



9.2
from scipy.stats import chi2,chisquare,norm
import numpy as np
import pylab as plt
xa=15.0780
s=0.4325
#plt.plot(x,norm.pdf(x,xa,s),s1[0])
#plt.legend()
n=50
k=6
L=[15.0,15.8,15.2,15.1,15.9,14.7,14.8,15.5,15.6,15.3,
15.1,15.3,15.0,15.6,15.7,14.8,14.5,14.2,14.9,14.9,
15.2,15.0,15.3,15.6,15.1,14.9,14.2,14.6,15.8,15.2,
15.9,15.2,15.0,14.9,14.8,14.5,15.1,15.5,15.5,15.1,
15.1,15.0,15.3,14.7,14.5,15.5,15.0,14.7,14.6,14.2]
L1=np.mean(L)
L2=np.std(L)
x1=min(L)
x2=max(L)
x=np.linspace(14.55,15.55,k)
bin=np.hstack([x1,x,x2])
h=plt.hist(L,bin);f=h[0]
p1 = norm.cdf(x, L1, s)
p2 = np.hstack([p1[0], np.diff(p1), 1 - p1[-1]])
print('各区间的频数:',f)
print('各区间概率为:',np.round(p2,4))
ex = n * p2
kf1 = chisquare(f, ex, ddof=2)
kf2 = sum(f ** 2 / (n * p2)) - n
ka = chi2.ppf(0.95, k - 2)
print(kf1); print(round(kf2,4))
各区间的频数: [ 6. 5. 7. 12. 8. 4. 8.]
各区间概率为: [0.1111 0.113 0.1595 0.1825 0.1692 0.1271 0.1376]
9.3
import pandas as pd
import pylab as plt
df =pd.read_excel('data.xlsx', header=None ,skiprows=[0])
print(df)
plt.rc('font',family='SimHei');plt.rc('font',size=16)
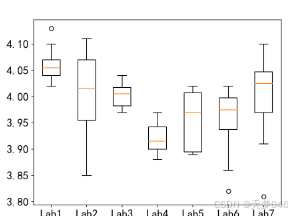
plt.boxplot(df,labels=['Lab1','Lab2','Lab3','Lab4','Lab5','Lab6','Lab7'])
plt.show()
import numpy as np
import pandas as pd
import statsmodels.api as sm
a=pd.read_excel('ti9_3.xlsx',header=None)
b = a.values.flatten()
x = np.tile(np.arange(1, 8), (10, 1)).flatten()
d = {'x': x, 'y': b}
model=sm.formula.ols('y~C(x)',d).fit()
annvat=sm.stats.anova_lm(model)
print(annvat)

9.4
import numpy as np
import statsmodels.api as sm
a=np.loadtxt('ti9_4.txt')
x1=np.tile(np.arange(1,4),(12,1)).T.flatten()
x2 = np.tile(np.hstack([np.ones(3), 2 * np.ones(3), 3 * np.ones(3),
4 * np.ones(3)]), (3, 1)).flatten()
d = {'x1':x1, 'x2':x2, 'y':a.flatten()}
md = sm.formula.ols('y~C(x1) * C(x2)', d).fit()
ano = sm.stats.anova_lm(md)
print(ano)
print('总偏差平方和:', sum(ano.sum_sq))
df sum_sq mean_sq F PR(>F)
C(x1) 2.0 13.166667 6.583333 5.266667 1.269617e-02
C(x2) 3.0 125.000000 41.666667 33.333333 1.009190e-08
C(x1):C(x2) 6.0 68.833333 11.472222 9.177778 2.887221e-05
Residual 24.0 30.000000 1.250000 NaN NaN
总偏差平方和: 236.99999999999915
9.5
import numpy as np
import statsmodels.api as sm
a=np.loadtxt('ti9_5.txt').T
x1 = np.tile(np.hstack([np.ones(4), 2 * np.ones(4), 3 * np.ones(4)]), (4, 1)).flatten()
x2 = np.tile(np.tile([1, 1, 2, 2], (1, 3)), (4, 1)).flatten()
x3 = np.tile(np.tile([1, 2], (1, 6)), (4, 1)).flatten()
d = {'x1':x1, 'x2':x2, 'x3':x3,'y':a.flatten()}
md = sm.formula.ols('y~C(x1) * C(x2) * C(x3)', d).fit()
ano = sm.stats.anova_lm(md)
print(ano)
print('总偏差平方和:', sum(ano.sum_sq))
df sum_sq mean_sq F PR(>F)
C(x1) 2.0 38195.791667 19097.895833 52.174104 2.310582e-11
C(x2) 1.0 18565.333333 18565.333333 50.719180 2.274230e-08
C(x3) 1.0 10034.083333 10034.083333 27.412408 7.298787e-06
C(x1):C(x2) 2.0 3466.541667 1733.270833 4.735174 1.493950e-02
C(x1):C(x3) 2.0 1326.541667 663.270833 1.812009 1.779065e-01
C(x2):C(x3) 1.0 90.750000 90.750000 0.247923 6.215698e-01
C(x1):C(x2):C(x3) 2.0 1191.125000 595.562500 1.627035 2.106302e-01
Residual 36.0 13177.500000 366.041667 NaN NaN
总偏差平方和: 86047.66666666663

















 3450
3450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









