




本专栏持续更新,整一个专栏为一个大型复杂网络工程项目。阅读本文章之前务必先看《本专栏必读》。
一.项目整体背景
1.行业背景与特点
- 项目所在的行业,该行业的常规关注点和常规解决方案。
2.项目背景与目的
- 项目发起的原因以及要达到的效果。
3.业务特点流程
- 网络上承载的业务具有的特点与相关业务的流程。
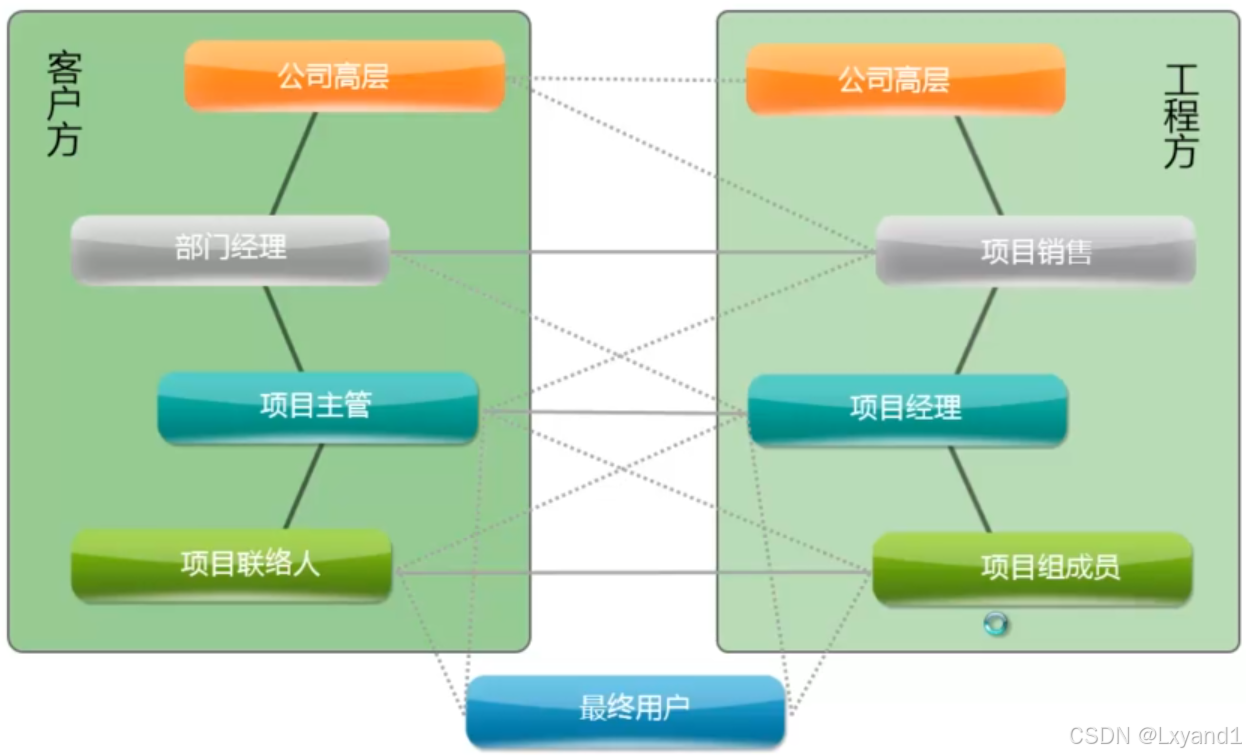
二.客户组织的情况
- 用一张图解释
三.项目范围确定
1.工程边界
- 与配套工程的分工界面和职责范围
2.覆盖范围
- 涉及到的地理范围
3.功能边界
- 项目要实现的具体功能和模块
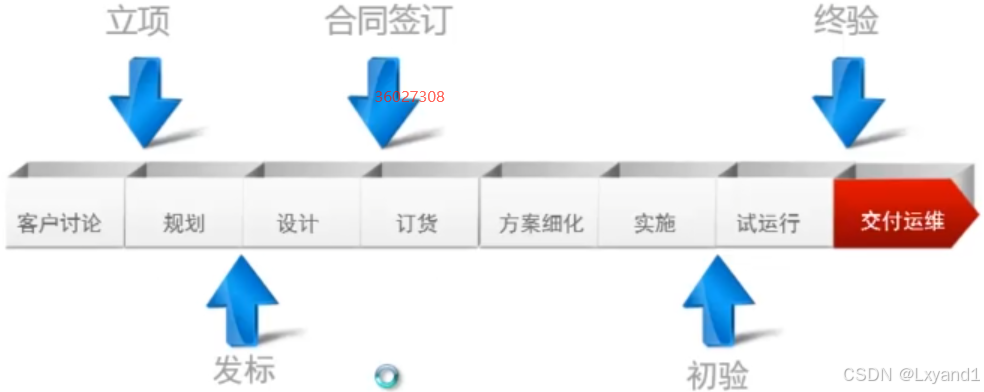
四.项目阶段与项目周期
- WBS:工作分解结构(Work Breakdown Structure)
- 把整个项目分解成较小的,更易于管理的组成部分。
五.项目配套工程

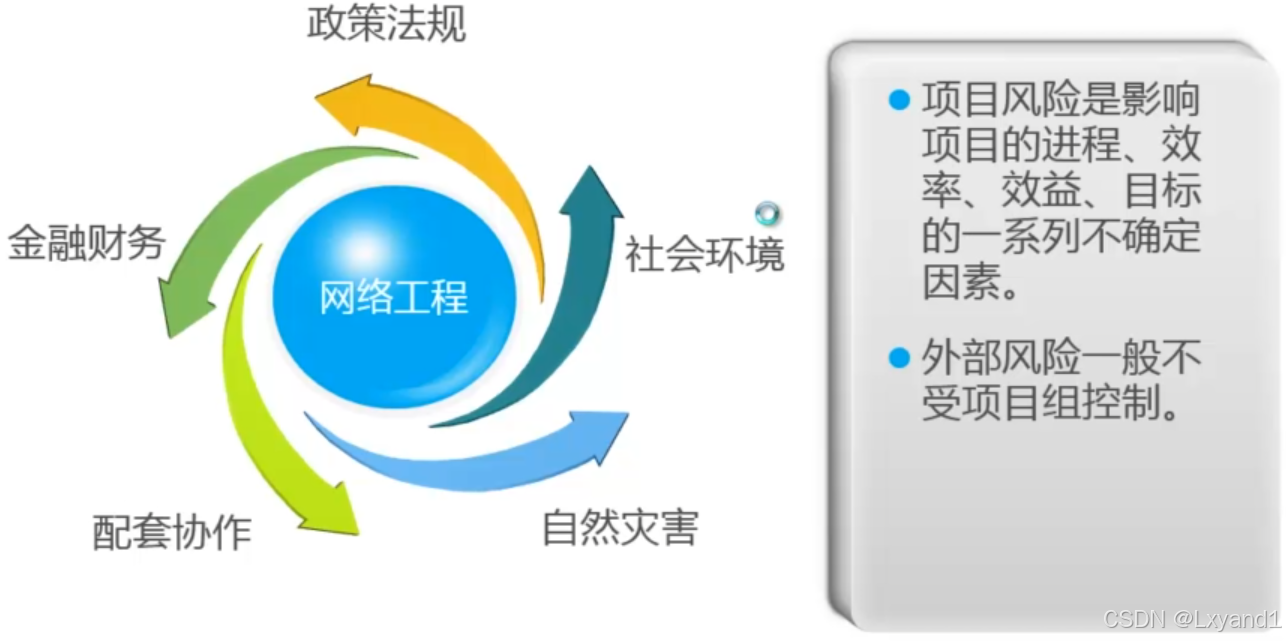
六.外部风险控制

















 580
580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









