






 这篇博客展示了如何使用Python中的`scipy.optimize.curve_fit`进行数据拟合,以及利用`matplotlib`库绘制数据点和拟合曲线。作者通过读取Excel文件中的数据,进行了7次多项式拟合,并生成了趋势图,强调了数据可视化在理解复杂关系中的作用。
这篇博客展示了如何使用Python中的`scipy.optimize.curve_fit`进行数据拟合,以及利用`matplotlib`库绘制数据点和拟合曲线。作者通过读取Excel文件中的数据,进行了7次多项式拟合,并生成了趋势图,强调了数据可视化在理解复杂关系中的作用。
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
import pandas as pd
import numpy as np
df=pd.read_excel('D:/CPO/BEV残值逻辑修改/TP超参数.xlsx')
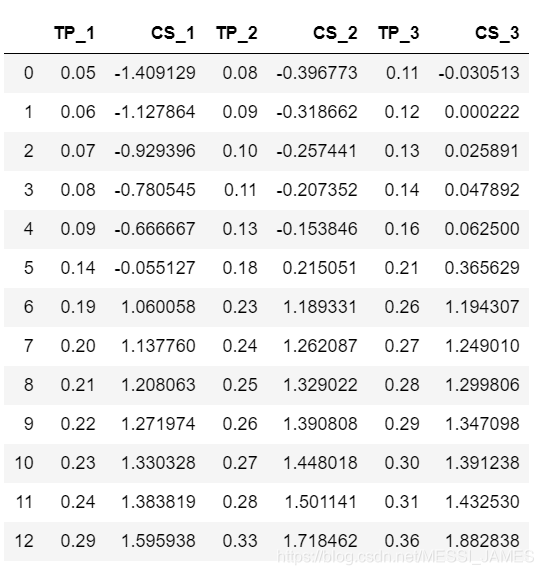
x=df.TP_2.values
y=df.CS_2.values
z1 = np.polyfit(x, y, 7)
p1 = np.poly1d(z1)
list(p1)

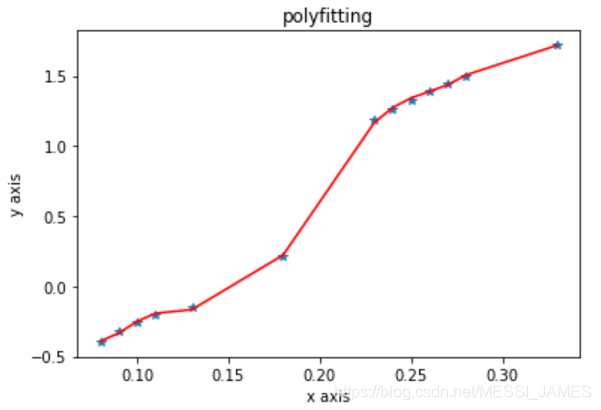
# 画趋势图
yvals=p1(x)#也可以使用yvals=np.polyval(z1,x)
plot1=plt.plot(x, y, '*',label='original values')
plot2=plt.plot(x, yvals, 'r',label='polyfit values')
plt.xlabel('x axis')
plt.ylabel('y axis')
# plt.legend(loc=4)#指定legend的位置,读者可以自己help它的用法
plt.title('polyfitting')
plt.show()

















 4635
4635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









