







目录
论文介绍
题目:
Dilated Convolutional Transformer for High-Quality Image Deraining
论文地址:
创新点
论文提出了一种名为Dilated Convolutional Transformer 的高效图像去雨方法,通过结合扩张卷积和Transformer架构,扩大了网络的感受野并生成了丰富的上下文特征表示,从而在图像去雨任务中实现了高质量的图像重建。
- 结合CNN和Transformer:
- 该研究提出了一种有效的去雨方法,即Dilated Convolutional Transformer(DCT),它结合了卷积神经网络(CNN)和Transformer的属性,以提高图像去雨的性能。
- 扩大感受野:
- DCT通过使用扩张卷积操作来扩大网络的感受野,从而聚合全局信息,这有助于提高图像质量。
- Dilform Block:
- DCT的核心是dilform block,它包含两个精心设计的组件:multi-dilconv sparse attention(MDSA)和multi-dilconv feedforward network(MDFN)。
- MDSA(Multi-Dilconv Sparse Attention):
- MDSA通过计算多尺度查询来生成准确的相似性图,以便更好地利用丰富的多尺度信息进行高质量图像重建。
- MDFN(Multi-Dilconv Feedforward Network):
- MDFN旨在更好地整合不同尺度的雨信息,在特征转换中发挥作用。
- 激活函数的改进:
- 为了在Transformer中加强稀疏性,文章采用了ReLU激活函数来替代原始的softmax函数,以实现更好的特征聚合。
- 多尺度融合:
- 该模型设计了基于多尺度融合的新型MDFN,充分利用雨信息来丰富层级间的特征转换。
方法
模型总体架构
输入输出:
模型接收雨迹图像作为输入,并输出去雨后的干净图像。
网络结构:
模型由多个编码器和解码器单元组成,这些单元堆叠在一起,用于提取雨迹分布的特征。
特征连接:
通过跳跃连接将编码器和解码器的特征结合起来,帮助恢复干净的图像。
核心组件:
模型的核心是dilform块,它包含两个主要部分:
- MDSA:用于从全局范围内聚合特征。
- MDFN:用于处理和整合不同尺度的雨迹信息。
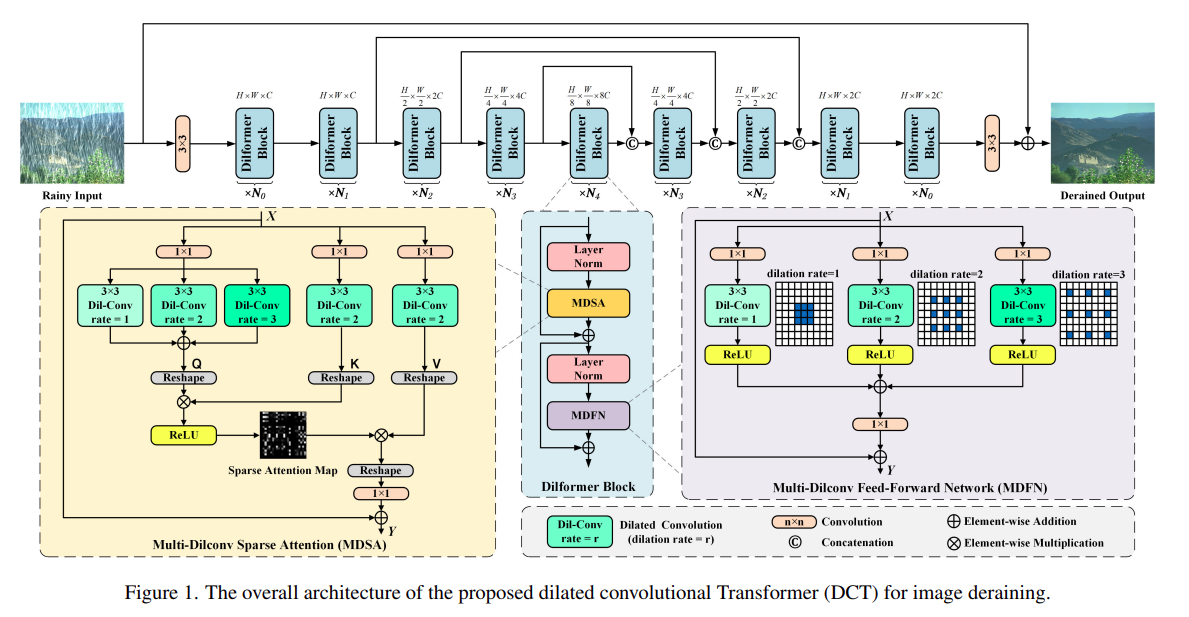
核心模块描述
1. Multi-Dilconv Sparse Attention (MDSA)
MDSA模块的目的是从全局范围内聚合特征,以帮助模型更好地理解和去除图像中的雨迹。这个模块的关键特点包括:
-
多尺度查询:MDSA通过使用不同扩张率的扩张卷积来计算多尺度查询,这样可以在不同尺度上捕捉图像的特征,增强模型对不同大小雨迹的识别能力。
-
相似性聚合:通过计算查询和键之间的相似性,MDSA能够识别出哪些特征是相关的,从而更有效地聚合全局信息。
-
稀疏注意力机制:MDSA使用ReLU激活函数替代传统的softmax函数,这样做可以强化模型的稀疏性,即只关注那些最重要的特征,从而提高特征聚合的效果。
2. Multi-Dilconv Feedforward Network (MDFN)
MDFN模块旨在增强模型对局部雨迹的表征能力,并整合不同尺度的雨迹信息。这个模块的关键特点包括:
-
多尺度特征融合:MDFN通过使用不同扩张率的扩张卷积来处理特征,这样可以在不同尺度上捕捉雨迹的细节,增强模型对局部雨迹的识别和处理能力。
-
扩张卷积的应用:通过随机选择不同的扩张率,MDFN能够在不增加额外模块的情况下自动扩展网络的感受野,这对于去除不同形态的雨迹非常重要。
-
非线性变换:MDFN允许数据在每个token上进行非线性变换,这有助于模型捕捉更复杂的雨迹特征,并提高去雨效果。
这两个核心模块共同工作,使得DCT模型能够有效地结合局部和全局信息,实现高质量的图像去雨效果。MDSA负责聚合全局特征,而MDFN则专注于处理和整合局部特征,两者的结合使得模型在去雨任务上表现出色。
即插即用模块作用
MDSA(Multi-Dilconv Sparse Attention)和MDFN(Multi-Dilconv Feedforward Network)这两个模块由于其设计特性,可以适用于以下类型的任务和网络结构中,特别是在需要特征融合、多尺度处理和增强模型感受野的场景中:
适用任务:
-
图像恢复:
- 图像去雨、去雾、去噪、超分辨率等任务,这些任务需要模型能够理解和处理图像中的复杂细节。
-
语义分割:
- 在语义分割中,特征融合可以帮助模型更好地理解图像内容,提高分割的准确性。
-
目标检测:
- 特征融合可以增强目标的表示,尤其是在处理小目标或遮挡目标时。
-
图像分类:
- 尤其是在处理需要全局和局部信息结合的复杂分类任务时。
-
图像生成:
- 如风格迁移、图像到图像的转换等,这些任务需要模型能够捕捉和融合不同尺度的特征。
适用结构:
-
编码器-解码器结构:
- 这种结构常用于图像恢复任务,MDSA和MDFN可以作为编码器或解码器的一部分,增强特征提取和融合能力。
-
U-Net结构:
- U-Net结构广泛应用于医学图像分割等领域,MDSA和MDFN可以集成到U-Net的下采样和上采样路径中,提升特征融合效果。
-
Transformer结构:
- 由于MDSA和MDFN具有处理多尺度特征的能力,它们可以与Transformer结构结合,增强其处理图像的能力。
-
卷积神经网络(CNN):
- 传统的CNN结构可以通过集成MDSA和MDFN模块来增强其特征提取和融合的能力,尤其是在需要处理多尺度信息的任务中。
-
注意力机制网络:
- 任何依赖于注意力机制来提升性能的网络结构,MDSA可以作为一个增强的注意力模块,提供更有效的特征聚合。
-
多尺度处理网络:
- 需要处理不同尺度特征的网络,如多尺度特征融合网络,MDFN可以作为一个核心组件来增强模型的多尺度处理能力。
总的来说,MDSA和MDFN模块的灵活性和多功能性使它们可以集成到多种不同的网络结构中,以提升模型在处理视觉任务时的性能。
消融实验结果
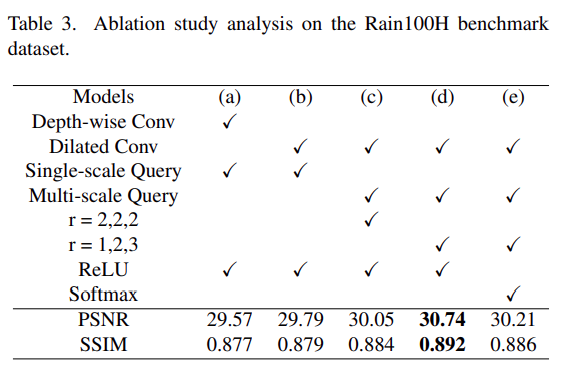
- 消融实验部分主要验证了Dilated Convolutional Transformer(DCT)模型中不同组件和设计选择对性能的影响。实验对比了深度卷积与扩张卷积、单尺度与多尺度查询、相同与不同扩张率以及ReLU与Softmax激活函数的效果。
- 通过这些对比,实验发现DCT模型的每个设计选择都对提高去雨性能有积极作用,其中最优配置在Rain100H数据集上展现了最好的PSNR和SSIM评分。这些结果支持了DCT模型设计的有效性,并展示了模型在实际去雨任务中的优越性能。


















 1802
1802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









