



 本文指导参赛者使用AI技术,通过读取、分析、清洗电力数据,构建预测模型,以提升充电站运营效率。涉及步骤包括数据加载、分组聚合、特征提取、模型训练与验证,以及优化数据处理以改善预测效果。
本文指导参赛者使用AI技术,通过读取、分析、清洗电力数据,构建预测模型,以提升充电站运营效率。涉及步骤包括数据加载、分组聚合、特征提取、模型训练与验证,以及优化数据处理以改善预测效果。
手把手带打一场时间序列实践
参考链接:https://datawhaler.feishu.cn/docx/C6jvdEwsSo3JMwxFj1FcTEqtn1g
任务:参赛者基于现有数据,利用人工智能相关技术,建立预测模型来预测未来一段时间内的需求电量,帮助管理者提高充电站的运营效益和服务水平,促进电动汽车行业的整体发展。
具体步骤:
一、读取数据集
train_power_forecast_history = pd.read_csv(‘./data1/train/power_forecast_history.csv’)
train_power = pd.read_csv(‘./data1/train/power.csv’)
train_stub_info = pd.read_csv(‘./data1/train/stub_info.csv’)
test_power_forecast_history = pd.read_csv(‘./data1/test/power_forecast_history.csv’)
test_stub_info = pd.read_csv(‘./data1/test/stub_info.csv’)
二、数据分析
利用groupby函数进行分组聚合
充电量分组聚合求和
将充电量合并
train_df = train_power_forecast_history.groupby([‘id_encode’,‘ds’]).head(1)##分类组合
del train_df[‘hour’]
test_df = test_power_forecast_history.groupby([‘id_encode’,‘ds’]).head(1)
del test_df[‘hour’]
tmp_df = train_power.groupby([‘id_encode’,‘ds’])[‘power’].sum()
tmp_df.columns = [‘id_encode’,‘ds’,‘power’]
绘制折线图,查看每个站点的情况如周期性、趋势性、相关性和异常性等。
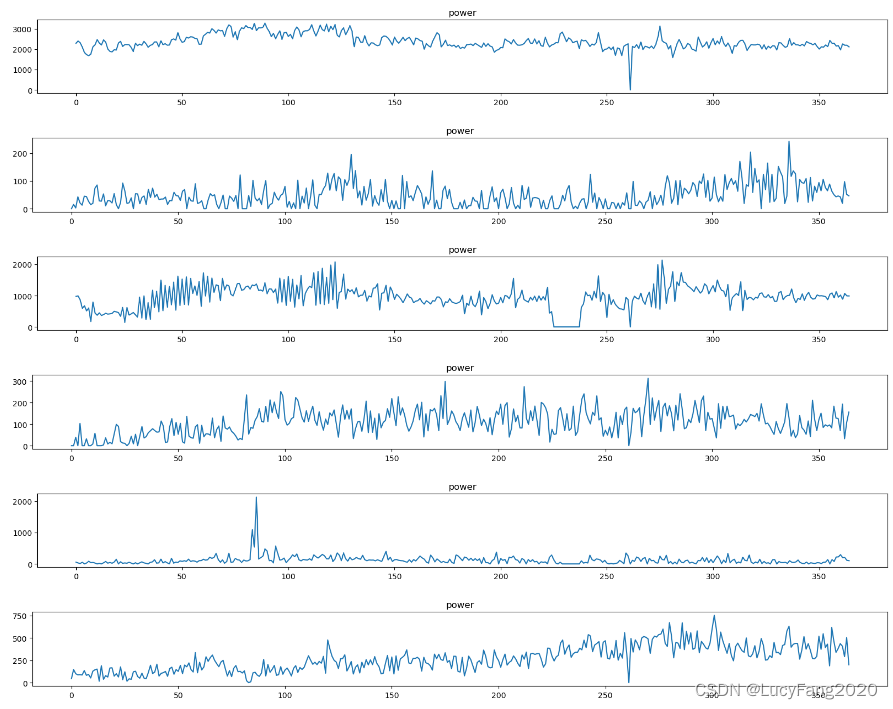
三、数据清洗
1、将标签由字符串转为0,1;
2、将f3四舍五入取整。
四、特征工程
将“时间”变量转换为datetime格式,然后提取月、日、小时、周等相关特征,主要是为了刻画不同时间阶段可能存在的一致性信息。
五、模型训练与验证
1、K折交叉验证会把样本数据随机的分成K份;
2、每次随机的选择K-1份作为训练集,剩下的1份做验证集;
3、当这一轮完成后,重新随机选择K-1份来训练数据;
4、最后将K折预测结果取平均作为最终提交结果。
六、输出结果
七、小结
时间序列的基本思路如上所示,但是结果不是很理想,需要对数据进行进一步处理,才可能得到更好的结果。


















 8798
8798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









