




立个flag,这是未来一段时间打算做的Python教程,敬请关注。
1 数据及应用领域
我的程序中给出数据data.xlsx(代码及数据见文末),10 列特征值,1 个目标值,适用于各行各业回归预测算法的需求,其中出图及数据自动保存在当前目录,设置的训练集与预测集的比例为 80%:20%。


(1)地球科学与环境科学
-
遥感反演:利用多源遥感数据预测水体深度、土壤湿度、植被指数、叶面积指数等。
-
气象与气候研究:预测降水量、气温、风速、风向等连续气象变量。
-
水文与水资源管理:河流流量、地下水位、径流量预测。
-
环境污染监测:空气质量指数、PM2.5/PM10浓度、重金属污染水平预测。
-
地质与矿业:预测矿区地表沉降、地裂缝发展趋势,或矿产储量评估。
(2)生物学与医学
-
生态学:预测物种分布密度、群落生物量或生态环境因子变化。
-
公共卫生:基于环境、生活方式或基因组数据预测疾病风险或血液生化指标。
-
医学影像分析:预测器官或病灶体积、组织属性、功能指标。
(3)工程与物理科学
-
材料科学:预测材料性能,如强度、硬度、导热性、弹性模量
-
土木与结构工程:预测建筑物或桥梁的应力、位移、寿命周期。
-
控制系统与信号处理:连续控制变量预测、信号功率或系统状态预测。
(4)经济与社会科学
-
经济预测:股价、GDP、通货膨胀率、消费指数预测。
-
市场分析:销售额、客户需求、产品价格预测。
-
社会行为:人口增长、流动性、社会指标预测。
(5)数据科学与机器学习方向
-
时间序列预测:股票价格、气象指标、传感器数据。
-
多变量因果建模:分析各特征对连续目标变量的影响。
-
特征重要性解释:结合SHAP、LIME等方法揭示变量贡献。
2 算法理论基础
🌟 一、XGBoost 是什么?
一句话概括:
“XGBoost 是一种把“决策树 + Boosting”做到极致的算法。
它的核心思想很简单: 每一棵树都在帮前一棵树“补作业”。最终用一堆小树叠加成一个强大的预测模型。
🔍 二、Boosting 的思想:不断纠错的“班级接力赛”
想象一下,一个班级做题:
-
第1位同学先做一遍,做得不太好
-
第2位同学专门看他错的地方继续改
-
第3位同学继续弥补前两位的不足
-
……
XGBoost 就是这样: 每一轮都在修前一轮的“错题”。最终把误差压到很低。
🧠 三、XGBoost 为什么比普通的 GBDT 更强?
XGBoost 的“外挂”非常多,但最关键有三点:
✔ ① 更聪明:它能“看一阶”和“看二阶”
普通 GBDT 只看数据的“变化方向”。XGBoost 还会看“变化的速度和曲率”。通俗理解:
-
别的算法只知道“往左走还是往右走”
-
XGBoost 还能知道“这个方向好不好、稳不稳、是不是悬崖边”
所以它分裂节点时更稳,不容易被噪声带偏。
✔ ② 更能抗过拟合:它天生带“刹车系统”
XGBoost 内置了很多“限制树太复杂”的机制,比如:
-
限制树的叶子数
-
限制叶子的输出强度
-
限制树长多深
-
降低每棵树的“发力强度”(学习率)
-
随机抽行抽列,让模型不被少数样本或特征带偏
这些都让它比普通 GBDT 更稳健。
✔ ③ 更快:它被工程师疯狂优化过
XGBoost 的速度,真的不是开玩笑的快。它做了几件非常狠的事情:
1. 特征提前排序:后面所有树直接复用,速度飞起
2. 自动处理缺失值:模型自己决定缺失值应该往“左子树”还是“右子树”
3. 并行计算:一棵树虽然是串行长的,但分裂候选可以并行
4. 极致利用 CPU 缓存:甚至优化了到底怎么放数据才能让缓存命中率更高
🎯 四、为什么 XGBoost 很难被完全替代?
尽管 LightGBM、CatBoost 等算法不断涌现,但 XGBoost 仍然在大量工程场景里占据一席之地。原因很现实:
-
鲁棒性极强,几乎不会翻车
-
对特征工程依赖小
-
可解释性比深度学习强
-
对稀疏、缺失、不均衡数据极友好
-
参数虽然多,但调参空间巨大,上限高
这是为什么大厂、科研、比赛都离不开它。
3 SHAP理论基础
🌟 一、SHAP 是什么?一句话概括
“SHAP 是一套用“合作博弈论”思维解释模型的方法,用来回答:每个特征到底对预测结果贡献了多少?
如果你想知道:
-
哪些特征最重要?
-
每个特征是“推高”还是“压低”预测?
-
不同样本吸收特征影响的方向是否一致?
-
模型是怎么得出这个数的?
那 SHAP 就是最好的答案。
🧠 二、为什么要 SHAP?传统特征重要性有什么问题?
很多人都用过 XGBoost、Random Forest 的 “特征重要性”,但这些方法有明显缺陷:
❌ 1. 只能告诉你“重要”,不能告诉你“怎么重要”
例如: 某参数重要,但它是推高风速,还是降低风速?不知道。
❌ 2. 不能解释“单一样本”
模型给某一个点预测为 3.2 m/s,到底是由 NDVI 推上去的?还是由降水拉下来的?也不知道。
❌ 3. 依赖模型结构,不通用
不同模型指标不同,难对齐。
SHAP 完美解决了这些痛点。
🎲 三、SHAP 的核心思想:特征是“一起干活的队友”
想象一个团队比赛:
-
每个队员(特征)都可能对团队成绩有贡献
-
但是不同的队伍组合,贡献可能不一样
-
那一个队员的“真实贡献”该怎么算?
SHAP 的思想就是:
“让特征像“队员”一样参加所有组合队伍,再统计每个特征平均能让模型表现提高多少。
这就得到每个特征的贡献值(Shapley value)。它是一个“公平分配功劳”的方案。
🧩 四、SHAP 优秀的地方在哪里?
✔ 1. 公平性强
SHAP 的分配方式满足一系列“公平原则”:
-
谁都没贡献 → 得分为 0
-
特征越能独立提升模型效果 → 得分越大
-
同样作用的特征贡献相同
这是其他方法做不到的。
✔ 2. 能画非常直观的可视化
本程序SHAP带的图包括:
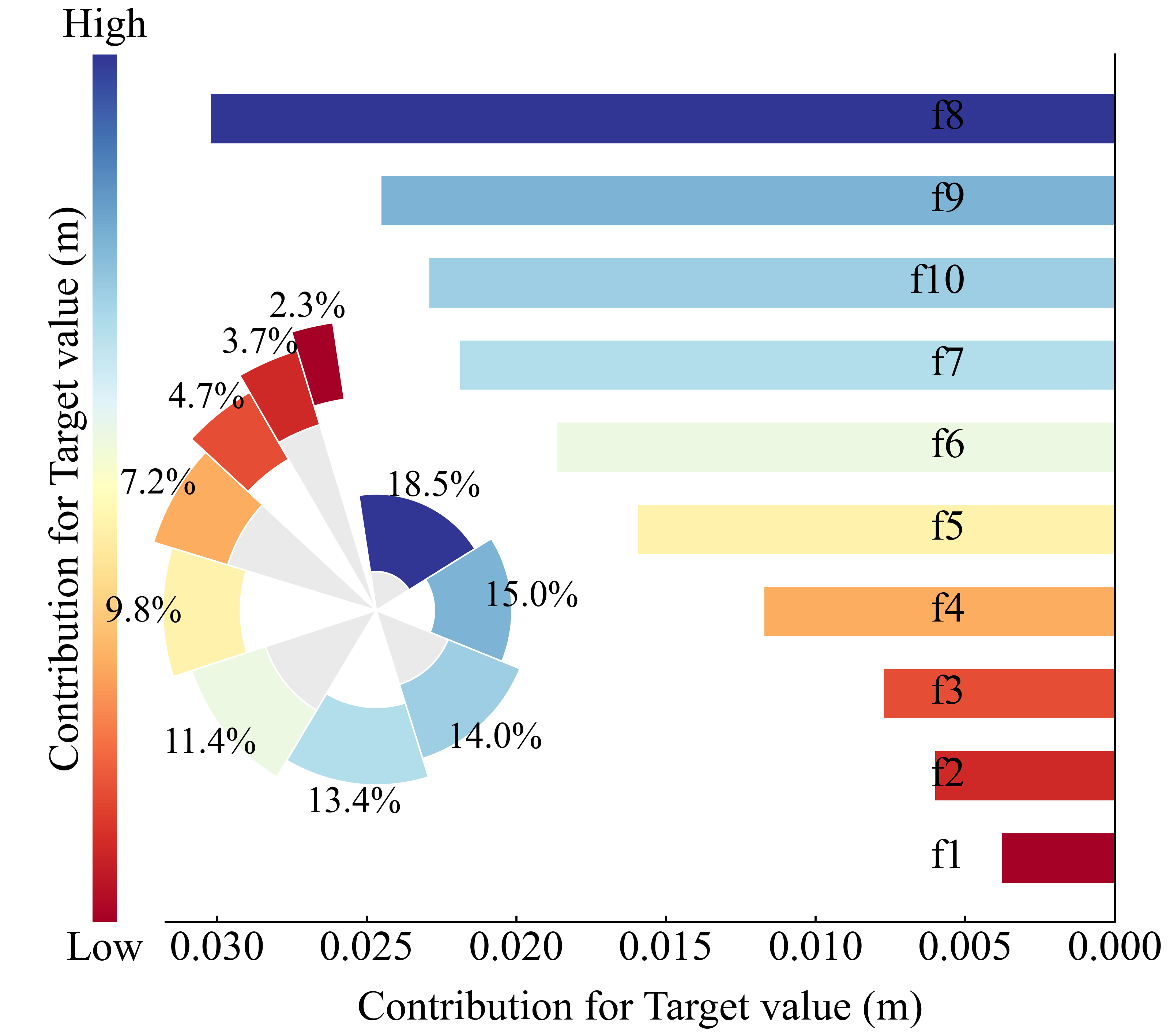
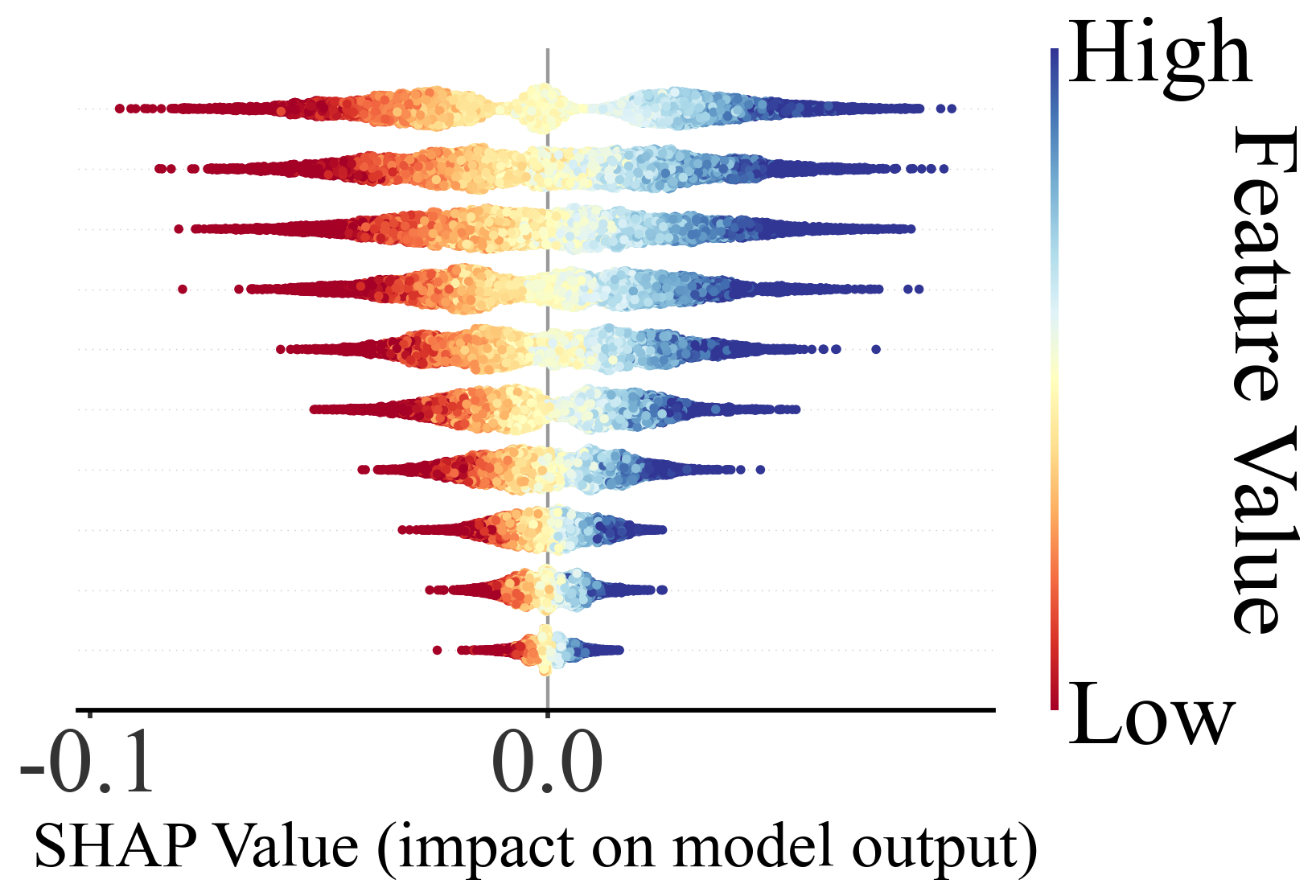
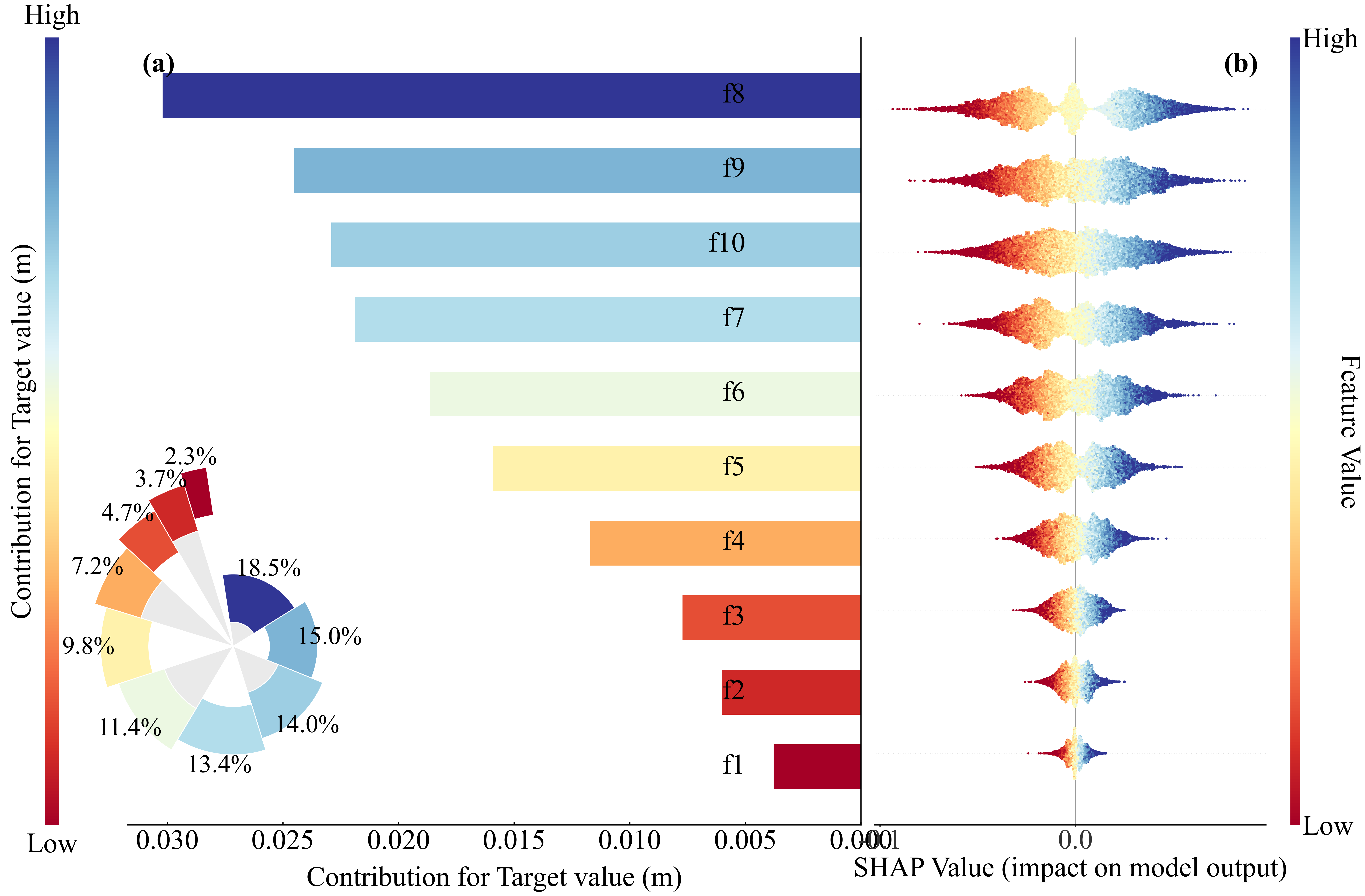
这些图都是发论文神器。
论文价值:可解释性直接提升一档
SCI 论文里 reviewer 最爱问:
-
“模型的物理解释是什么?”
-
“为什么这个特征如此重要?”
-
“模型是不是只是黑盒?”
你用 SHAP,一张 beeswarm plot 就能回答所有问题。
✔ 3. 模型无关、模型无偏见
无论你是:
-
XGBoost
-
CatBoost
-
LightGBM
-
Random Forest
-
Gradient Boosting
-
NGBoost
-
决策树
SHAP 都能解释。
4 其他图示
🎲 一、特征值相关性热图
特征值相关性热图用于展示各特征之间的相关强弱,通过颜色深浅体现正负相关关系,帮助快速识别冗余特征、强相关特征及可能影响模型稳定性的变量,为后续特征选择和建模提供参考。
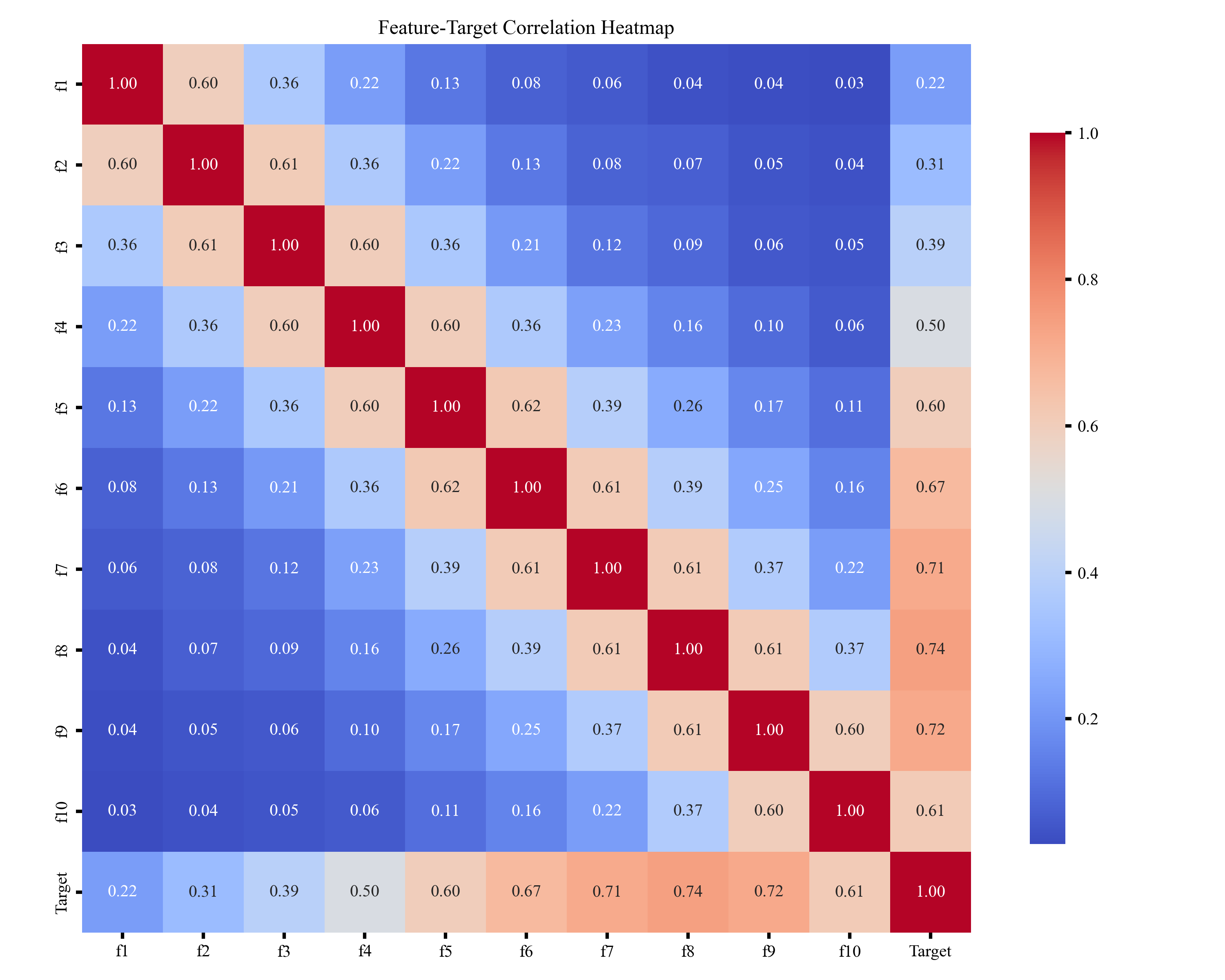
🎲 二、散点密度图
散点密度图通过颜色或亮度反映点的聚集程度,用于展示大量样本的分布特征。相比普通散点图,它能更直观地呈现高密度区域、异常点及整体趋势,常用于回归分析与模型评估。以下为训练集和测试集出图效果。
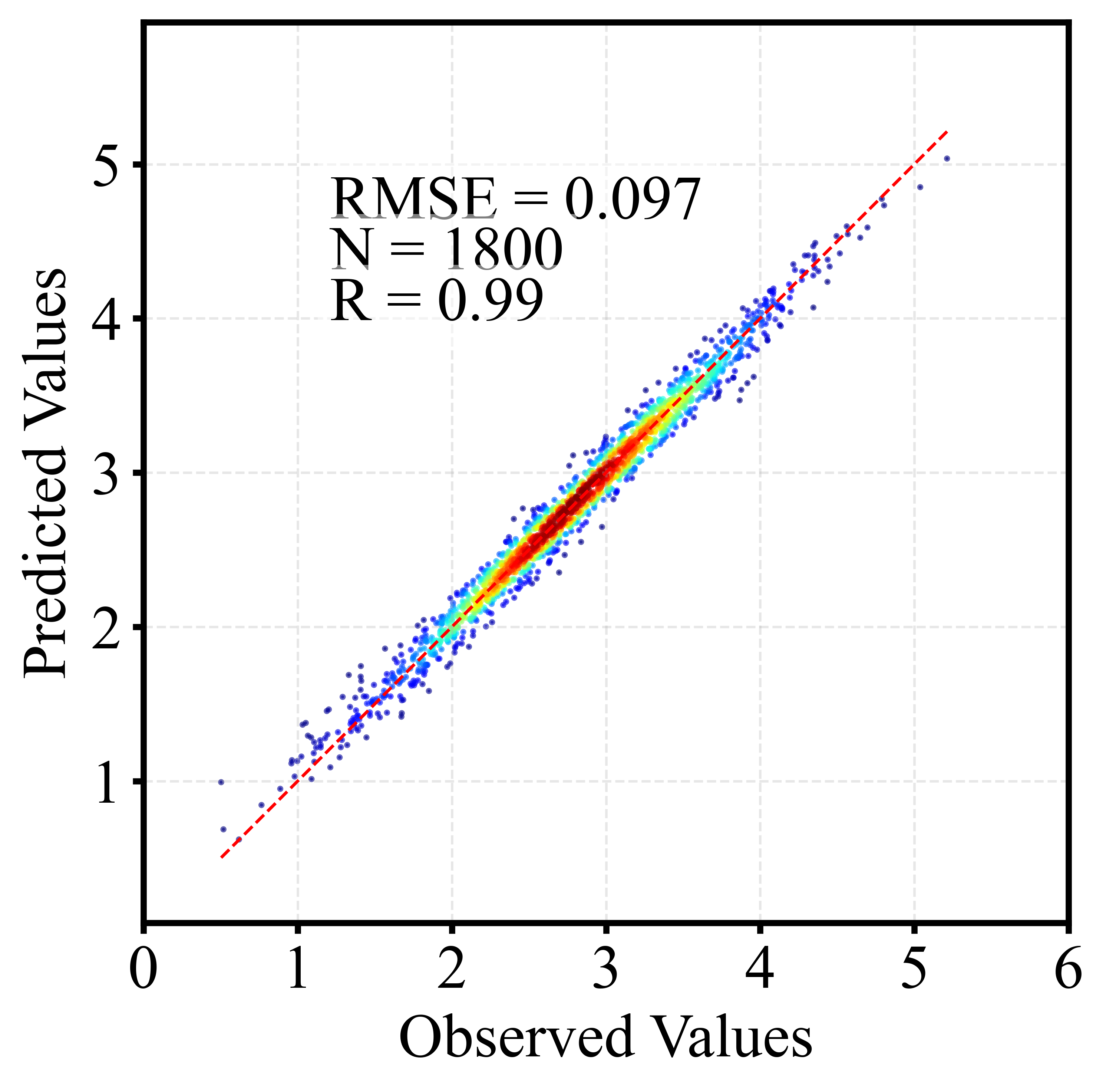
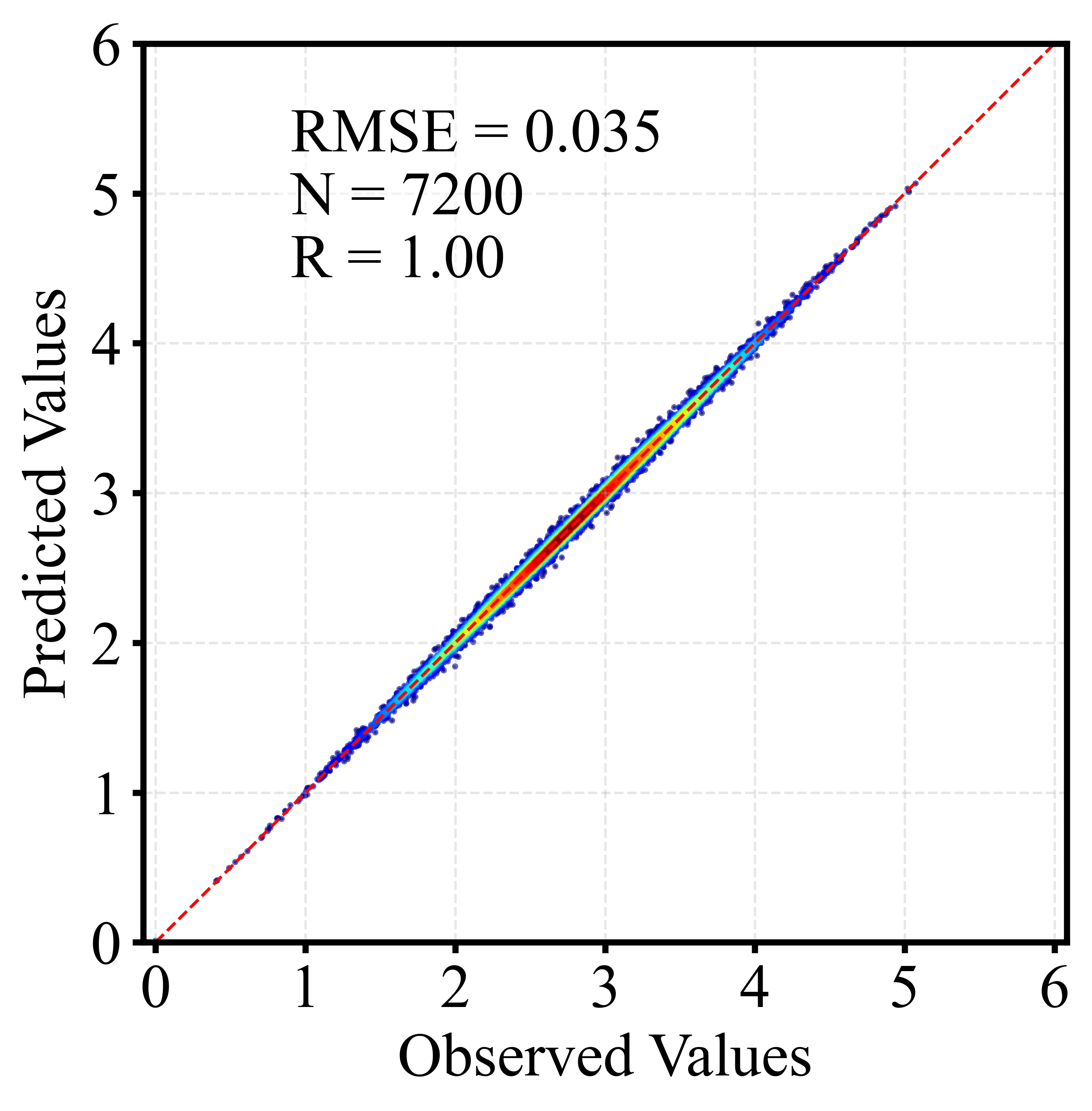
5 代码获取
Python | XGBoost+SHAP 可解释性分析回归预测及可视化算法
新手小白/python 初学者请先根据如下链接教程配置环境,只需要根据我的教程即可,不需要安装 Python 及 pycharm 等软件。如有其他问题可加微信沟通。
Anaconda 安装教程(保姆级超详解)【附安装包+环境玩转指南】
https://mp.weixin.qq.com/s/uRI31yf-NjZTPY5rTXz4eA



















 591
591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











