






 博客详细分析了在使用Hadoop MapReduce时遇到的错误,如map和reduce任务未运行、导入错误以及Job执行失败的问题。作者指出,错误源于将`org.apache.hadoop.io.Text`误导入为`javax.xml.soap.Text`。此外,还提到了设置Mapper和Reducer类以及输出Key和Value类型的常见误区。博客提供了解决方案并强调了正确配置作业的重要性。
博客详细分析了在使用Hadoop MapReduce时遇到的错误,如map和reduce任务未运行、导入错误以及Job执行失败的问题。作者指出,错误源于将`org.apache.hadoop.io.Text`误导入为`javax.xml.soap.Text`。此外,还提到了设置Mapper和Reducer类以及输出Key和Value类型的常见误区。博客提供了解决方案并强调了正确配置作业的重要性。
错误显示:map 0% reduce 0%
且在浏览器端并未显示输出文件
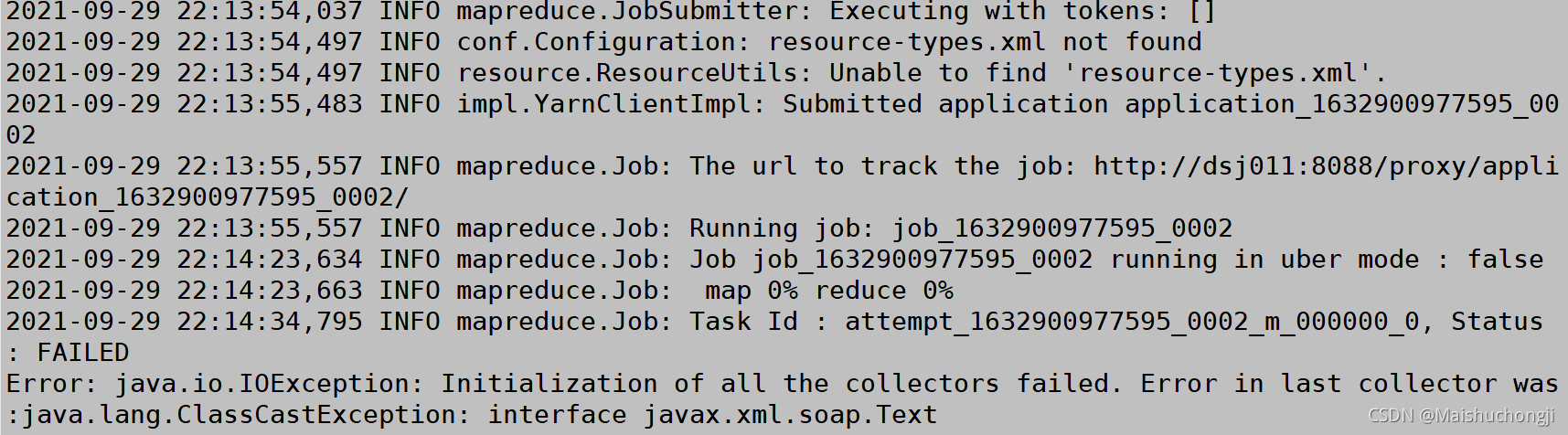
问题分析:map,reduce并未准确运行,原因应该是代码出错
结果:import org.apache.hadoop.io.Text;
import org.junit.Test; //Text打成了Test,我也是个人才QAQ
另外补充:同问题下报Job job_1633174807669_0001 failed with state FAILED due to: Task failed task_1633174807669_0001_m_000000
新手易犯错误:import javax.xml.soap.Text;//导入错误,
应为:
import org.apache.hadoop.io.Text;
附加应注意点:job.setMapperClass(MyMapper.class);
//2. 设置 map
job.setMapperClass(MyMapper.class);
//设置 k2 v2 的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//3. 执行 shuffle的四个步骤,使用系统自带
//4. 设置reduce
job.setReducerClass(MyReduce.class);
//设置 k3 v3
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
map和reduce所调用的k,v方法名称不一样
map带Map
reduce是直接setOutputKeyClass
setOutputValueClass
关于下面的错误;
java.io.IOException: Initialization of all the collectors failed. Error in last collector was:java.lang.ClassCastException: interface javax.xml.soap.Tex
参考这篇文章:
MapReduce运行报错:java.lang.Exception: java.io.IOException: Initialization of all the collectors failed.
以上,
不能分心了QAQ

















 1350
1350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









