




梯度提升概述
要理解 boosting,我们首先理解集成学习,为了获得更好的预测性能,集成学习结合多个模型(弱学习器)的预测结果。它的策略就是大力出奇迹,因为弱学习器的有效组合可以生成更准确和更鲁棒的模型。集成学习方法分为三大类:
- Bagging:该技术使用随机数据子集并行构建不同的模型,并聚合所有预测变量的预测结果。
- Boosting:这种技术是可迭代的、顺序进行的和自适应的,因为每个预测器都是针对上一个模型的错误进行修正。
- Stacking:这是一种元学习技术,涉及结合来自多种机器学习算法的预测,例如 bagging 和 boosting。
提升方法(Boosting):主要思想为,把多个高偏差的弱学习器组合利用起来,降低整体偏差,形成一个强学习器
梯度提升机(Gradient Boosting Machine,GBM)是 Boosting 的一种实现方式,让新的分类器拟合负梯度来降低偏差
系统梳理GBM相关
GBDT
梯度提升决策树(Gradient Boosting Decision Tree,GBDT)是 GBM + CART。CART 作为 GBM 的基模型,GBM 做为 CART 的集成方法。
CART决策树
决策树原理
采用基尼系数来进行定义一个系统中的失序现象,即系统的混乱程度(纯度)。基尼系数越高,系统越混乱(不纯)。建立决策树的目的就是降低系统的混乱程度,降低基尼系数。
基尼系数计算公式如下:
g i n i ( T ) = 1 − ∑ p i 2 gini(T)=1-\sum p_i^2 gini(T)=1−∑pi2
其中pi为类别i在样本T中出现的频率,即类别为i的样本占总样本个数的比率。
在分类问题中,决策树模型会优先选择使得整个系统的基尼系数下降最大的划分方式来进行节点划分。划分后的基尼系数为各部分基尼系数的样本数量加权平均值。
在回归问题中,决策树一般使用均方误差MSE作为其划分标准
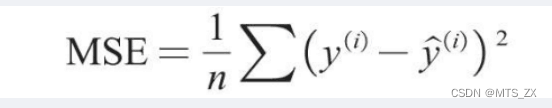

catboost算法
CatBoost是一种基于对称决策树(oblivious trees)为基学习器实现的参数较少、支持类别型变量和高准确性的GBDT框架,主要解决的痛点是高效合理地处理类别型特征,CatBoost是由Categorical和Boosting组成。此外,CatBoost还解决了梯度偏差(Gradient Bias)及预测偏移(Prediction shift)的问题,从而减少过拟合的发生,进而提高算法的准确性和泛化能力。
它自动采用特殊的方式处理类别型特征(categorical features)。首先对categorical features做一些统计,计算某个类别特征(category)出现的频率,之后加上超参数,生成新的数值型特征(numerical features)。这也是这个算法最大的motivtion,有了catboost,再也不用手动处理类别型特征了。
catboost还使用了组合类别特征,可以利用到特征之间的联系,这极大的丰富了特征维度。
采用ordered boost的方法避免梯度估计的偏差,进而解决预测偏移的问题。
catboost的基模型采用的是对称树,同时计算leaf-value方式和传统的boosting算法也不一样,传统的boosting算法计算的是平均数,而catboost在这方面做了优化采用了其他的算法,这些改进都能防止模型过拟合。
主要特点
对称决策树
在每一步中,前一棵树的叶子都使用相同的条件进行拆分。选择损失最低的特征分割对并将其用于所有级别的节点。这种平衡的树结构有助于高效的 CPU 实现,减少预测时间,模型结构可作为正则化
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 928
928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









