




一、Transformer:架构的起源与本质
2017 年,Google 的研究团队在那篇具有开创性的论文《Attention Is All You Need》中,正式揭开了 Transformer 的神秘面纱。从本质上讲,Transformer 是一种 “序列到序列 (seq2seq)” 的机器学习模型架构,其核心功能是将一种序列形式的数据精准地转换为另一种序列形式的数据。这种架构的出现,为众多自然语言处理和其他序列相关任务带来了革命性的变化。
- Transformer 架构:Encoder 与 Decoder 的协同运作
Transformer 架构的核心组件是 Encoder(编码器)和 Decoder(解码器),它们可依据任务类型单独发挥作用。
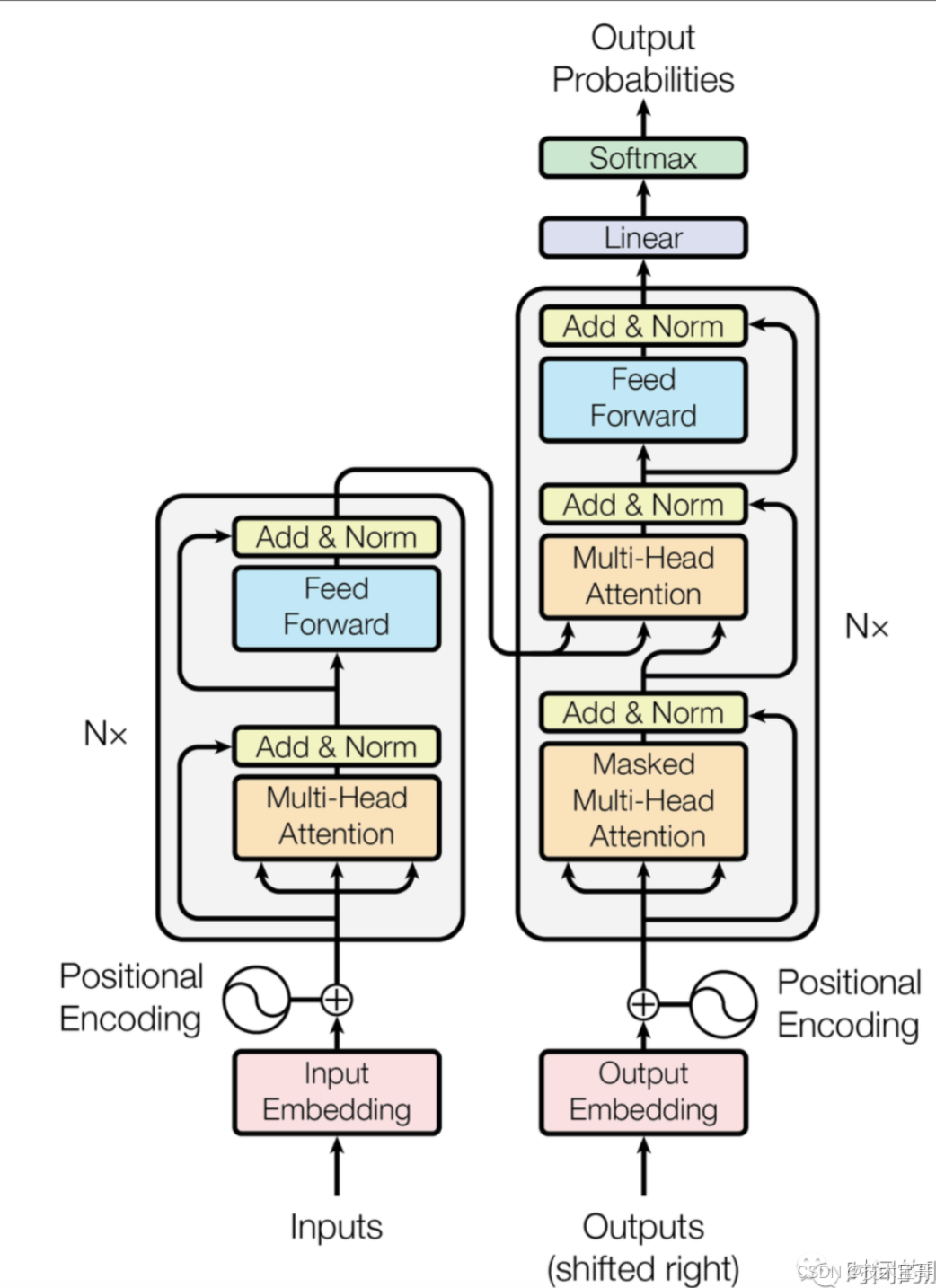
(一)Encoder 的工作原理
在信息序列踏入 Encoder 的大门之前,首先要经历一个重要的预处理步骤 —— 向量化处理,即将信息转化为 Embedding 向量。然而,这一转化过程虽然赋予了信息在机器世界中的可计算性,但同时也导致了一个问题:向量中的每个元素变得同等重要,从而使得序列中元素原本的位置信息丢失。
位置信息对于信息序列的理解至关重要。想象一下翻译一个句子,如果单词的顺序被打乱,翻译工作将会变得极其困难,甚至无法进行。为了解决这个问题,我们需要对向量进行位置编码,巧妙地将每个元素的位置信息融入到向量之中。
携带了位置信息的 Embedding 向量进入 Encoder 后,会经历一个关键的环节 ——8 个头的 Self Attention(自注意力)机制。这一机制如同一位敏锐的洞察者,能够将输入信息中隐含的 8 个不同维度的内在关联清晰地揭示出来,为后续的处理提供丰富而有价值的信息。
(二)Decoder 的工作流程
Decoder 的工作遵循一种循环迭代的预测逻辑,即通过不断预测下一个元素出现的概率来生成目标序列。每完成一次预测,就会将这一轮的预测结果作为新的输入,开启下一轮的预测,直到所有元素都被成功预测。
以翻译 “怪兽没有穿过街道,因为它太累了” 这句话为例,最初提供给 Decoder 的输入仅仅是一个起始标志<start>。在第一轮预测中,模型输出 “The”;第二轮输入变为<start> The,进而预测出 “monster”。依此类推,通过不断循环迭代,最终完成整个句子的翻译。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 958
958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









