



 思通数科的舆情系统凭借其自动化抓取、低代码化平台、全站扫描、策略匹配等技术,提供高效、灵活且可靠的数据采集服务,同时开源项目open-spider展示了其技术实力和社区贡献。
思通数科的舆情系统凭借其自动化抓取、低代码化平台、全站扫描、策略匹配等技术,提供高效、灵活且可靠的数据采集服务,同时开源项目open-spider展示了其技术实力和社区贡献。
思通数科的爬虫抓取和信息采集技术是其舆情系统的核心组成部分,展现了以下几个关键能力:
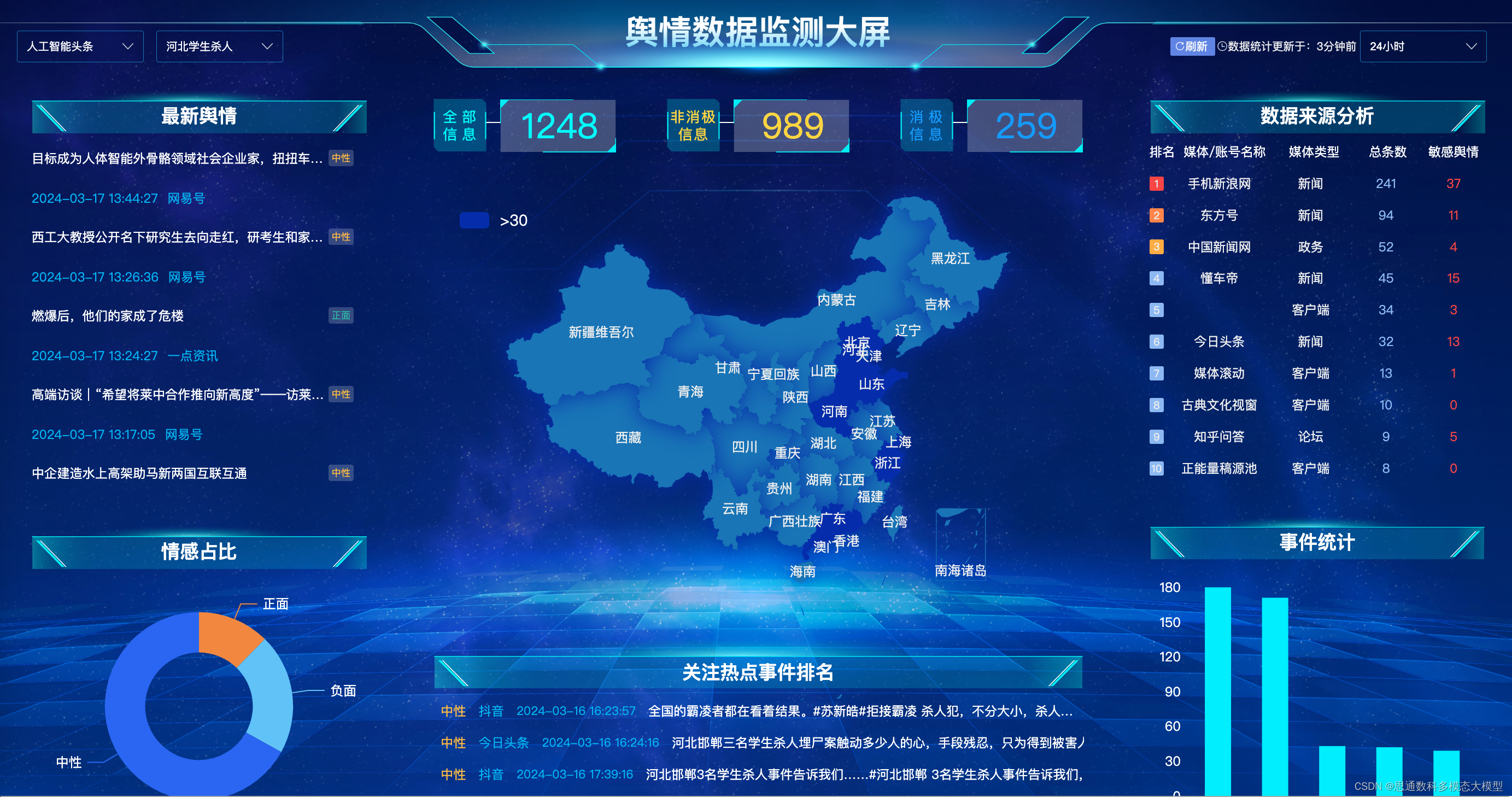
1. 自动化与智能化:思通数科的数据采集模块实现了自动化的数据抓取,利用模拟浏览器请求技术,可以对网站进行深度和广度的抓取,减少了人工干预,提高了数据采集的效率和准确性。
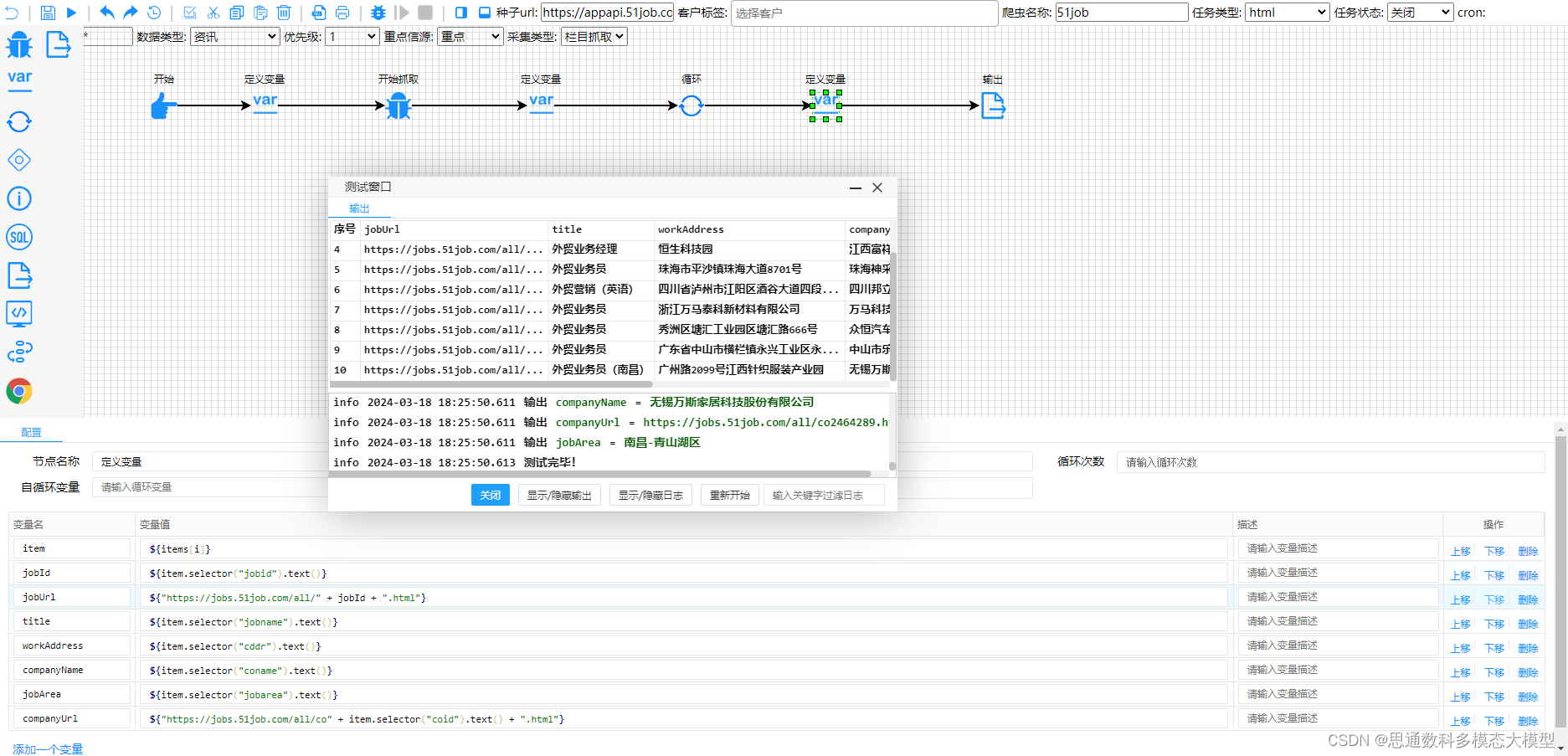
2. 低代码化开发平台:其“爬虫工厂”平台允许用户通过低代码化开发进行爬虫配置,这意味着用户可以不需要深入的编程知识就能定制和部署数据采集任务,极大地降低了技术门槛。
3. 全站扫描与数据储存:思通数科的技术能够对整个站点进行全站扫描,进行数据储存和特性分析,这有助于构建全面的站点画像,为后续的数据采集和分析提供坚实的基础。
4. 策略匹配与自动抓取:平台能够自动识别网站的结构和特性,匹配合适的采集策略,实现数据的自动抓取,这减少了对特定网站定制化开发的需求。

5. 人工配置与可视化技术:对于复杂或难以自动抓取的网站,思通数科提供了可视化配置工具,使得开发人员可以快速对网站的抓取进行配置,提高了灵活性和适应性。
6. 数据暂存与预警机制:采集的数据会先暂存,并有程序进行核对监测,以确保数据的准确性。如果发现错误,系统会及时通知研发工程师进行修正,这增加了系统的可靠性。
7. 开源贡献:思通数科积极开源其爬虫技术,如open-spider项目,这不仅表明了其技术的成熟度,也促进了技术的共享和社区的共同进步。
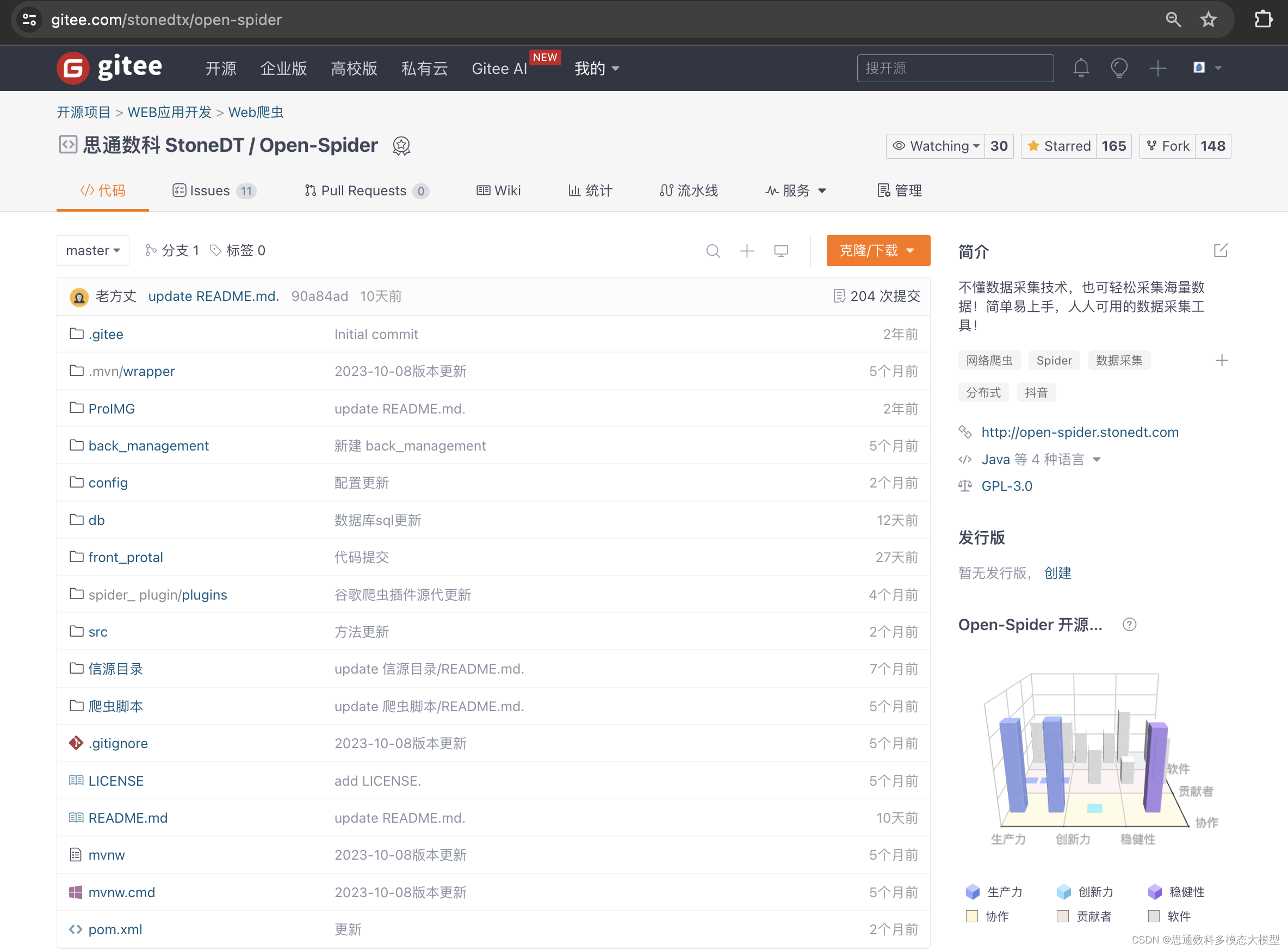
8. 系统架构设计:思通数科在系统架构设计方面展现了前瞻性,其架构设计目标是解决当前和未来软件系统由于复杂度可能带来的问题,确保系统的可持续发展。
9. 数据处理能力:除了数据采集,思通数科还提供了数据处理的相关技术,这包括对采集数据的清洗、分类、分析等,以支持更深层次的数据分析和知识图谱构建。
综上所述,思通数科的爬虫抓取和信息采集技术在自动化、智能化、系统架构设计以及开源贡献方面表现突出,能够为各种规模的项目提供强大的数据支持。
Open-Spider项目地址:https://gitee.com/stonedtx/open-spider

















 355
355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









