







 本文深入解析数据库索引的工作原理,包括哈希表的冲突解决策略,有序数组的优缺点,以及MySQL底层的B+树索引模型。重点讲解了主键索引与非主键索引的区别,以及如何选择最适合的数据结构以提升查询效率。
本文深入解析数据库索引的工作原理,包括哈希表的冲突解决策略,有序数组的优缺点,以及MySQL底层的B+树索引模型。重点讲解了主键索引与非主键索引的区别,以及如何选择最适合的数据结构以提升查询效率。
引言
在日常工作中我们经常会接触到数据库索引,比如一个SQL执行起来很慢,经过分析后,你可能会说"添加个索引"之类的解决方案,那到底什么是索引呢?
索引:简单来说就像书的目录一样(面试的时候不要这么说),其实索引更是一种提高数据查询效率的数据结构
常见索引的模型
提高读写的数据结构很多,这里有三种比较简单的数据结构,分别是哈希表,有序数组和搜索树
哈希表
哈希表是一种key - value形式的数据结构,哈希表是基于哈希函数建立的一种表
地址index = H(key)
H是哈希函数,通过这个函数快速的定位value(也就是地址index),如果多个key通过计算获取同样的value怎么办?这就是hash冲突,解决冲突的方式有这些
- 开放寻址法
- 拉链法
假设,你现在维护着一个身份证信息和姓名的表,需要根据身份证号查找对应的名字,这时 对应的哈希索引的示意图如下所示:
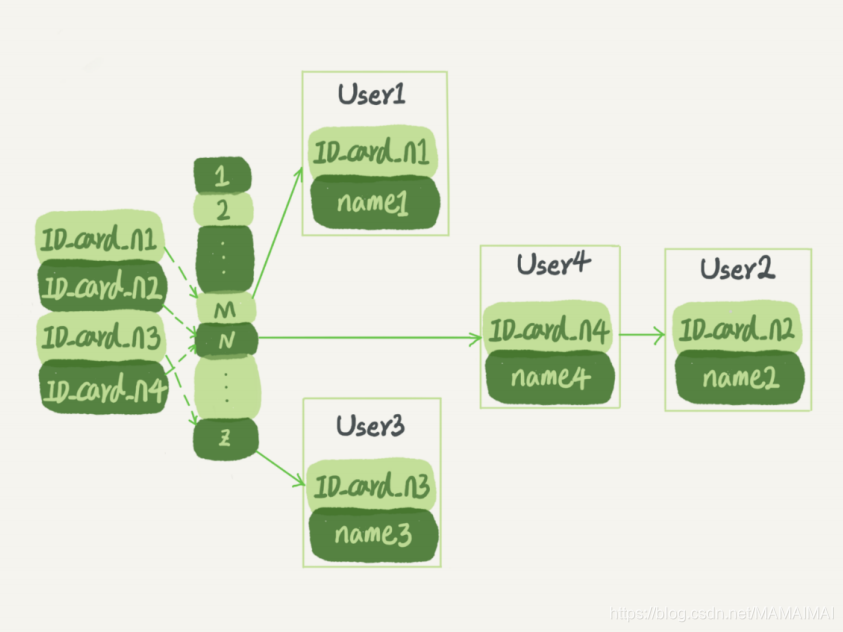
图 1 哈希表示意图 图中,User2 和 User4 根据身份证号算出来的值都是 N,但没关系,后面还跟了一个链 表。假设,这时候你要查 ID_card_n2 对应的名字是什么,处理步骤就是:首先,将 ID_card_n2 通过哈希函数算出 N;然后,按顺序遍历,找到 User2。
需要注意的是,图中四个 ID_card_n 的值并不是递增的,这样做的好处是增加新的 User 时 速度会很快,只需要往后追加。但缺点是,因为不是有序的,所以哈希索引做区间查询的速 度是很慢的。
你可以设想下,如果你现在要找身份证号在 [ID_card_X, ID_card_Y] 这个区间的所有用 户,就必须全部扫描一遍了。
所以,哈希表这种结构适用于只有等值查询的场景,比如 Memcached 及其他一些 NoSQL 引擎。
- 其他方式
今天说索引,其他的索引模型和hash冲突可自行百度
有序数组
单看查询效率的话有序数组是最好的数据结构,但是对于增删操作都要移动后面的数据,成本太高,所以有序数组更适合静态存储引擎
二叉树

二叉搜索树的特点是:每个节点的左儿子小于父节点,父节点又小于右儿子,而插入的搜索效率非常高,但是由于索引不但存在内存,还要存在磁盘中,以innerDB举例,树高4,N叉树的N是1200,那么数据就是17亿
你可以想象一下一棵 100 万节点的平衡二叉树,树高 20。一次查询可能需要访问 20 个数 据块。在机械硬盘时代,从磁盘随机读一个数据块需要 10 ms 左右的寻址时间。也就是 说,对于一个 100 万行的表,如果使用二叉树来存储,单独访问一个行可能需要 20 个 10 ms 的时间,这个查询可真够慢的。 为了让一个查询尽量少地读磁盘,就必须让查询过程访
mysql底层的索引模型
mysql5.7之后默认的存储引擎是innerDB,innerDB使用的b+树的索引模型,数据只存在叶子节点上

b+tree模型在btree的基础上进行的改进,降低树的高度,增大节点存储数据量,b+tree只需要遍历他的所有叶子节点即可
mysql的索引类型分为主键索引和非主键索引,在innerDB中主键索引成为聚簇索引,非主键索引又叫做二级索引,那么二者有什么区别呢?
- 如果语句是 select * from table where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+ 树;
- 如果语句是 select * from table where k=5,即普通索引查询方式,则需要先搜索 k 索引 树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表;
- 也就是说,基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使 用主键查询;

















 782
782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









