



 PADA是一种解决域泛化问题的算法,通过生成包含域相关特征(DRFs)的prompt,使模型能在未见过的目标域上进行有效预测。它使用T5语言模型,当处理新样本时,生成与样本相关的prompt,将样本映射到共享语义空间进行下游任务处理。例如,在情感分类中,PADA能将新领域的评论转换为已知源域的语境进行分析。
PADA是一种解决域泛化问题的算法,通过生成包含域相关特征(DRFs)的prompt,使模型能在未见过的目标域上进行有效预测。它使用T5语言模型,当处理新样本时,生成与样本相关的prompt,将样本映射到共享语义空间进行下游任务处理。例如,在情感分类中,PADA能将新领域的评论转换为已知源域的语境进行分析。
Abstract
本文主要是为了解决域泛化DG问题,即在几个源域上进行训练,然后使其可以应用到未见过得目标域(未知域 Unseen Domain)。
因此作者提出了PADA,一种基于示例的自回归prompt learning算法,用于基于 T5 语言模型的即时任意域自适应(An example-based autoregressive Prompt learning algorithm for on-the-fly Any-Domain Adaptation, based on the T5 language model)。
给定一个测试样本,PADA 首先生成一个唯一的prompt,然后基于这个prompt,使用 NLP 预测任务对前述样本进行打标。
PADA 的训标:生成由不限长度的token序列组成的prompt。这个prompt中包含域相关特征DRFs (Domain Related Features) 。直观上来看,生成的prompt是给定样本的唯一签名,并将其映射到了由 source domains组成的语义空间。
代码: https://github.com/eyalbd2/PADA
Introduction
直观地说,DG通过整合来自多个源域的知识,可以更好地泛化到不可见域(未知域)。
PADA提出一种新的学习机制:学习生成代表多个源域的可读prompt。
即:给定一个来自未知域的新样本时,该模型会生成属于熟悉(源)域并且与给定样本相关的属性(一系列tokens),这些属性就当作该样本的prompt从而用于下游任务。
整个工作分成两个阶段:
生成给定样本的prompt word;
根据prompt word 来完成下游任务。
为了生成有效的prompt,作者定义了一个域相关特征集合DRFs (sets of Domain Related Features) 。DRF是与源域密切相关的prompt,对特定域的语义进行编码。
作者利用各种源域的DRF来贯穿(span)多个源域们的共享语义空间,这些 DRF 共同反映了源域之间的相似点和不同点,以及特定领域的知识。
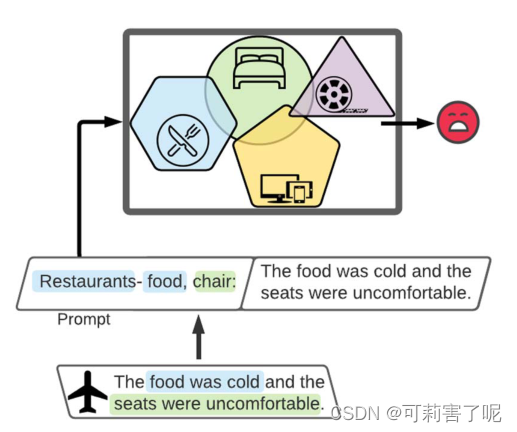
举个栗子:
使用PADA 进行文本情感分类:该模型熟悉四个源域:restaurants, home-furniture,electronic-devices and movies。当评论来自于airlines领域时,它使用 DRF 通过prompt机制将样本(该评论)投射到共享语义空间中,然后在分类中使用基于 DRF 的prompt。
总的来说,PADA 首先生成域名(蓝色餐厅 绿色家居),之后生成一组与输入示例相关的 DRF。然后它使用prompt来预测任务标签。


















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









