



 介绍一种半监督端到端场景文本识别模型,该模型在SVNH和FSNS数据集上验证,无需提供文本检测的边界框,仅需正确标签。采用STN进行文本检测,结合ResNet进行文本识别。
介绍一种半监督端到端场景文本识别模型,该模型在SVNH和FSNS数据集上验证,无需提供文本检测的边界框,仅需正确标签。采用STN进行文本检测,结合ResNet进行文本识别。
SEE: Towards Semi-Supervised End-to-End Scene Text Recognition
@jxlxt 推荐
#Object Recognition
本文设计了一个端到端的半监督文本检测和识别模型,通过在 SVNH 和 FSNS 数据集上验证了该模型的 work。文章的模型不需要提供文本检测的 bounding box 只需要提供正确的 label,然后通过预测误差反向传播修正文本检测结果。
端到端的模型 loss 设计困难,通常识别只专注于文本检测或文本识别,但本文使用了 STN 来进行文本检测结合 ResNet 进行识别。先通过 STN 检测文本位置,输出特定区域的文本图片后再通过 CNN 识别文本。
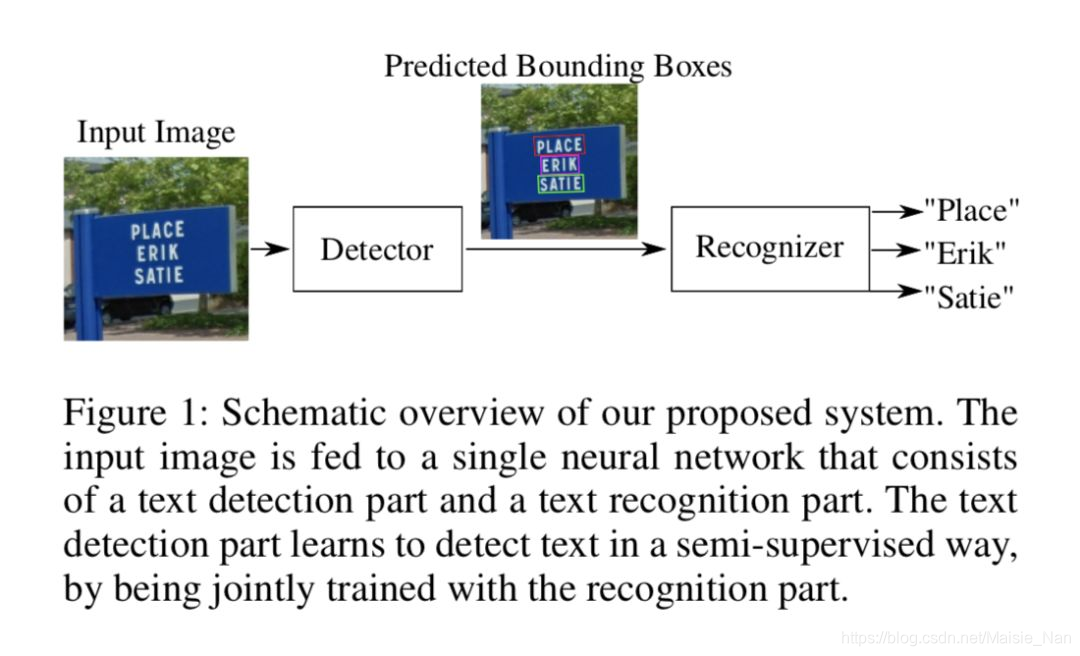
▲ 论文模型:点击查看大图
640
论文链接
https://www.paperweekly.site/papers/2113
源码链接
https://github.com/Bartzi/see
---------------------
作者:Paper_weekly
来源:优快云
原文:https://blog.youkuaiyun.com/c9yv2cf9i06k2a9e/article/details/81255972
版权声明:本文为博主原创文章,转载请附上博文链接!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









