



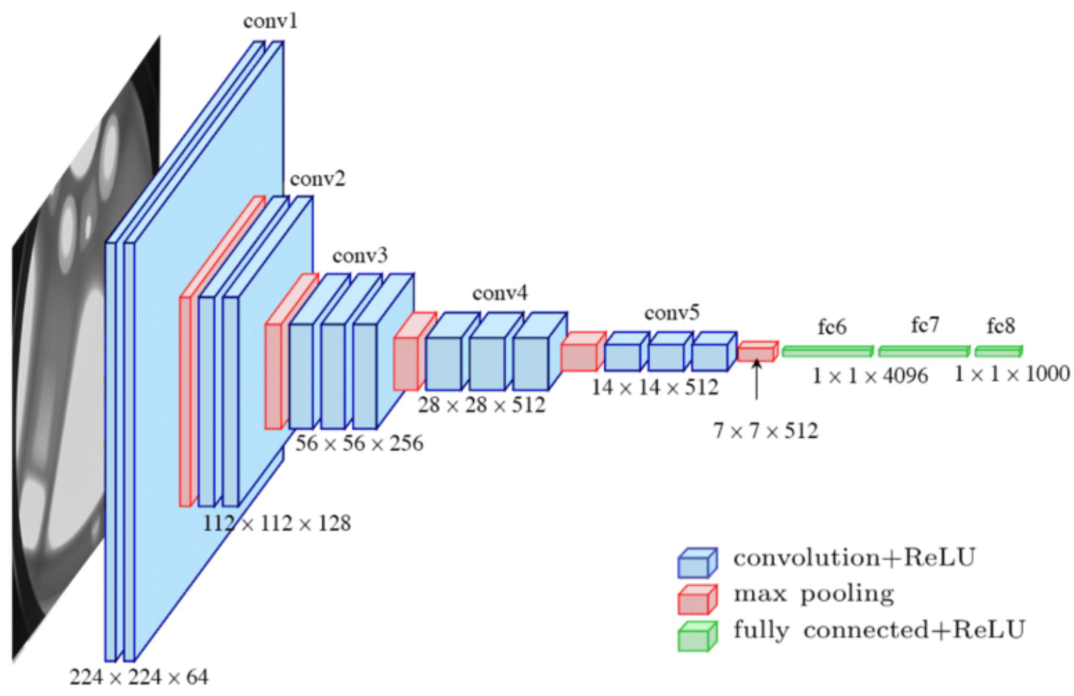
一. 卷积神经网络概述
1.1 CNN的核心价值
卷积神经网络(CNN)通过局部感知和权值共享两大特性,成为计算机视觉领域的基石:
-
局部感知:模仿生物视觉皮层,仅关注局部区域(如3×3窗口)
-
权值共享:同一卷积核在全图滑动,大幅减少参数量(AlexNet比全连接网络参数少60倍)
典型应用:
-
图像分类(ImageNet Top-5准确率从71.8%提升至99.3%)
-
目标检测(YOLO系列)
-
医学影像分析(病理切片识别)
二. 卷积操作详解
2.1 数学定义
离散卷积计算:
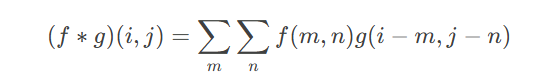
其中:
-
ff:输入图像
-
gg:卷积核(滤波器)
2.2 图像处理实例
边缘检测卷积核:
Markup
Sobel_x = [[-1, 0, 1],
[-2, 0, 2],
[-1, 0, 1]]
代码示例:OpenCV实现边缘检测
Python
import cv2
import numpy as np
img = cv2.imread('cat.jpg', 0) # 灰度图
sobel_x = np.array([[-1,0,1], [-2,0,2], [-1,0,1]])
edges = cv2.filter2D(img, -1, sobel_x)
cv2.imwrite('edges.jpg', edges)
三. CNN架构解析
3.1 卷积层(Convolutional Layer)
核心参数:
-
输入通道数(in_channels)
-
输出通道数(out_channels)
-
卷积核尺寸(kernel_size)
代码示例:PyTorch实现
Python
import torch.nn as nn
conv_layer = nn.Conv2d(
in_channels=3, # 输入通道(RGB图像)
out_channels=64, # 输出特征图数量
kernel_size=3, # 3x3卷积核
stride=1, # 步长
padding=1 # 边缘填充
)
# 输入尺寸:(batch_size, 3, 224, 224)
output = conv_layer(input_tensor)
print(output.shape) # torch.Size([batch_size, 64, 224, 224])
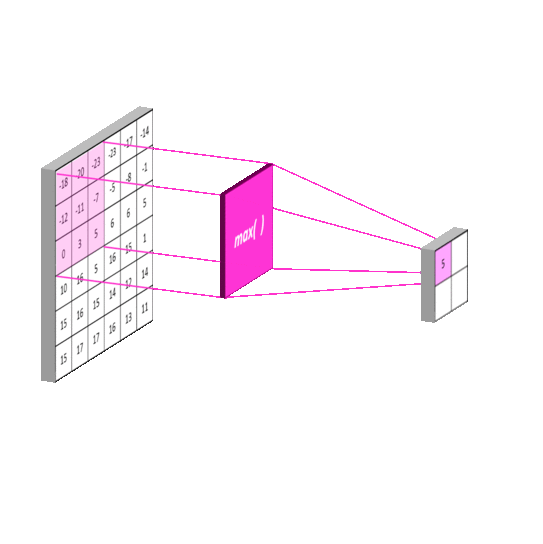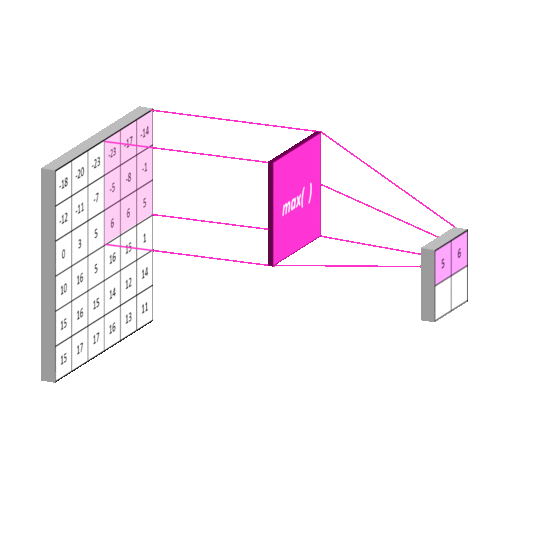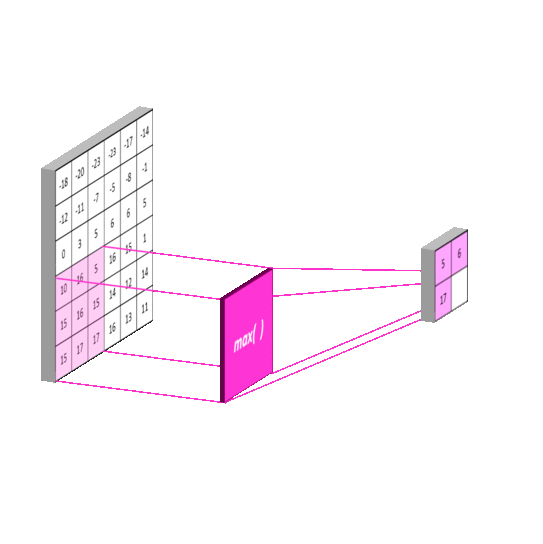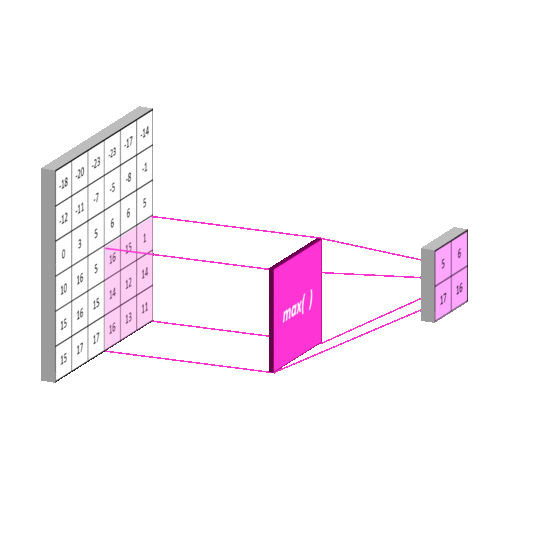
3.2 池化层(Pooling Layer)
最大池化操作:
Markup
输入矩阵: 输出矩阵:
[[1, 2, 3, 4], [[4, 4],
[5, 6, 7, 8], [8, 8]]
[9, 10,11,12],
[13,14,15,16]]
窗口大小2×2,步长2
代码示例:池化层实现
Python
pool_layer = nn.MaxPool2d(kernel_size=2, stride=2)
output = pool_layer(input_tensor) # 尺寸减半
四. CNN超参数调优
4.1 卷积核尺寸(Kernel Size)
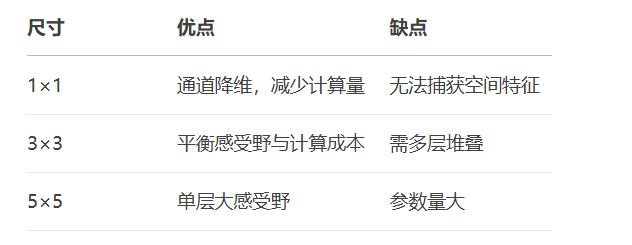
4.2 步长(Stride)
输出尺寸公式:

对比实验:
-
Stride=1:保留更多细节,计算量大
-
Stride=2:快速降维,可能丢失信息
4.3 填充(Padding)
-
Valid:不填充,输出尺寸缩小
-
Same:填充使输出尺寸不变
Python
# 计算所需填充量
padding = (kernel_size - 1) // 2
4.4 卷积核数量
-
浅层:64-128个(捕获基础边缘/纹理)
-
深层:512-1024个(捕获高级语义特征)
五. 感受野(Receptive Field)
5.1 定义与计算
感受野表示输入像素对输出特征的可见区域。递推公式:
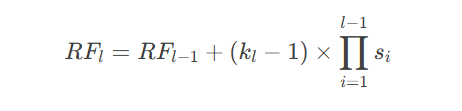
其中:
-
klkl:第ll层卷积核尺寸
-
sisi:第ii层步长
案例:
-
3×3卷积,stride=1,堆叠3层 → 最终感受野7×7
-
3×3卷积,stride=2,堆叠3层 → 最终感受野15×15
5.2 重要性分析
-
目标检测:需覆盖目标物体尺度(如YOLO设计不同感受野分支)
-
医学影像:小病灶需要小感受野精细定位
六. CNN参数效率揭秘
6.1 权值共享
传统MLP全连接层参数量:
784×256=200,704
CNN卷积层参数量(3×3核,64通道):
3×3×3×64=1,728
6.2 局部连接
-
全连接:每个神经元连接全部输入
-
卷积层:每个神经元仅连接局部区域
参数减少比例:
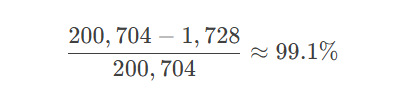
附:完整训练代码模板
Python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 加载MNIST数据集
train_set = datasets.MNIST('data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)
# 定义LeNet-5
class LeNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*4*4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = self.pool(torch.relu(self.conv2(x)))
x = x.view(-1, 16*4*4)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
# 训练配置
model = LeNet()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练循环
for epoch in range(10):
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}, Loss: {loss.item():.4f}')
注:本文代码基于PyTorch 2.0实现,运行前需安装:
Bash
pip install torch torchvision matplotlib
学习书籍文档
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

学习视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。
项目实战源码
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。
大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。



















 6287
6287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











