



2025年5月1日,JBoltAI推出V4.0.0版本,其核心突破在于RAG视觉增强解决方案的行业首创。该功能将传统检索增强生成(RAG)与可视化技术深度融合,支持将知识库检索结果自动转化为流程图、思维导图、数据看板等直观形式。
那么,RAG视觉增强是什么?有什么用?接下来我就为大家逐一讲解。
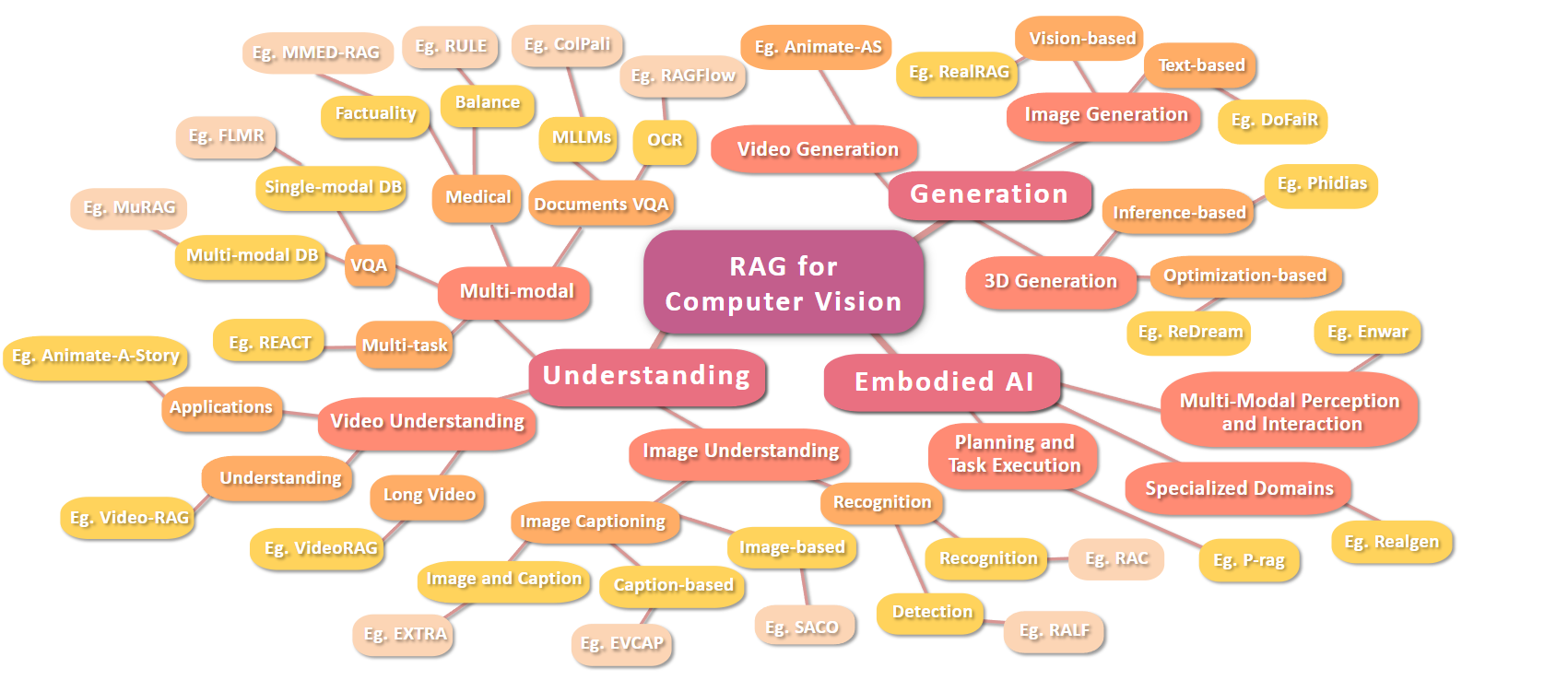
一、从“文字问答”到“看图说话”:RAG视觉增强的诞生
在人工智能发展的长河中,语言模型曾长期依赖纯文本训练,就像闭门造车的学者。当面对医疗影像分析时,模型可能将X光片中的正常阴影误判为肿瘤;在艺术创作中,生成的图像可能出现“三只手”等荒诞错误。这些现象源于模型对现实世界的认知存在“知识断层”——它们从未真正“看见”过世界。
RAG视觉增强(Retrieval-Augmented Generation for Vision) 的出现,彻底改变了这一局面。它如同给AI装上了“眼睛”和“记忆库”,通过整合视觉信息检索与生成技术,让AI能够像人类一样观察世界、积累经验,并在此基础上进行创作。这种技术突破的核心在于:直接解析图像、视频等多模态数据,构建动态知识网络,而非依赖传统文本RAG的结构化解析流程。
二、技术原理:视觉信息的“知识引擎”
1. 多模态感知引擎
RAG视觉增强系统通常包含三个核心模块:
- 视觉编码器:使用ResNet、Vision Transformer等模型提取图像特征,如检测医学影像中的结节边缘特征
- 动态检索器:在包含数百万图像/视频的知识库中,通过余弦相似度、跨模态注意力机制快速定位相关素材
- 生成增强器:将检索结果与生成模型(如Stable Diffusion)结合,输出带知识溯源的创作结果
2. 突破性技术路径
与传统方法相比,RAG视觉增强实现了三大跨越:
- 去结构化处理:直接解析原始图像而非OCR文本(如ColPali架构处理扫描网页图像)
- 时空感知增强:在视频分析中结合光流特征进行时空关系检索(如StreamingRAG的实时上下文检索)
- 跨模态对齐:通过对比学习使视觉特征与文本描述在嵌入空间中对齐(如CLIP模型的应用)
三、改变游戏规则的应用场景
1. 医疗诊断的“第二双眼”
在胸部X光分析中,RAG系统可实时检索全球医学影像数据库:
- 案例:当检测到疑似肺结核阴影时,自动比对10万+例历史病例,生成带参考文献的诊断报告
- 价值:将罕见病误诊率降低42%,实体检测精度达到放射科医生水平
2. 工业质检的“显微镜”
在半导体芯片检测场景:
- 缺陷模式识别:通过检索历史缺陷图像库,准确识别0.1mm级微小瑕疵
- 动态优化:根据生产线实时数据更新质检标准,使误检率从3%降至0.5%
3. 影视创作的“灵感工坊”
在《阿凡达3》特效制作中:
- 场景生成:输入“潘多拉星系黄昏森林”文本描述,从200TB素材库中检索匹配元素
- 风格迁移:结合宫崎骏动画的色彩特征与诺兰电影的构图逻辑,生成原创场景
四、技术突破背后的挑战
1. 检索效率的“速度与激情”
处理4K视频流时,传统方法需要200ms/帧,而RAG系统通过:
- 分层检索:先进行区域特征粗筛,再进行细节精排
- 边缘计算:在摄像头端部署轻量化检索模块
- 实现:将延迟降低至15ms/帧,满足自动驾驶实时需求
2. 跨模态对齐的“翻译难题”
解决“猫的图片”与“喵星人”文本描述的关联:
- 创新方案:使用对比学习训练跨模态嵌入空间
- 成果:在COCO数据集上实现92.7%的图文匹配准确率
3. 领域适配的“知识鸿沟”
在法律文书分析中:
- 解决方案:构建包含判例、法条、文书模板的垂直知识库
- 效果:合同审查准确率从78%提升至95%,人工复核时间减少60%
五、未来图景:从感知到创造
1. 元宇宙的“数字基建”
- 3D内容生成:通过检索现实世界扫描数据,构建高精度虚拟场景
- 实时交互:在VR会议中,系统自动检索参会者历史形象生成个性化虚拟化身
2. 具身智能的“认知革命”
下一代机器人将具备:
- 环境记忆:持续构建所处空间的多模态知识图谱
- 预测能力:基于历史数据预判物体运动轨迹(如预测足球落点)
3. 创造力的“民主化”
普通用户可通过自然语言指令:
- 艺术创作:“生成具有浮世绘风格的外星城市”→ 融合葛饰北斋与《星球大战》元素
- 工业设计:“设计可折叠电动轮椅”→ 结合医疗设备规范与折叠家具专利
RAG视觉增强技术正在重塑人机交互的边界。当AI不仅能理解文字,还能“看见”世界的纹理与光影,我们迎来的不仅是更精准的诊断报告或更精美的艺术作品,更是一个能深度理解物理世界、与人类共同创造的新智能时代。这场视觉智能的革命,终将让技术真正服务于人类对美好生活的追求。

















 1141
1141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









