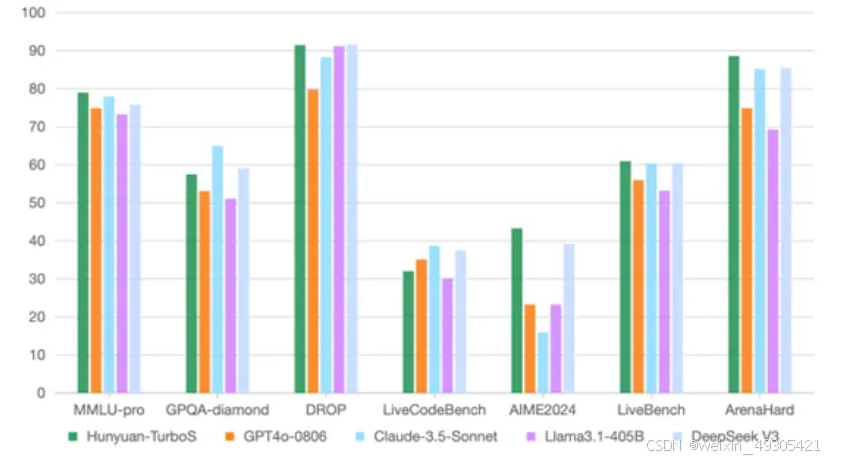
架构创新
-
混合架构:创新性融合Mamba与Transformer,Mamba降低长文本处理复杂度至O(n),Transformer负责强大上下文理解,打造显存与计算效率双优架构。
-
MoE机制:采用动态专家混合机制,在提升模型性能同时,大幅降低长文处理成本超60% 。
训练优化创新
-
慢思考集成:引入慢思考方式,结合混元T1慢思考模型数据,显著提升数学、编程和推理任务表现。
-
指令调优:精细化指令调优,增强模型对齐性与Agent执行能力,更好契合人类需求。
-
英语优化:针对英语训练优化,提升模型通用性能,增强全球场景适用性 。
奖励系统创新
-
规则评分验证:基于规则评分并一致性验证,保障模型输出质量与可靠性。
-
代码沙箱反馈:引入代码沙箱反馈,大幅提升STEM领域输出准确性。
-
生成式奖励:利用生成式奖励优化问答与创意任务,减少奖励作弊 。
需要论文合集和代码资料的
看我主页【AI学术工坊】

















 3225
3225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









