 云服务器搭建Hadoop伪分布式
云服务器搭建Hadoop伪分布式




目录
5.1 修改配置文件core-site.xml和hdfs-site.xml
写在前面
封面与本文无关
笔者这学期学习了一门专业课“大数据技术导论”,接触到了许多全新的知识和技术栈,故简单记录一下学习过程。
(⚠️⚠️⚠️本文不是hadoop安装和实操教程!笔者才疏学浅,内容如有错误,欢迎指正)
关于Hadoop的介绍已经有很多非常详细的文章进行讲解,在此本文不过多赘述,主要是我自己也不明白😂
以下内容是一个入门级别的实验过程,在这个实验中我凭借一点粗浅的Linux知识——以及教材的实验指导,以及豆包老师和deep seek老师的现场答疑——在Linux系统上搭建了Hadoop平台,并且让它成功运行了一个简单的数据分析任务。
(PS:详细可参考厦门大学林子雨教授的教程
https://dblab.xmu.edu.cn/blog/2441/
实验环境
我曾斥巨资买了阿里云服务器(Cent OS 7.9 64位),免去了安装虚拟机的麻烦。
连接服务器有两种方式,一是进入官方网站下的控制台,点击远程连接
二是直接在Windows电脑的终端里通过ssh命令连接
要注意的是IP地址一定要是公网IP。

实验步骤📚
(一)准备工作
1.1创建hadoop用户:
需要创建一个专门的 hadoop 用户来管理 Hadoop 服务,避免使用 root 用户直接操作以提升安全性。
具体步骤:
1.创建 hadoop 用户:adduser hadoop
2.设置用户密码:passwd hadoop
3.将 hadoop 用户加入 sudo 组:usermod -aG sudo hadoop
4.切换到刚刚创建的hadoop用户:su - hadoop
1.2 下载vim:
通过CentOS的包管理器yum下载,执行命令:sudo yum install vim -y
1.3 配置SSH无密码登录
云服务器已经安装SSH客户端和服务器端,但需要进行SSH无密码配置
为什么需要进行SSH无密码配置
呃,不执行这一步的话后续启动HDFS会报错
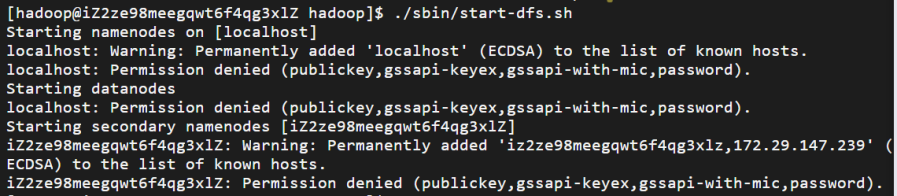
我的前车之鉴,启动 HDFS 时出现了 Permission denied(权限被拒绝) 错误,核心原因是 hadoop 用户缺少 SSH 免密登录本地服务器的权限。Hadoop 启动 start-dfs.sh 时,会通过 SSH 连接到本地节点(localhost 或服务器 hostname)来启动 NameNode、DataNode 等进程。但当前 hadoop 用户登录本地 SSH 时需要密码,且未配置免密登录,导致启动脚本无法自动完成连接,从而报权限错误。
SSH即 secure shell,就是安全地远程敲命令,简单来说,NameNode需要通过SSH去启动DataNode,所以我们需要在服务器内部创建一个信任关系让服务器自己通过SSH登录自己
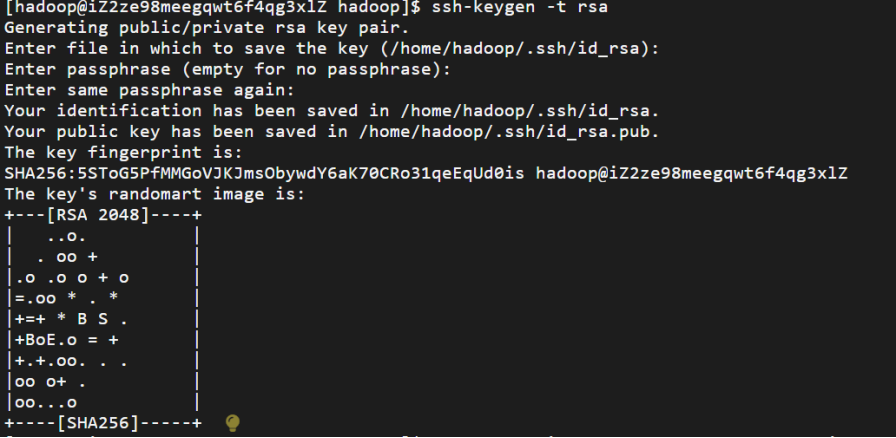
1.生成SSH密钥对,执行后会在 ~/.ssh/ 目录下生成私钥 id_rsa 和公钥 id_rsa.pub。(私钥是服务器自己保存,公钥是给别人)
2.将公钥添加到授权列表(允许免密登录)
3.修改授权文件权限(SSH 对权限要求严格,必须执行)
4.验证免密登录是否生效

到这里免密登录就配置好了
(二)安装Java环境
2.1 安装jdk
进入/usr/lib目录,通过sudo mkdir jvm创建java的安装目录
执行sudo yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel -y
通过ls查看目录下的安装文件
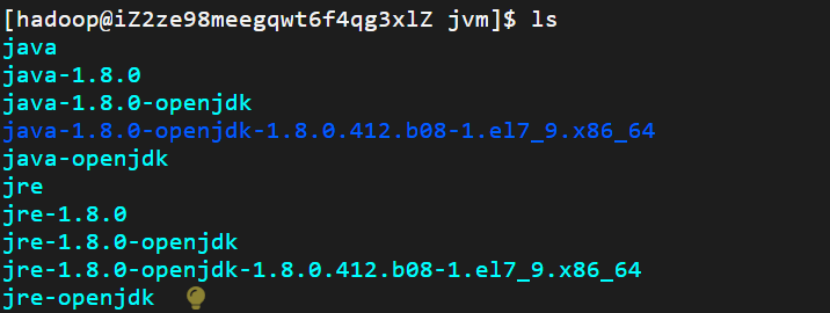
(阿里云还是非常贴心啊,知道我这个小白可能啥也看不懂,点击黄色的小灯泡每行命令和输出还有ai进行讲解)
2.2 配置环境变量
编辑环境变量配置文件:vim ~/.bash_profile在文件末尾添加:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.412.b08-1.el7_9.x86_64 export PATH=$JAVA_HOME/bin:$PATH
执行source ~/.bash_profile使配置生效。
通过echo $JAVA_HOME,可以验证配置正确.该命令正常执行,输出了环境变量 JAVA_HOME 的值,显示为 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.412.b08-1.el7_9.x86_64。这表明系统中已正确配置并安装了指定版本的 OpenJDK 1.8。
最后输出java -version,可以看到该输出显示系统中安装的是 OpenJDK 1.8.0_412 版本,这是一个正常的 Java 版本查询结果。输出内容包含了运行环境和虚拟机的具体构建信息,表明 Java 环境已正确安装并可正常使用。

(三)Hadoop安装
我本来想在终端直接从官方镜像下载:
wgethttps://archive.apache.org/dist/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
但下载速度太慢,于是我先下载到我的Windows电脑本地,再在powershell中通过scp命令(基于SSH的安全文件传输协议),上传到云服务器,存储在hadoop用户的/home/hadoop目录下

登录云服务器,使用 sudo 权限将文件移动到 /usr/local/ 目录。sudo mv /home/hadoop/hadoop-3.3.6.tar.gz /usr/local/
进入 /usr/local 目录,执行解压命令(需 sudo 权限,因为 /usr/local 是系统目录):
sudo tar -zxvf hadoop-3.3.6.tar.gz -C /usr/local/
命令解释
sudo:获取管理员权限;
tar -zxvf:解压 tar.gz 格式压缩包的固定参数(z= 处理 gzip 压缩,x= 解压,v= 显示解压过程,f= 指定压缩包文件);
hadoop-3.3.6.tar.gz:要解压的文件名;
-C /usr/local/:指定解压后的文件存放目录(这里就是 /usr/local,解压后会生成 hadoop-3.3.6 子目录)。
解压后会生成 hadoop-3.3.6 文件夹,可重命名为 hadoop(后续配置环境变量更简洁):sudo mv ./hadoop-3.1.3/ ./hadoop
为了让 hadoop 用户拥有对解压后目录的完整操作权限,执行:sudo chown -R hadoop:hadoop /usr/local/hadoop/
chown -R:递归修改目录及所有子文件的所有者;
hadoop:hadoop:将所有者和所属组都设为 hadoop 用户,避免后续操作权限不足。
输入命令./bin/hadoop version来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
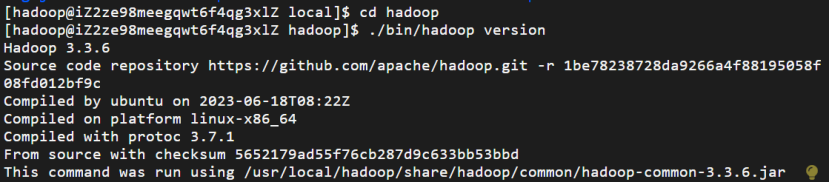
该输出显示 Hadoop版本信息,表明Hadoop已成功安装并运行。版本为3.3.6,编译时间为2023年6 月18日,使用的平台是linux-x86_64,并且提供了源代码仓库链接和校验码等详细信息。这是一个正常的命令执行结果,没有报错。

(四)Hadoop单机配置(非分布式)
Hadoop 默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
Hadoop本身可以在计算机集群环境下运行,这里在本地模式中运行也就是只在一台机器上运行,不联网,不分任务
现在我们可以执行例子来感受下 Hadoop 的运行。Hadoop 附带了丰富的例子,
运行
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar
可以看到所有例子,包括 wordcount、terasort、join、grep 等。
在此我们选择运行 grep 例子.在/usr/local/hadoop文件夹下新建文件夹input,然后将/usr/local/hadoop/etc/hadoop目录下的配置文件复制到input目录,命令:
cp ./etc/hadoop/*.xml ./input
接下来,我们将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词(就是dfs开头的单词)并统计出现的次数,最后输出结果到 output 文件夹中。
通过ls查看iuput文件夹中文件如下:


执行命令后,输出了很长的一段日志信息:
部分如下:
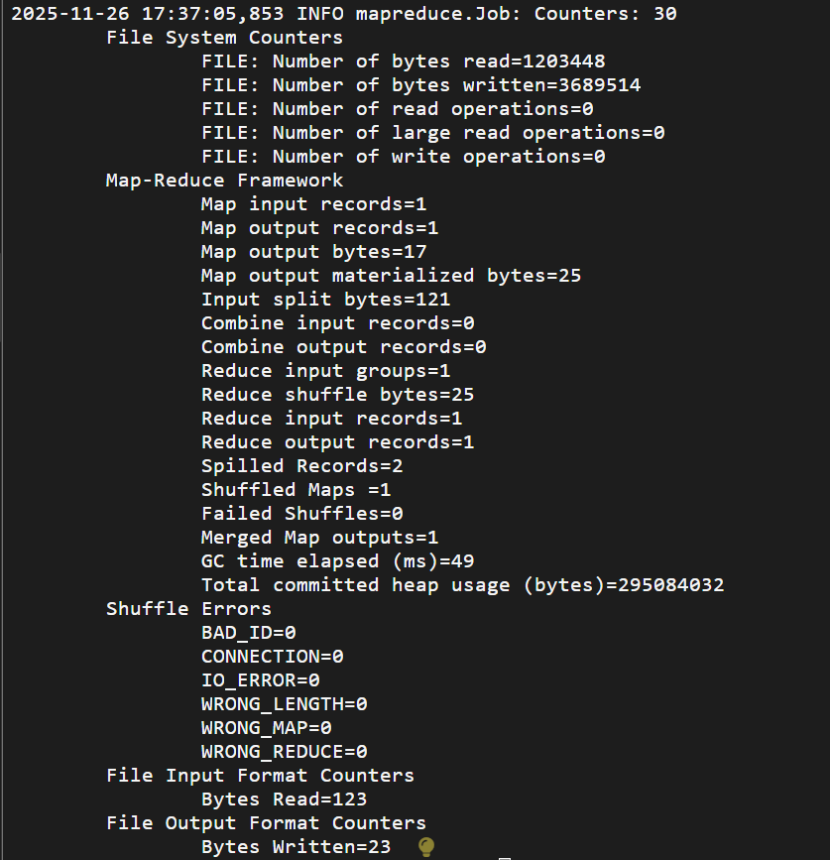
执行成功后如下所示,输出了作业的相关信息,输出的结果是符合正则的单词 dfsadmin 出现了1次

(五)Hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
5.1 修改配置文件core-site.xml和hdfs-site.xml

Hadoop配置文件说明:
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。
5.2 配置完成后,执行 NameNode 的格式化
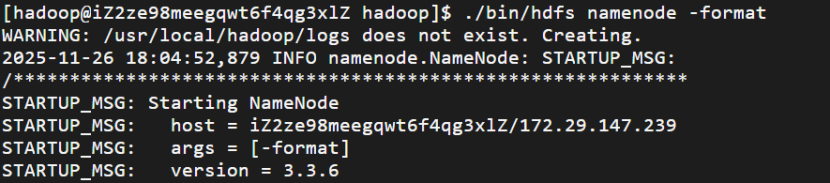

命令解释:
该日志显示 Hadoop 的 NameNode 正在执行格式化操作,并成功完成了初始化过程。
整个流程是典型的首次启动或重新初始化 Hadoop 集群时的操作步骤,没有出现错误。如果是在首次部署或者重置环境,这是预期的行为。如果已经存在数据不希望被清空,请注意不要重复执行 -format 操作。
5.3 开启NameNode和DataNode守护进程
这里我运行./sbin/start-dfs.sh遇到了一个问题

出现了 ERROR: JAVA_HOME is not set and could not be found 错误,核心原因是 Hadoop 无法识别到 JAVA_HOME 环境变量(即 JDK 安装路径未正确配置)
错误本质:Hadoop 启动脚本(如 start-dfs.sh)依赖 JAVA_HOME 来定位 JDK 路径,但当前系统中该变量未被正确设置或未被 Hadoop 识别。
影响范围:NameNode、DataNode、SecondaryNameNode 等 HDFS 核心进程均因找不到 JDK 而无法启动。
解决方法:在 Hadoop 配置中明确指定 JAVA_HOME,需在 Hadoop 的环境配置文件中强制设置 JAVA_HOME(即使系统环境变量已配置,Hadoop 有时也需要单独指定)
编辑 Hadoop 的环境配置文件 hadoop-env.sh:
 在文件中找到或添加以下内容export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.412.b08-1.el7_9.x86_64
在文件中找到或添加以下内容export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.412.b08-1.el7_9.x86_64
重新启动HDFS,终于,成功了!!!

启动完成后,可以通过命令 jps 来判断是否成功启动

命令解释:
该输出显示了当前系统中正在运行的Java进程及其对应的PID进程标识符。jps命令用于列出所有正在运行的JVM进程。
7472 NameNode:这是HDFS中的主节点服务,负责管理文件系统的命名空间和客户端请求。
7768 SecondaryNameNode:辅助NameNode进行一些检查点操作,以防止NameNode出现单点故障。
7583 DataNode:HDFS的工作节点,负责存储实际的数据块并执行来自NameNode的操作指令。
8895 Jps:即当前执行的jps命令本身也是一个Java进程。
这些信息表明系统上已经成功启动了Hadoop的相关服务,并且它们都在正常运行中。
(六)运行Hadoop伪分布式实例
好的,什么是伪分布式,我们还是只有一台机器,但是让它在内部模拟一个小集群,即NameNode和DataNode在同一台机器上,仍然是统计词频的任务,但这次我们把数据上传在HDFS里,而不是本地硬盘
上面的单机模式,grep 例子读取的是本地数据,伪分布式读取的则是 HDFS 上的数据。要使用 HDFS,首先需要在 HDFS 中创建用户目录:
实际上有三种shell命令方式。
1. hadoop fs
2. hadoop dfs
3. hdfs dfs
hadoop fs适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
hadoop dfs只能适用于HDFS文件系统
hdfs dfs跟hadoop dfs的命令作用一样,也只能适用于HDFS文件系统
接着将 ./etc/hadoop 中的 xml 文件作为输入文件复制到分布式文件系统中,即将 /usr/local/hadoop/etc/hadoop复制到分布式文件系统中的 /user/hadoop/input中。我们使用的是 hadoop 用户,并且已创建相应的用户目录 /user/hadoop ,因此在命令中就可以使用相对路径如 input,其对应的绝对路径就是 /user/hadoop/input:

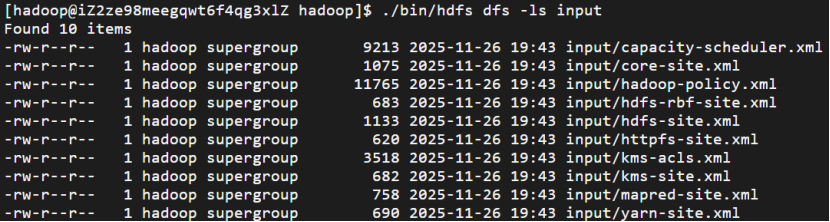
伪分布式运行 MapReduce 作业的方式跟单机模式相同

查看运行结果的命令(查看的是位于 HDFS 中的输出结果):

关闭 Hadoop


















 966
966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









