




提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
单链表是一种基础且重要的数据结构,广泛应用于程序设计和算法实现中。它由一系列节点组成,每个节点包含数据域和指向下一个节点的指针域。相比于数组,单链表在内存使用上更加灵活,能够高效地进行插入和删除操作,但访问元素的时间复杂度较高。理解单链表的定义和创建方法,是掌握更复杂数据结构(如双链表、树、图)的前提。在下文,我会细讲单链表的定义和创建,同时也会给大家说明链表和数组的区别,文章略长,希望大家耐心看下去。欢迎各位的学习和批评纠正,谢谢。
一、链表的定义
以下是百度百科给出的定义:链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。 相比于线性表顺序结构,操作复杂。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而线性表和顺序表相应的时间复杂度分别是O(logn)和O(1)。
简而言之,它是一种常见的线性数据结构,通过每个节点储存数据,并通过指针相连接,它是动态的,分散的,由独立数据结点进行连接的线性结构,可以动态的进行插入、删除等操作。
我们可以用图片形式来解读一下单链表:
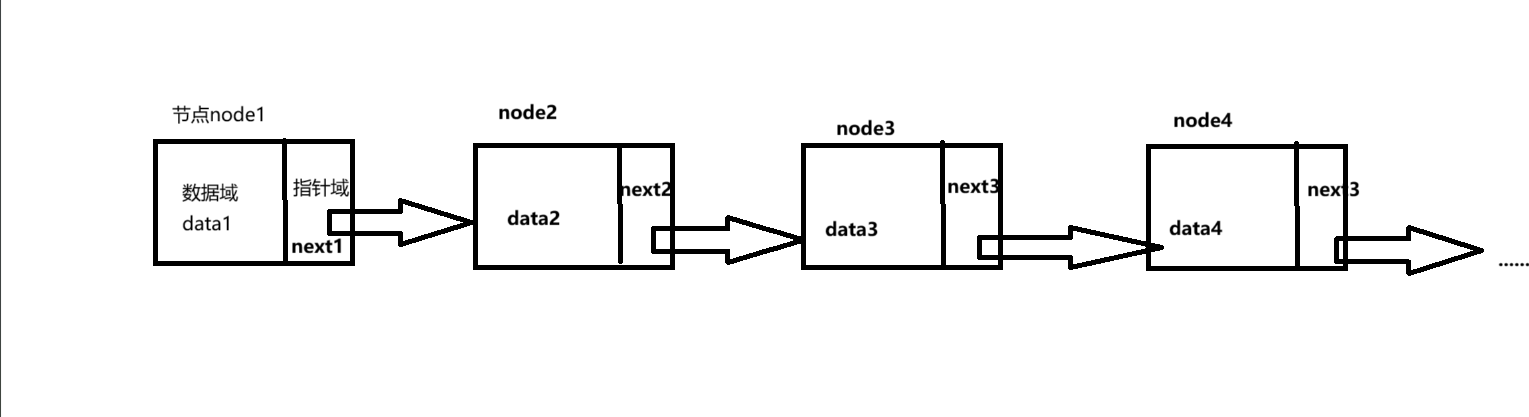
上图是一个简单的单链表,链表由节点node1,node2,node3,node4......组成,而每个节点由两部分组成,分别为数据域data i(i=1,2,3...)和指针域next i(i=1,2,3...),数据域里存储实际的数据,指针域则存储下一个(或上一个)节点的内存地址,是链表节点间 “连接” 的核心,通过这个指针将当前节点与下一个节点关联起来。
事实上,链表的种类有许多,譬如双向链表,循环链表,我们这里就不做讨论了。
显然,只了解链表的定义是完全不够的,重点在于链表的代码实现和实际应用,为了让读者更容易理解,我们将以例题的形式学习创建单链表。
二、链表的创建
为了方便,以后所有代码都使用C++讲解,C语言代码会放在文末附录里,头文件也统一使用#include<bits/stdc++.h>
1.尾差法(顺序建立链表)
例题:
输入N个整数,按照输入的顺序建立单链表存储,并遍历所建立的单链表,输出这些数据。
输入格式:
第一行输入整数的个数N;
第二行依次输入每个整数。
输出格式:
输出这组整数。
输入样例:
8 12 56 4 6 55 15 33 62
输出样例:
创建链表,每个节点都是一个整体,面对大量数据当然离不开结构体,因此我们首要一步是创建结构体:
#include<bits/stdc++.h>
using namespace std;
//定义节点结构:数据域,指针域
struct node{
int data;//数据域
node *next;//指针域(指向下一个节点的指针)
};结构体大家已经熟知了,我们就不做过多赘述,链表结构体由数据域和指针域两部分组成,通俗来讲,就是你要输入的数据,和连接下一节点的指针。
链表的结构工作已经完成,下一步开始进行链表建立工作,
首要的就是创建指针:
node* head=NULL;//头指针,指向链表的第一个节点,初始为空
node* tail=NULL;//尾指针,指向链表的最后一个节点,初始为空
node* newnode;//临时指针,用于创建新节点该工作可以单独定义函数,也可以在main函数内使用,在讲解中,我们统一直接在main函数里使用,对于单独定义函数大家自行设计,这里不再赘述。
创建的指针有三部分,头指针,尾指针和临时指针,头指针和尾指针顾名思义是指向链表的第一个节点的指针,我们一般给他初始化为空,尾指针是指向链表的最后一个节点,一般初始也为空。对于临时指针,创建新节点时,我们需要先给它的 data 和 next 赋值,这个过程需要一个指针来操作这个新节点。如果直接用 head 或 tail 操作,会导致原有链表的头 / 尾指针丢失(因为 head 和 tail 需要保持指向链表的头 / 尾),它每次循环都会指向一个新创建的节点,用完后会被下一个新节点覆盖。
创建完指针之后,就是要创建节点并连接起来:
for(int i=0;i<n;i++){
int num;
cin>>num;
//创建新节点
newnode= new node;//申请新节点的内存空间
newnode->data=num;//将输入的数赋值给新节点的数据域
newnode->next=NULL;//将新节点的指针域设为空
//如果是第一个节点(链表为空)
if(head==NULL){
head=newnode;//头指针指向第一个节点
tail=newnode;//尾指针也指向第一个节点
}
//如果不是第一个节点
else{
tail->next=newnode;//将尾指针的指针域指向新节点
tail=newnode;//更新尾指针,指向新的最后一个节点
}
}就像数组一样,我们需要循环输入数据,创建节点。而每次创建节点就需要申请新的空间,申请完空间后,我们就可以将数据赋值给新节点的数据域,(-> 是成员访问运算符,专门用于通过指针访问对象(或结构体)的成员),并将新节点的指针域设为空。
对于下面的指针域,要判断是否为空链表,如果是空链表,很显然,头指针和尾指针都只能指向第一个节点。不是空链表,尾指针的指针域指向新节点,然后更新尾指针。
链表的创建工作完成了,我们就可以遍历打印了:
//遍历链表输出
node* current=head;//当前指针,用于遍历链表
while (current!=NULL){
cout<<current->data;//输出当前节点的数据
//如果当前节点不是最后一个节点,输出空格
if(current->next!=NULL){
cout<<" ";
}
current=current->next;
}
cout<<endl;遍历链表我们需要借助一个current指针,便于我们遍历链表,初始化为头指针,在循环遍历中,如果不是空指针就输出当前节点的数据,对于空格的输出,大家根据实际情况设计,这里不再解释。
对于链表释放,实际上是很重要的,它的目的是回收链表节点所占用的动态分配内存(通过 new 申请的内存),避免内存泄漏(即程序结束后仍有未释放的内存无法被系统回收)。但有时在OJ上是不作为检测点的。
//释放链表占用的内存
current=head;
while(current !=NULL){
node*temp=current; // 临时保存当前节点
current=current->next;// 移动到下一个节点
delete temp; // 释放当前节点的内存
}
用 current 指针从 head(链表第一个节点)开始,依次访问每个节点,用 temp 指针暂存 current 指向的节点地址(因为下一步要移动 current,如果不保存,会丢失当前节点的地址,导致无法释放)让 current 指向 current->next(下一个节点),确保即使当前节点被释放,仍能继续访问后续节点,通过 delete temp 释放 temp 指向的节点(即原来 current 指向的节点),将内存归还给系统,重复上述步骤,直到 current 指向 NULL(表示所有节点都已释放)。
为什么要手动释放内存?
- 链表的节点是通过
new动态分配的内存,这类内存不会自动释放(不同于局部变量在函数结束时的自动销毁)。 - 如果不释放,程序运行过程中会持续占用这些内存,长期运行可能导致内存耗尽(尤其对频繁创建 / 销毁链表的程序)。
下面我给出完整的代码:
#include<bits/stdc++.h>
using namespace std;
//定义节点结构:数据域,指针域
struct node{
int data;//数据域
node *next;//指针域(指向下一个节点的指针)
};
int main(){
int n;
cin>>n;
//准备创建链表
node* head=NULL;//头指针,指向链表的第一个节点,初始为空
node* tail=NULL;//尾指针,指向链表的最后一个节点,初始为空
node* newnode;//临时指针,用于创建新节点
//循环创建节点并连接成链表
for(int i=0;i<n;i++){
int num;
cin>>num;
//创建新节点
newnode= new node;//申请新节点的内存空间
newnode->data=num;//将输入的数赋值给新节点的数据域
newnode->next=NULL;//将新节点的指针域设为空
//如果是第一个节点(链表为空)
if(head==NULL){
head=newnode;//头指针指向第一个节点
tail=newnode;//尾指针也指向第一个节点
}
//如果不是第一个节点
else{
tail->next=newnode;//将尾指针的指针域指向新节点
tail=newnode;//更新尾指针,指向新的最后一个节点
}
}
//遍历链表输出
node* current=head;//当前指针,用于遍历链表
while (current!=NULL){
cout<<current->data;//输出当前节点的数据
//如果当前节点不是最后一个节点,输出空格
if(current->next!=NULL){
cout<<" ";
}
current=current->next;
}
cout<<endl;
//释放链表占用的内存
current=head;
while(current !=NULL){
node*temp=current; // 临时保存当前节点
current=current->next;// 移动到下一个节点
delete temp; // 释放当前节点的内存
}
return 0;
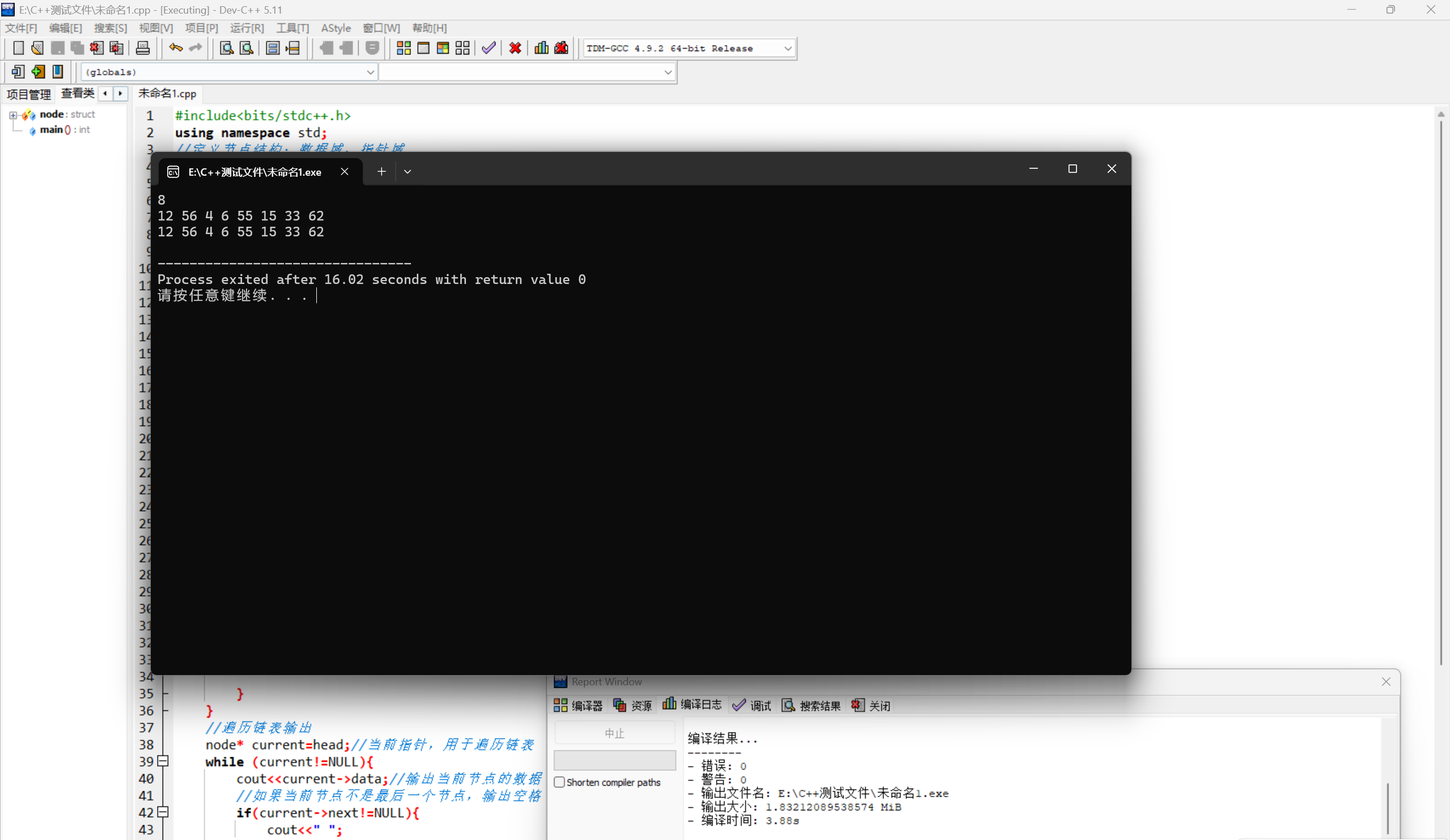
}下面是DEVC++运行结果:
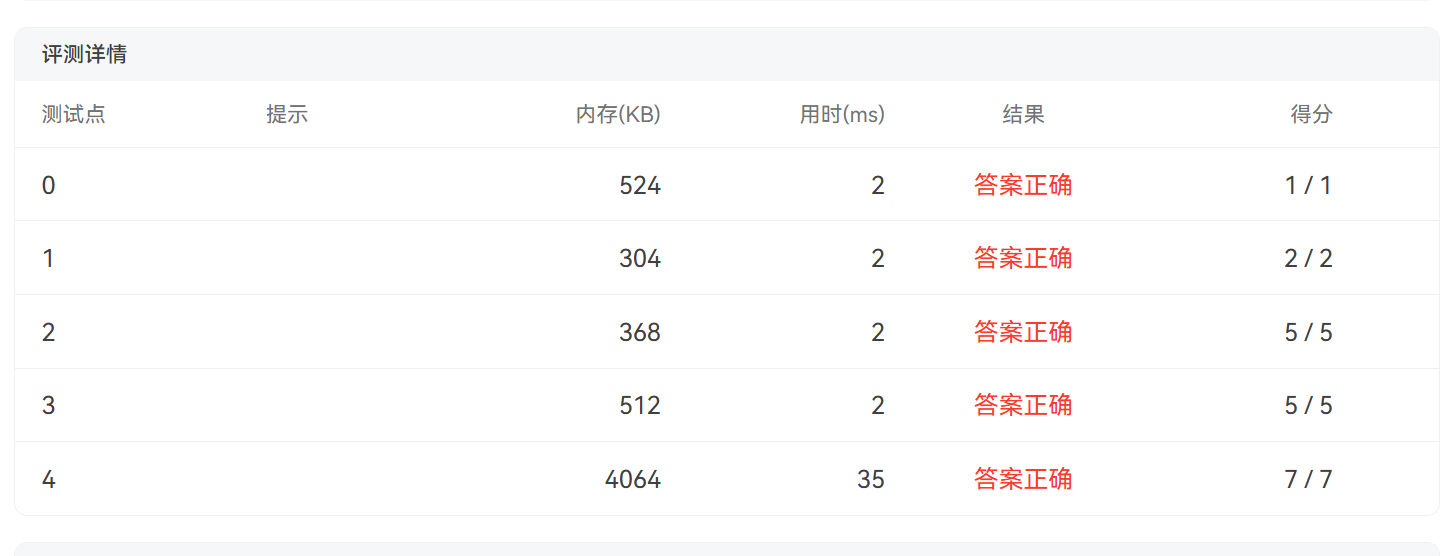
下面是PTA评测结果:
2.头插法(逆序建立链表)
头插法,顾名思义,核心逻辑是每次将新节点插入到链表的头部(而非尾部),最终链表的输出顺序会与输入顺序相反。
但其实代码整体流程仍为「创建链表 → 遍历输出 → 释放内存」,只是链表创建方式与之前写的尾插法有所不同,这代码的关键,对于与尾插法重合部分我们一笔带过,不再做赘述。
例题:输入整数个数N,再输入N个整数,按照这些整数输入的相反顺序建立单链表,并依次遍历输出单链表的数据。
输入格式:
第一行输入整数N;
第二行依次输入N个整数,逆序建立单链表。
输出格式:
依次输出单链表所存放的数据。
输入样例:
8 12 56 4 6 55 15 33 62
输出样例:
62 33 15 55 6 4 56 12 8
前置重合部分:
#include<bits/stdc++.h>
using namespace std;
struct node{
int data;
node *next;
};
int main(){
int n;
cin>>n;
node* head=NULL;
node*newnode;下面是核心部分,创建逆序链表:
for(int i=0;i<n;i++){
int num;
cin>>num;
// 1. 创建新节点(与尾插法一致)
newnode = new node; // 申请新节点内存
newnode->data = num; // 新节点数据域赋值
newnode->next = NULL; // 初始指针域设为NULL(后续会修改)
// 2. 头插法核心:将新节点连接到原链表头部
newnode->next = head; // 新节点的next指向当前头节点(原链表的第一个节点)
head = newnode; // 更新头指针,让新节点成为新的链表头部
}头插法的核心思路是新节点作为链表的第一个节点,通过调整指针让新节点连接到原链表头部,再更新头指针指向新节点。
为了再方便理解,我们用1,2,3举例,在第一次循环中,输入了1,初始 head=NULL,新节点 newnode 数据为 1,链表:head → [1] → NULL。第 二 次循环,输入 2,新节点数据为 2,newnode->next = head → 新节点的 next 指向 1(原头部)。head = newnode → 头指针更新为 2。链表:head → [2] → [1] → NULL,第三次循环,新节点数据为 3,newnode->next = head → 新节点的 next 指向 2(原头部)。head = newnode → 头指针更新为 3。链表:head → [3] → [2] → [1] → NULL。
最后,我们在遍历输出,释放内存,与尾插法一致
node*current=head;
while(current!=NULL){
cout<<current->data;
if(current->next!=NULL){
cout<<" ";
}
current=current->next;
}
cout<<endl;
current=head;
while(current!=NULL){
node*temp=current;
current=current->next;
delete temp;
}
return 0;
}最后,我们给出一份完整代码,但我们不再给出注释,目的是让读者自行理解代码:
#include<bits/stdc++.h>
using namespace std;
struct node{
int data;
node *next;
};
int main(){
int n;
cin>>n;
node* head=NULL;
node*newnode;
for(int i=0;i<n;i++){
int num;
cin>>num;
newnode=new node;
newnode->data=num;
newnode->next=NULL;
newnode->next=head;
head=newnode;
}
node*current=head;
while(current!=NULL){
cout<<current->data;
if(current->next!=NULL){
cout<<" ";
}
current=current->next;
}
cout<<endl;
current=head;
while(current!=NULL){
node*temp=current;
current=current->next;
delete temp;
}
return 0;
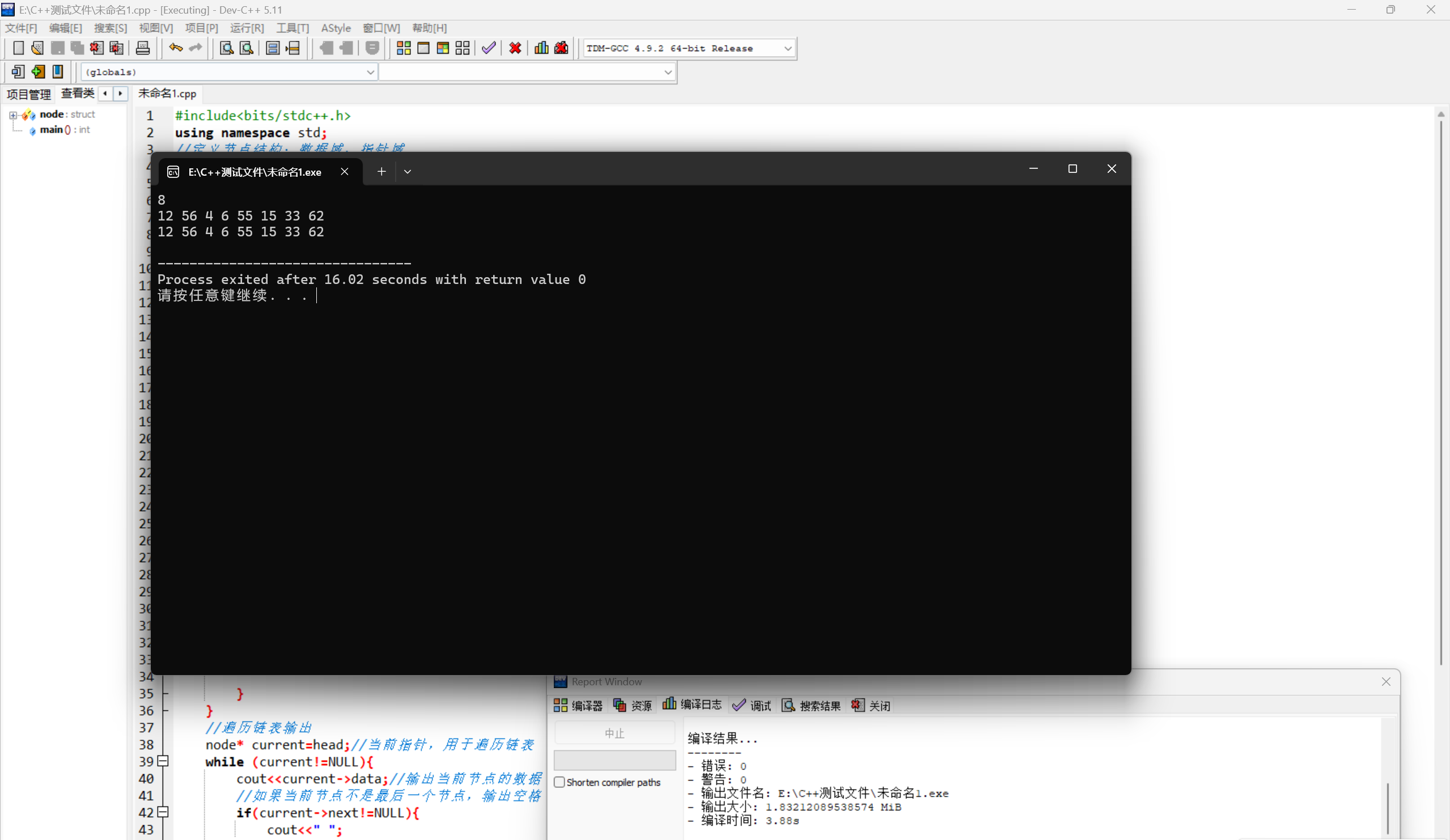
}下面是DEVC++运行结果:
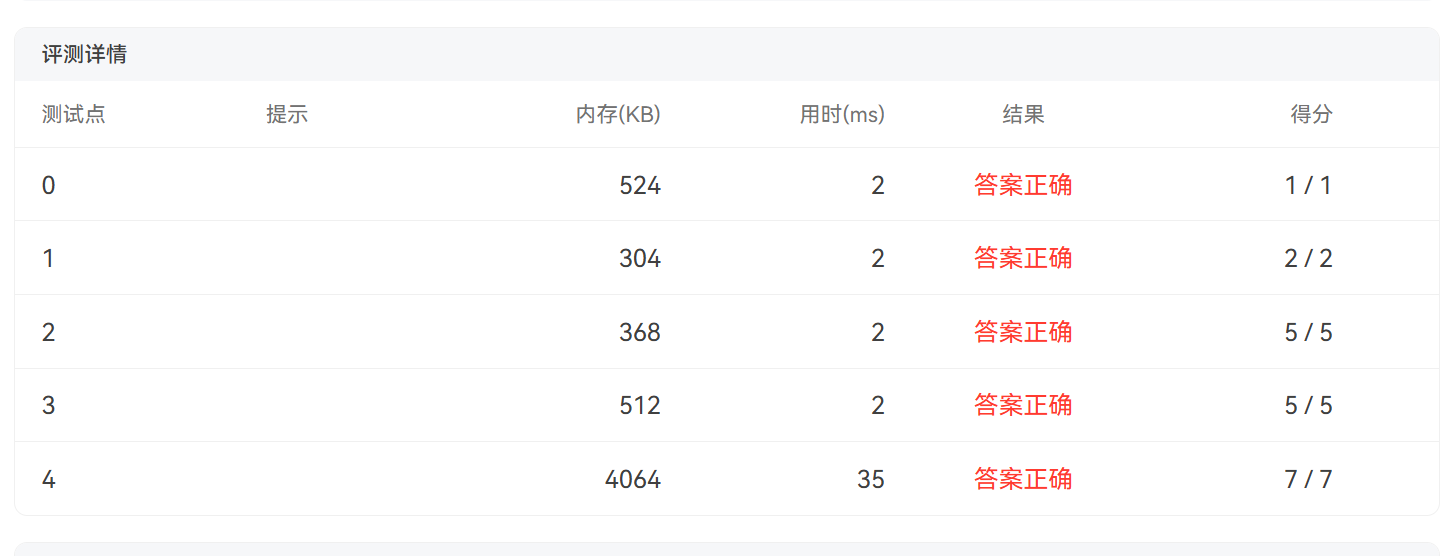
下面是PTA测评结果:
3.数组与链表的区别:
数组和链表的区别很多人是不明白的,事实上它们的本质就是不同的。
从存储方面来讲,对于数组,无论是静态数组(如 int a[648])还是动态数组( C++的 vector、Java 的 ArrayList),元素都会存储在物理地址连续的内存块中,t它是连续的固定的。对于链表,元素分散存储在内存的不同位置,每个节点除了存储数据,还会额外存储指针 / 引用,用于指向相邻节点,从而形成 “链状结构”。
在插入 / 删除元素方面,对于数组,若在数组中间插入元素,需要先将插入位置后的所有元素向后移动 1 位,腾出空间;删除元素则需要将后续元素向前移动 1 位,填补空缺。例如,在长度为 1000 的数组第 10 位插入元素,需移动 991 个元素。但对链表而言,插入 / 删除时,只需修改相邻节点的指针指向,无需移动任何数据。
总而言之,链表与数组差别还是很大的,直观上来看,数组只需要定义好输入数据即可,而链表则需要自己创建。下面我用AI生成了一份对比表格,大家可以参考一下:
| 对比维度 | 数组(Array) | 链表(Linked List) |
|---|---|---|
| 内存存储方式 | 连续内存空间(物理地址连续) | 非连续内存空间(通过指针 / 引用连接节点) |
| 元素访问方式 | 随机访问(通过下标 arr[i] 直接定位,O (1)) | 顺序访问(必须从表头 / 表尾遍历,O (n)) |
| 容量灵活性 | 固定容量(静态数组)或扩容成本高(动态数组) | 动态容量(按需分配 / 释放节点,无扩容问题) |
| 插入 / 删除效率 | 中间 / 头部插入 / 删除:O (n)(需移动后续元素) | 中间 / 头部插入 / 删除:O (1)(仅需修改指针) |
| 内存利用率 | 可能存在内存浪费(动态数组预分配冗余空间) | 内存利用率高(仅存储有效数据 + 指针,无冗余) |
| 实现复杂度 | 实现简单(依赖语言原生支持,如 int[]) | 实现较复杂(需手动管理节点、指针和内存释放) |
| 缓存友好性 | 缓存命中率高(连续内存适配 CPU 缓存机制) | 缓存命中率低(非连续内存易导致缓存失效) |
| 额外空间开销 | 无额外开销(仅存储数据) | 有额外开销(每个节点需存储指针 / 引用) |
三.总结
单链表通过节点间的指针链接实现动态存储,其创建过程包括初始化头节点、动态分配内存以及维护节点间的指向关系。这种结构在插入和删除操作上具有明显优势,但随机访问效率较低。掌握单链表的定义与创建方法,不仅为后续学习其他链式结构(如循环链表、双向链表)奠定基础,还能帮助开发者根据实际需求灵活选择数据结构。通过实践单链表的代码实现,可以深入理解指针操作和动态内存管理的核心原理。在下一篇文章中,我会继续讲解链表的插入与删除,感谢大家的支持。
最后如果你是刚开始学计算机专业的大一新生,或者是准备跨考计算机的学生,又或是想要学习计算机技术的社会人员,倘若在学习计算机中遇到了困难,不妨看一下我的经历:我刚上大学的时候,最初的专业并不是计算机专业,而是数学专业。但在大一下学期的时候,阴差阳错的转到了计算机科学专业,作为一名标准的理科男,我只会研究研究理论知识,解决解决数学问题,对于C语言是一窍不通,但既然转进来了就避免不了期末考试,也只能硬着头皮学,在这个起步阶段是万分痛苦的,什么动态规划,贪心算法根本理解不了,我熬了无数个夜,看了无数个网课,刷了无数道题,在题目中学习总结,可以说每学一部分就会万分的痛苦 ,但最后我也克服了它们,再后来的三年里,我的成绩一直处于专业前三名,也参加过众多比赛,参加了许多项目,也获得了很多不错的成绩和收获,每一次经历都是成长。
其实当你翻过了这座山你就会发现,计算机其实并不难,计算机终究是人造的,是人想出来的,它不像数学,物理,化学这些自然科学,需要你不断的探索和发现,这确实需要天赋。但计算机并不是,它从始至终不过是人类所设计的辅助工具,C++也不过是一种语言,也不过就是一堆字母,它也是人类设计的,他们能想到你也能想到,你早晚有一天也会明白,C语言为什么是这么写的,计算机为什么是这样工作的,计算机网络是怎样设计的,它们也不过如此。希望你们在未来的学习的路上不要畏惧它,而是想办法克服它,解决它,任何问题它能提出来,就一定能解决掉。
附录:
例1 C语言代码:
#include <stdio.h>
#include <stdlib.h>
// 定义节点结构:数据域,指针域
struct node {
int data; // 数据域
struct node *next; // 指针域(指向下一个节点的指针)
};
int main() {
int n;
scanf("%d", &n); // 读取节点数量
// 准备创建链表
struct node *head = NULL; // 头指针,指向链表的第一个节点,初始为空
struct node *tail = NULL; // 尾指针,指向链表的最后一个节点,初始为空
struct node *newnode; // 临时指针,用于创建新节点
// 循环创建节点并连接成链表
for (int i = 0; i < n; i++) {
int num;
scanf("%d", &num); // 读取节点数据
// 创建新节点,C语言中使用malloc分配内存
newnode = (struct node*)malloc(sizeof(struct node));
newnode->data = num; // 将输入的数赋值给新节点的数据域
newnode->next = NULL; // 将新节点的指针域设为空
// 如果是第一个节点(链表为空)
if (head == NULL) {
head = newnode; // 头指针指向第一个节点
tail = newnode; // 尾指针也指向第一个节点
}
// 如果不是第一个节点
else {
tail->next = newnode; // 将尾指针的指针域指向新节点
tail = newnode; // 更新尾指针,指向新的最后一个节点
}
}
// 遍历链表输出
struct node *current = head; // 当前指针,用于遍历链表
while (current != NULL) {
printf("%d", current->data); // 输出当前节点的数据
// 如果当前节点不是最后一个节点,输出空格
if (current->next != NULL) {
printf(" ");
}
current = current->next; // 移动到下一个节点
}
printf("\n");
// 释放链表占用的内存,C语言中使用free释放内存
current = head;
while (current != NULL) {
struct node *temp = current; // 临时保存当前节点
current = current->next; // 移动到下一个节点
free(temp); // 释放当前节点的内存
}
return 0;
}
- 在 C 语言中,使用结构体类型时必须加上
struct关键字(除非使用typedef定义别名) - 指针定义改为
struct node *形式 - 将 C++ 的
new替换为 C 语言的malloc,并需要显式进行类型转换(struct node*), - 将 C++ 的
delete替换为 C 语言的free函数
例2 C语言代码:
#include <stdio.h>
#include <stdlib.h>
struct node {
int data;
struct node *next;
};
int main() {
int n;
scanf("%d", &n);
struct node *head = NULL;
struct node *newnode;
for (int i = 0; i < n; i++) {
int num;
scanf("%d", &num);
newnode = (struct node*)malloc(sizeof(struct node));
newnode->data = num;
newnode->next = NULL;
newnode->next = head;
head = newnode;
}
struct node *current = head;
while (current != NULL) {
printf("%d", current->data);
if (current->next != NULL) {
printf(" ");
}
current = current->next;
}
printf("\n");
current = head;
while (current != NULL) {
struct node *temp = current;
current = current->next;
free(temp);
}
return 0;
}

















 3048
3048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









