




 该文介绍了一种使用BERT进行序列标注的方法,包括数据下载、相邻句子构造、掩码处理以及输入句子的pad操作。通过构建监督学习模型,对文本进行预处理,以训练BERT模型来预测句子是否相邻。掩码处理步骤中,80%的词汇被掩码,10%保持不变,10%随机替换。最后,对输入序列进行填充以适应模型输入要求。
该文介绍了一种使用BERT进行序列标注的方法,包括数据下载、相邻句子构造、掩码处理以及输入句子的pad操作。通过构建监督学习模型,对文本进行预处理,以训练BERT模型来预测句子是否相邻。掩码处理步骤中,80%的词汇被掩码,10%保持不变,10%随机替换。最后,对输入序列进行填充以适应模型输入要求。
一、将数据下载下来
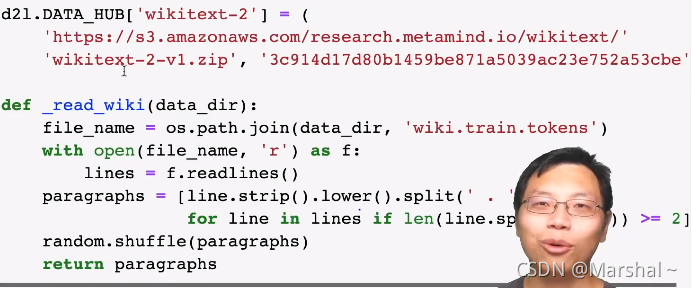
二、构造相邻句子token_a和token_b
百分之五十是下一个句子。
百分之五十是随机拼接的来自文章的句子。
这里已经知道正确答案is_next为true或false

利用上面的函数构建循环在文章中构建token_a和token_b,这时候我们已经知道他们是不是相邻的,我之后可以用bert做预测实现监督学习
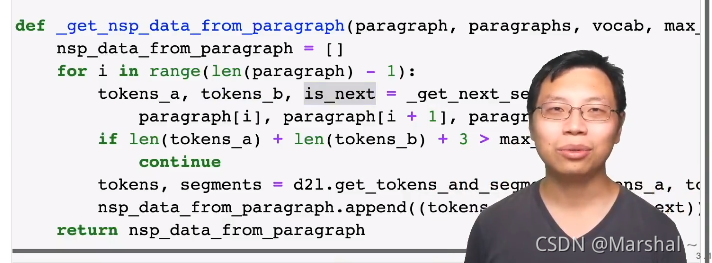
进一步对token_a和token_b进行掩码处理,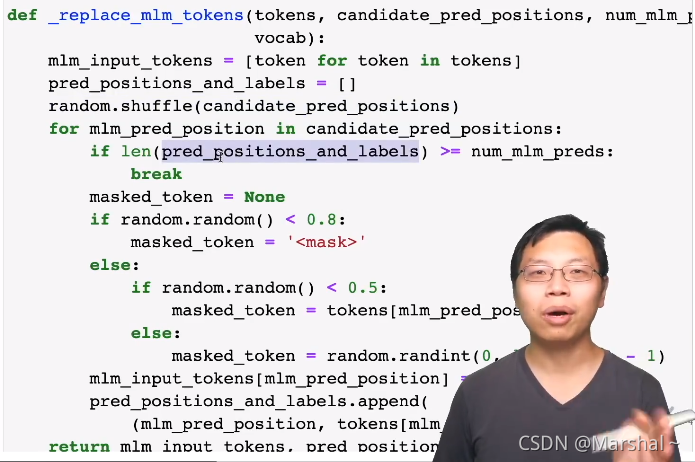
三、继续构造输入:进行掩码
(1)就是不断的地进行构造,直到长度大于等于原句子,这也就代表全部转化完成。
(2)百分之八十转化为掩码,百分之十保持不变,百分之十随机替换
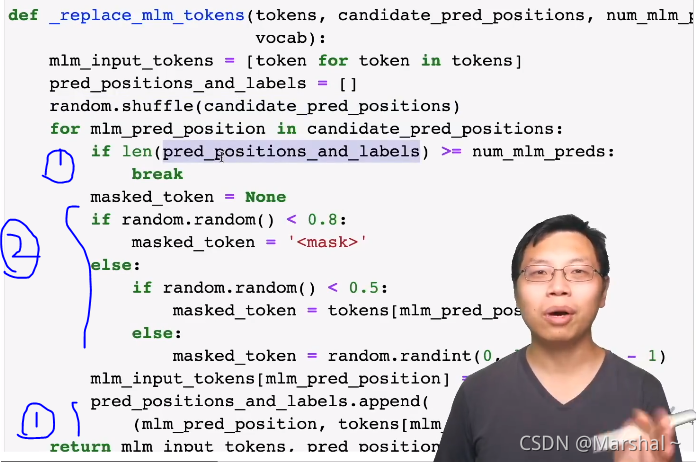
下面就是对全文进行mask掩码,调用上面的函数。首先去掉标签取出全部文本。输入到上面函数中去,对文本进行mask

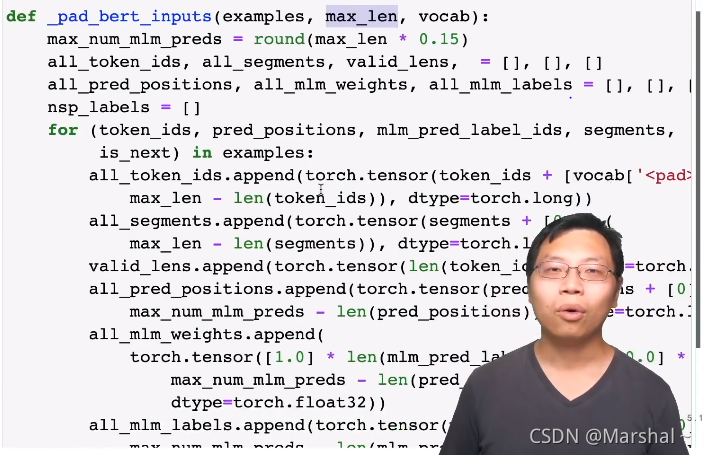
四、对输入句子进行pad
就是把有些短句子加入当然segment也要加[0]以及随之而来的一些修改:pred_positions把输入的模型长度增加、修改mlm信息(未详细看)

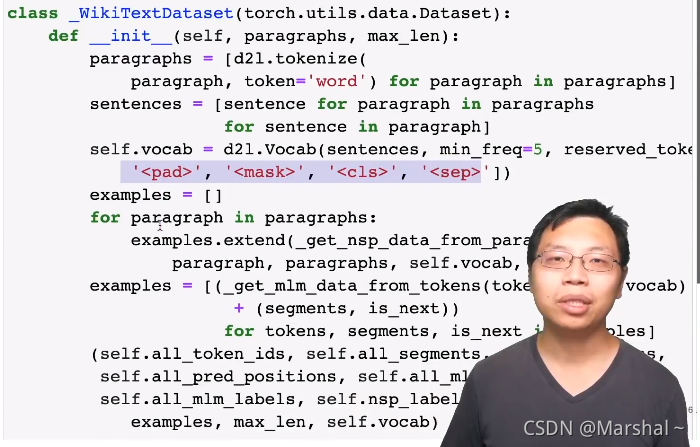
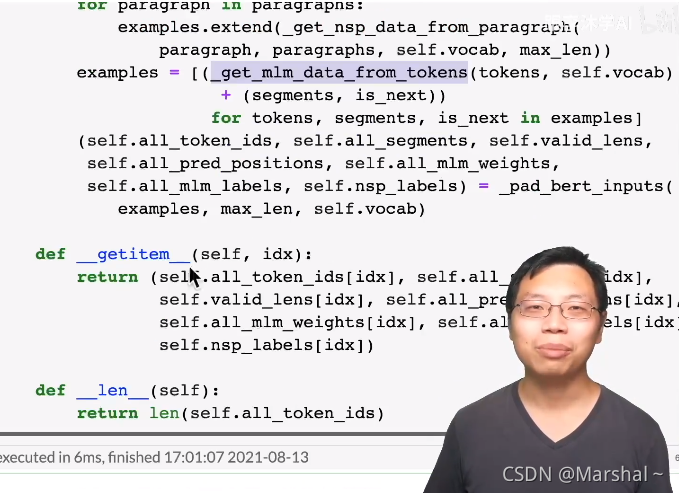
五、使用以上函数构造dataset

















 1136
1136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









