







ResNet与注意力机制结合,是当前的研究热点。其不仅能提高模型的性能,还能提升模型的解释性和泛化能力。具体来说:ResNet独特的残差连接结构,解决了深度神经网络中的梯度消失和爆炸问题,使网络能构建得更深、更复杂。而注意力机制的动态分配权重特点,则使ResNet能够更准确地识别和利用任务相关的特征,从而提高模型的准确性。目前,该思路在图像分类、目标检测、语义分割、情感分析、医学影像等领域,都取得了显著成功!比如CVPR的SpikingResformer模型,性能和能效方面都远超SOTA;Nature子刊的Journal,则在准确率高达99.48%的同时,计算时间降低43.24%
论文介绍1
题目:
InceptionCapsule: Inception-Resnet and CapsuleNet with self-attention for medical image Classification
论文地址:
链接: https://arxiv.org/pdf/2402.02274
创新点
方法
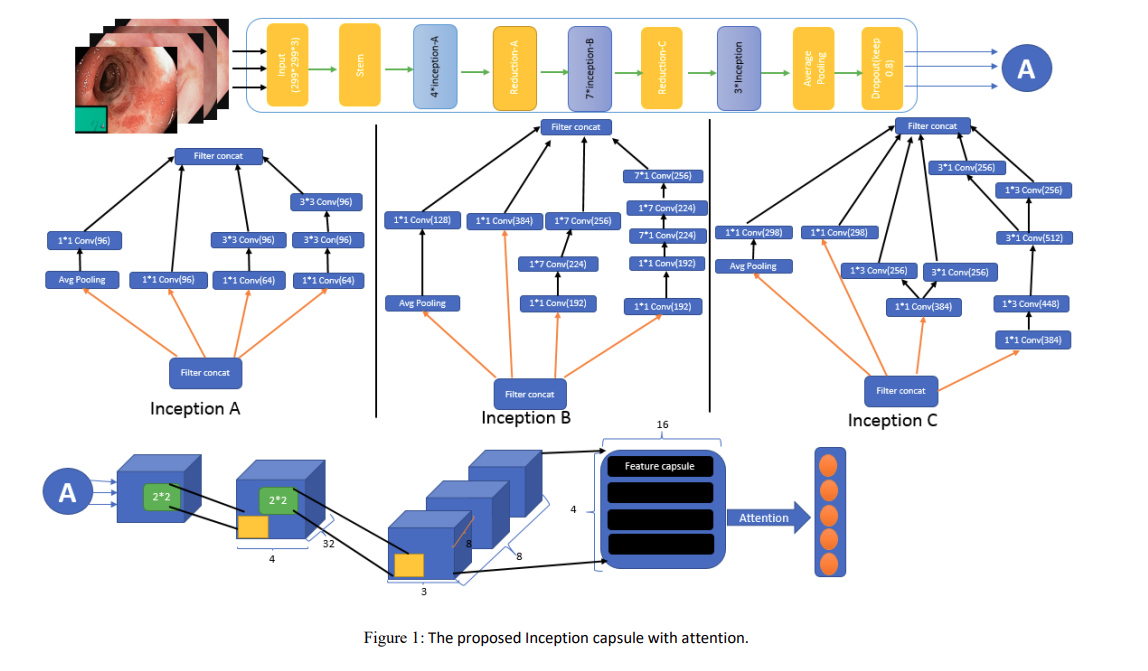
InceptionCapsule模型的总体架构可以概括为以下几个关键部分:
-
Inception-ResNet层:这是模型的基础特征提取部分,它使用不同大小的卷积核(如 3 ∗ 3 3*3 3∗3和 5 ∗ 5 5*5 5∗5)同时进行多种卷积操作,然后将这些操作的结果连接起来。这一部分利用从ImageNet预训练的权重,以避免随机权重初始化的问题。
-
胶囊层(Capsule Layer):Inception-ResNet层提取的特征向量被送入胶囊层,胶囊层由一组神经元组成,这些神经元的激活向量表示特定特征的存在概率。胶囊层将标量特征转换为向量值胶囊,以捕获输入序列的特征。
-
自注意力层(Self-Attention Layer):在胶囊层之后,模型引入自注意力机制,以选择和强调图像中最显著的特征部分。这一机制通过加权组合所有编码的输入向量,为解码器提供最相关的输入序列部分。
-
分类层(Classification Layer):自注意力层的输出被送入一个全连接层,该层将特征映射到特定类别的概率上。使用Softmax函数来计算每个类别的概率。
整个架构的设计旨在通过结合深度特征提取(Inception-ResNet)和胶囊网络的强有力特征表示能力,以及自注意力机制对特征选择的优化,来提高医学图像分类的准确性。这种结构使得模型能够有效地处理和分类复杂的医学图像数据。
论文介绍2
题目:
ResNeSt: Split-Attention Networks
论文地址:
链接: https://arxiv.org/pdf/2004.08955
创新点
论文介绍了一种名为ResNeSt的新型卷积神经网络架构,它通过结合通道注意力机制和多路径表示,提出了一个简单的多分支架构,能够在不同网络分支间应用通道-wise注意力,以增强特征图注意力和多路径表示的互补优势。ResNeSt在多个计算机视觉任务中通过学习更丰富的网络表示来提升性能,其设计空间直接改善了现有网络架构,如RegNet-Y和FBNetV2,并在准确性和延迟的权衡上超越了EfficientNet。
方法
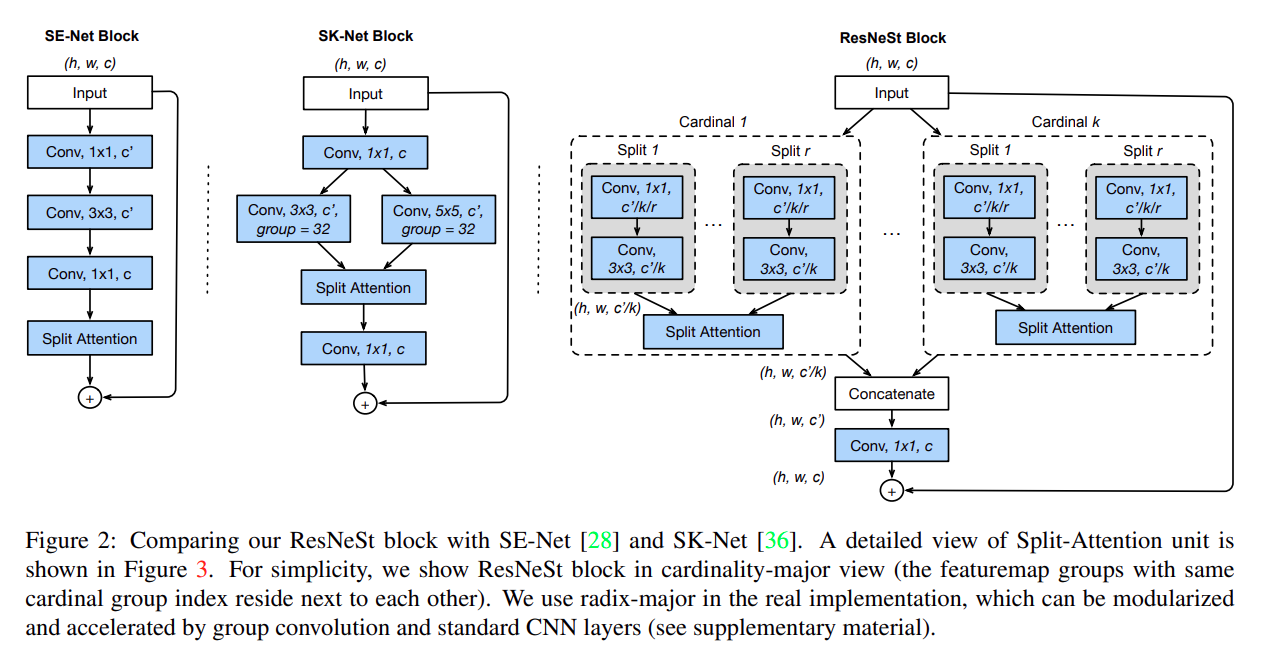
整体架构
ResNeSt结合了通道注意力机制和多路径表示,通过在一个统一的Split-Attention块中实现,以提高视觉识别的性能。以下是该架构的关键特点:
Split-Attention Block(分裂注意力块):这是ResNeSt的核心计算单元,它将特征图分成多个组(cardinal groups),并在每个组内应用一系列的变换(如卷积),然后通过通道注意力机制对这些变换的结果进行融合。
通道注意力:ResNeSt在每个cardinal组内应用通道注意力机制,这允许网络自适应地调整每个通道的特征响应,增强跨通道特征的相关性。
多路径表示:受到Inception模型的启发,ResNeSt通过将输入分割成多个低维嵌入,然后通过不同集合的卷积滤波器进行变换,最后通过连接合并,来捕获独立的特征。
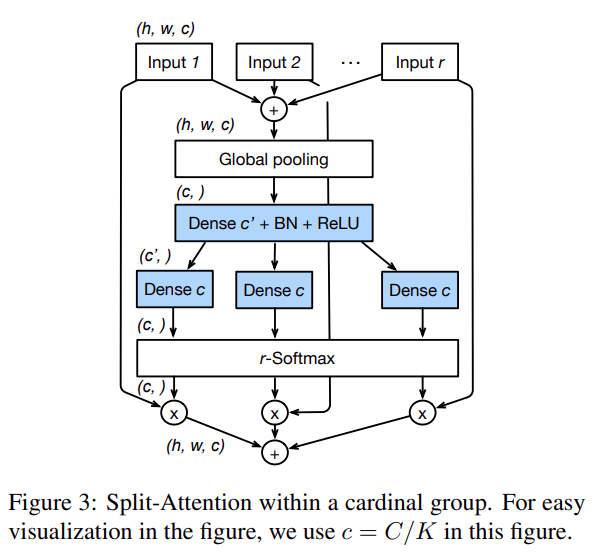
分裂注意力机制
ResNeSt架构中Split-Attention Block的一个组成部分,也就是cardinal group内的分裂注意力机制的工作原理如下。
-
输入特征图:这是进入Split-Attention Block之前的特征图,它包含了图像的高维数据。
-
全局池化:对每个cardinal group的特征图进行全局平均池化,这样可以得到每个通道的整体统计信息,而不是局部信息。
-
密集层:使用两个全连接层来处理全局池化后的数据,第一个全连接层后面跟着一个非线性激活函数,第二个全连接层输出每个通道的注意力系数。
-
r-Softmax:这是一个softmax操作,它计算每个split的注意力权重,这里的r指的是在cardinal group内split的数量。
-
加权融合:根据计算出的注意力权重,对不同split的特征进行加权组合。这样,对于每个通道,都会结合多个split的信息来形成一个综合的特征表示。
-
输出特征图:经过加权融合后,得到最终的cardinal group特征图,这个特征图会作为输出,用于后续的处理。
简而言之,在一个cardinal group内实现分裂注意力机制,通过全局池化和全连接层计算注意力权重,然后使用这些权重对特征进行加权融合,以突出重要特征并抑制不重要的特征。这个过程使得网络能够更有效地处理图像数据,提高了特征的表达能力。
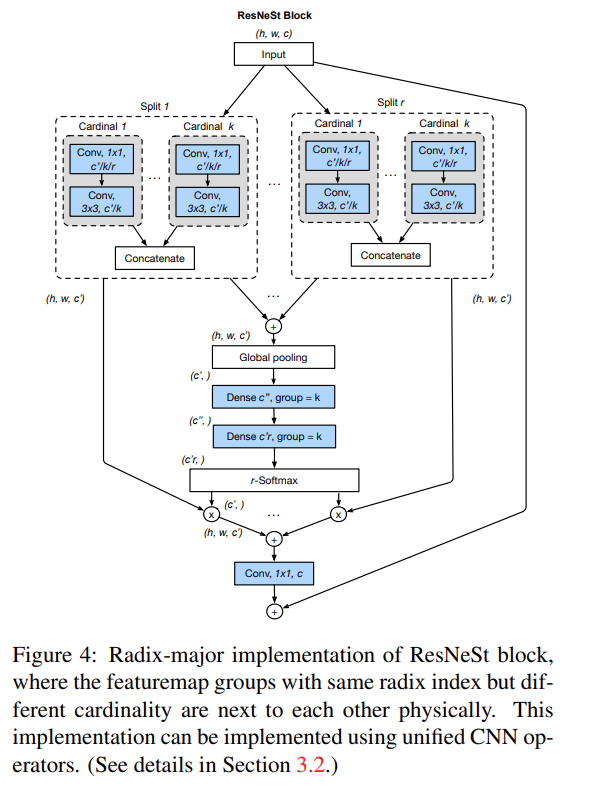
Split-Attention Block
ResNeSt架构中的Split-Attention Block在radix-major布局下的实现方式。这里的radix-major布局是指将具有相同radix索引的特征组物理地放在一起。以下是该布局中的关键步骤和组件:
输入特征图分割:输入特征图首先被分割成多个组,每个组都有一个cardinality索引和radix索引。
组内变换:每个组会经过一系列变换,比如1x1和3x3的卷积,这些变换在不同的组中可能是不同的。
组间融合:通过元素级求和的方式,将具有相同cardinality索引但不同radix索引的特征图组融合在一起。
全局池化:在空间维度上应用全局池化层,同时保持通道维度分离。这相当于对每个cardinality组单独进行全局池化,然后将结果拼接起来。
注意力权重计算:在全局池化之后,使用两个连续的全连接层来预测每个split的注意力权重。这里的全连接层是分组进行的,意味着每组都会单独计算注意力权重。
输出特征图合并:最后,将所有处理过的特征组合并,形成最终的输出特征图。
图4中的布局使得Split-Attention Block可以通过标准的CNN操作进行模块化,提高了计算效率。这种布局允许使用统一的CNN操作来处理不同的特征组,使得模型训练和推理更加高效。


















 195
195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









