




一、Transformer架构:大模型的基石
1. 自注意力机制数学原理
核心公式:
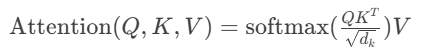
物理意义:通过计算词向量间的相关性权重,动态捕捉远距离依赖。相比CNN/RNN,突破了局部感受野限制。
2. 位置编码的工程实现
主流方案对比:

旋转位置编码(RoPE)示例:
Python
# 简化版RoPE实现
def apply_rope(q, k, pos_ids):
angle = 1.0 / (10000 ** (torch.arange(0, d_model, 2) / d_model))
sin = torch.sin(pos_ids * angle)
cos = torch.cos(pos_ids * angle)
q_rot = q * cos + rotate_half(q) * sin
k_rot = k * cos + rotate_half(k) * sin
return q_rot, k_rot 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2770
2770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











