







一、概述
Linux内核链表和C++ STL链表都是用于存储和管理数据的一种链表结构。Linux内核链表更侧重于操作系统内部的高效性和灵活性,而C++ STL链表则提供了一种用户友好的数据结构操作接口,适合于一般应用开发。
Linux内核链表:
-
用途:
- 主要用于内核开发和操作系统内部的数据结构管理。
- 适合高效地管理进程、任务、设备驱动程序等内核对象。
- 支持复杂的系统级操作,如插入、删除、遍历等,有助于内核模块间的交互。
-
特点:
- 使用宏定义实现,灵活性高,适用于多种复杂场景。
- 支持双向链表,允许在前后方向上遍历。
- 为了性能优化,通常不使用自
malloc的方式,直接在内核内存管理系统中运作。
C++ STL链表:
-
用途:
- 主要用于用户级应用程序中的数据存储和管理。
- 适合通用场景,如实现队列、栈或其他数据结构。
- 提供方便的API,可以与泛型编程结合使用。
-
特点:
- 提供了易于使用的接口和动态内存管理。
- 支持单向链表(
std::forward_list)和双向链表(std::list)。 - 提供迭代器,使得遍历和操作链表变得简单直观。
二、链表基础知识
这里再简单阐述一下链表的基础知识。链表(Linked List)是一种线性数据结构,其中的元素(称为节点)通过指针连接起来。每个节点包含两部分:数据部分(用于存储数据元素)与指针(指向下一个节点的地址)。

根据节点之间的连接方向,链表可以分为以下几种类型:
-
单链表(Singly Linked List):每个节点包含一个指向下一个节点的指针。这种类型的链表只能从第一个节点开始单向遍历,无法从中间或末尾节点向前查找。
-
双链表(Doubly Linked List):每个节点包含两个指针,一个指向下一个节点,另一个指向前一个节点。这种结构允许双向遍历,也可以方便地插入和删除节点。
-
循环链表(Circular Linked List):最后一个节点的指针指向列表的第一个节点,形成一个环。这种结构允许从任意位置开始循环访问。
-
动态链表:链表的长度在运行时可以动态变化,可通过插入或删除节点来增加或减少长度。
插入(Insert)操作: 在链表中添加一个新节点。复杂度 通常为O(1)(若插入位置已知),否则需要O(n)(遍历链表到达插入位置)。
-
单链表:
- 头部插入:在链表的头部插入一个新节点,更新头指针指向新节点。
- 尾部插入:在链表的尾部插入一个新节点,通常需要遍历到链表末尾,然后将新节点的指针指向
NULL。 - 中间插入:在链表的指定位置插入一个新节点,需调整插入位置前后节点的指针,使其指向新节点。
-
双链表:除了更新前后节点的指针外,还需要调整新节点的前向和后向指针,使其正确连接到链表中。
-
循环链表:在插入操作中,需要特别注意维护循环结构,使得插入后的链表依然形成环形。
删除(Delete)操作:从链表中移除一个节点。复杂度一般为O(1)(若删除位置已知),否则需要O(n)(遍历链表到达删除位置)。
-
单链表:
- 删除头节点:更新头指针指向原头节点的下一个节点,然后释放原头节点的内存。
- 删除尾节点:遍历链表找到尾节点的前一个节点,将其指针指向
NULL,然后释放尾节点的内存。 - 删除中间节点:调整删除节点前后的节点指针,绕过删除节点,释放其内存。
-
双链表:除了更新前后节点的指针外,还需要正确处理删除节点的前向和后向指针,使链表保持一致性。
-
循环链表:删除节点时需特别注意保持循环结构的正确性,确保删除操作不会破坏环形连接。
查找(Search)操作:在链表中查找指定值的节点。复杂度通常为O(n),因为在链表中查找节点需要从头节点开始逐个遍历直到找到目标节点或遍历完所有节点。
-
单链表:从头节点开始,逐个节点遍历,直到找到目标节点或到达链表末尾。
-
双链表:同样从头节点开始,遍历每个节点;也可以从尾节点开始查找(如果链表长度较长,会更高效)。
-
循环链表:需要注意链表的循环结构,需要设置一个标志以避免无限循环。
示例:
#include <iostream>
// 链表节点结构体
struct Node {
int data;
Node* next;
Node(int value) : data(value), next(nullptr) {}
};
// 链表类
class LinkedList {
private:
Node* head;
public:
LinkedList() : head(nullptr) {}
// 插入一个节点
void insert(int value) {
Node* newNode = new Node(value);
if (head == nullptr) {
head = newNode;
} else {
Node* temp = head;
while (temp->next != nullptr) {
temp = temp->next;
}
temp->next = newNode;
}
}
// 删除一个节点
void remove(int value) {
if (head == nullptr) return;
// 特殊情况:删除头节点
if (head->data == value) {
Node* temp = head;
head = head->next;
delete temp;
return;
}
Node* current = head;
Node* previous = nullptr;
while (current != nullptr && current->data != value) {
previous = current;
current = current->next;
}
// 找到了要删除的节点
if (current != nullptr) {
previous->next = current->next;
delete current;
}
}
// 查找一个节点
bool find(int value) {
Node* current = head;
while (current != nullptr) {
if (current->data == value) {
return true; // 找到
}
current = current->next;
}
return false; // 没有找到
}
// 打印链表
void print() {
Node* current = head;
while (current != nullptr) {
std::cout << current->data << " -> ";
current = current->next;
}
std::cout << "nullptr" << std::endl;
}
~LinkedList() {
while (head != nullptr) {
Node* temp = head;
head = head->next;
delete temp;
}
}
};
int main() {
LinkedList list;
// 插入节点
list.insert(10);
list.insert(20);
list.insert(30);
// 打印链表
std::cout << "链表内容: ";
list.print();
// 查找节点
std::cout << "查找20: " << (list.find(20) ? "找到" : "未找到") << std::endl;
std::cout << "查找40: " << (list.find(40) ? "找到" : "未找到") << std::endl;
// 删除节点
std::cout << "删除20" << std::endl;
list.remove(20);
// 再次打印链表
std::cout << "链表内容: ";
list.print();
return 0;
}
链表的优点:
- 动态分配:链表可以在运行时动态地调整长度,非常适合当不需要预先知道数据量大小时使用。
- 插入与删除操作:在链表中插入或删除元素的时间复杂度通常为O(1),操作效率较高,尤其是当插入或删除操作发生在链表的中间位置时。
链表的缺点:
- 额外内存开销:每个节点除了存储数据外,还存储指向下一个节点的指针,导致额外的内存消耗。
- 随机访问效率低:与数组相比,链表不支持高效的随机访问,因为需要从头开始遍历到目标节点。
三、Linux内核链表
Linux内核链表的基本结构是通过struct list_head来实现的。
struct list_head {
struct list_head *next, *prev;
};
这个结构体包含两个指针,分别指向链表中的下一个节点和上一个节点。具体来说:
next: 指向链表中下一个节点的list_head结构。prev: 指向链表中上一个节点的list_head结构。
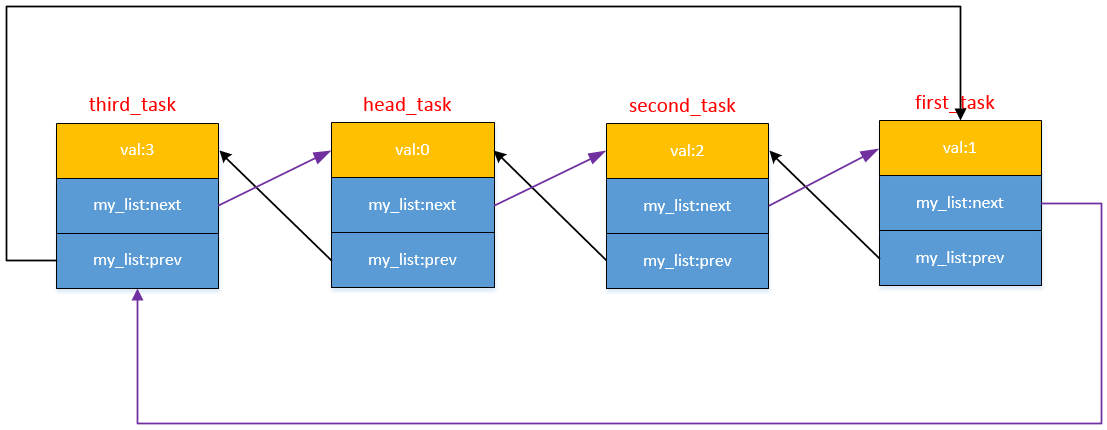
这样设计使得链表可以很方便地进行双向遍历。为了使用这个结构体,通常需要定义一个具体的数据结构,然后在这个数据结构中嵌入一个struct list_head成员。例如:
struct my_data {
int value;
struct list_head list;
};
初始化一个链表可以通过如下的方法:
-
使用
INIT_LIST_HEAD宏:struct list_head my_list; INIT_LIST_HEAD(&my_list); -
如果定义了一个链表节点,可以在定义时进行初始化:
struct my_struct { int data; struct list_head list; }; struct my_struct my_node; INIT_LIST_HEAD(&my_node.list); -
也可以使用
LIST_HEAD宏来直接定义并初始化一个链表:LIST_HEAD(my_list);
Linux内核提供了一组宏和函数用于操作链表,这些操作主要基于双向链表的实现。
在Linux内核中,通常会定义一个链表头节点,使用struct list_head结构体表示。
#include <linux/list.h>
struct list_head my_list; // 定义一个链表头
INIT_LIST_HEAD(&my_list); // 初始化链表
使用list_for_each和list_for_each_entry等宏来遍历链表。
遍历链表节点:
struct list_head *pos;
list_for_each(pos, &my_list) {
struct my_struct *entry = list_entry(pos, struct my_struct, list);
// 在这里对entry进行操作
}
遍历包含特定结构的链表:
struct my_struct {
int data;
struct list_head list; // 用于链表的结构体
};
// 遍历具体的结构体
struct my_struct *entry;
list_for_each_entry(entry, &my_list, list) {
// 对entry进行操作
}
使用list_add和list_add_tail来插入节点。
struct my_struct *new_node = kmalloc(sizeof(struct my_struct), GFP_KERNEL);
INIT_LIST_HEAD(&new_node->list);
new_node->data = 10;
// 在链表头插入
list_add(&new_node->list, &my_list);
// 在链表尾插入
list_add_tail(&new_node->list, &my_list);
使用list_del来删除节点。
list_del(&entry->list); // entry是要删除的节点
kfree(entry); // 释放内存
完整示例:
#include <linux/init.h>
#include <linux/module.h>
#include <linux/list.h>
#include <linux/slab.h>
struct my_struct {
int data;
struct list_head list;
};
static LIST_HEAD(my_list);
static int __init my_module_init(void) {
struct my_struct *new_node;
// 插入节点
new_node = kmalloc(sizeof(struct my_struct), GFP_KERNEL);
new_node->data = 1;
list_add(&new_node->list, &my_list);
new_node = kmalloc(sizeof(struct my_struct), GFP_KERNEL);
new_node->data = 2;
list_add_tail(&new_node->list, &my_list);
// 遍历链表
struct my_struct *entry;
list_for_each_entry(entry, &my_list, list) {
printk("data: %d\n", entry->data);
}
return 0;
}
static void __exit my_module_exit(void) {
struct my_struct *entry, *temp;
list_for_each_entry_safe(entry, temp, &my_list, list) {
list_del(&entry->list);
kfree(entry);
}
}
module_init(my_module_init);
module_exit(my_module_exit);
MODULE_LICENSE("GPL");
四、C++ STL链表
std::list 是 C++ 标准库中提供的一种容器类,属于 STL(标准模板库)的一部分。它实现了双向链表的数据结构,可以存储任意类型的数据。
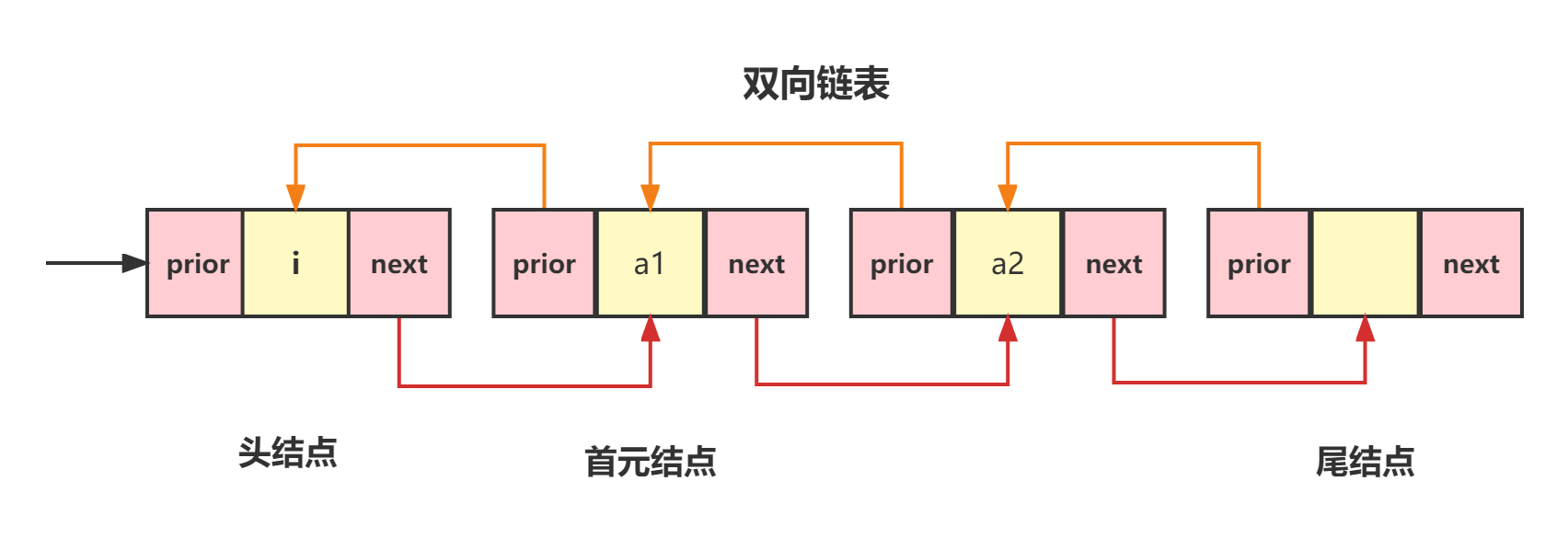
std::list 的定义如下:
#include <list>
std::list<Type> myList;
这里,Type 是希望存储的元素类型。
特性:
-
std::list是一个双向链表,允许在链表的任意位置插入和删除元素。 -
它的大小可以动态变化,无需预先定义大小。
-
每个元素都有指向前一个和后一个元素的指针,这使得在链表中从任意位置插入或删除节点非常高效。
-
与
std::vector等容器不同,std::list中的元素并不必须存储在连续的内存块中。在插入和删除操作频繁的情况下,std::list比std::vector更高效,因为不需要移动其他元素。 -
std::list提供双向迭代器,可以方便地遍历链表。 -
性能:
- 插入和删除操作的平均时间复杂度为 O(1),前提是已知位置(如将在链表中迭代到达该位置)。
- 访问元素的时间复杂度为 O(n),因为需要从头部或尾部遍历。
-
std::list不支持随机访问迭代器,因此不能使用下标运算符[]来直接访问元素。 -
由于每个元素需要额外的指针来存储前后元素的地址,因此
std::list相比std::vector会消耗更多的内存。 -
提供了成员函数
sort()和merge()可以方便地对列表进行排序和合并操作。
示例代码:
#include <iostream>
#include <list>
int main() {
std::list<int> myList;
// 添加元素
myList.push_back(1);
myList.push_back(2);
myList.push_front(0);
// 遍历列表
for (int x : myList) {
std::cout << x << " ";
}
std::cout << std::endl;
// 删除元素
myList.remove(1);
// 再次遍历
for (int x : myList) {
std::cout << x << " ";
}
std::cout << std::endl;
return 0;
}
五、内核链表与STL链表的对比
内核链表非常轻量级,不包含额外的成员变量,只有指针。由于内核链表操作是在内核上下文中进行的,其设计侧重于简单、高效。
C++ STL 链表有更多的功能,例如迭代器支持、内存管理(如分配和释放节点内存),以及额外的成员函数如 push_front, push_back, remove 等。
内核链表主要功能是插入和删除节点,设计上比较简单,通常没有复杂的操作。适用于内核模块、同步机制、调度、内存管理等需要高效管理对象的场景。
STL 链表提供更丰富的 API,支持复杂的操作,易于使用。支持与算法和其他数据结构的结合,适合日常应用程序开发中使用。
内核链表性能方面,由于没有额外的开销(如内存管理、异常处理),在内核中运行时效率非常高。STL 链表性能略逊于内核链表的原因在于需要进行更多的内存管理和功能支持。
六、总结
内核链表和 STL 链表是两种设计哲学不同的数据结构。内核链表注重轻量级和高效的内存使用,适合内核级别的任务;而 STL 链表则更关注功能的丰富性和易用性,适合一般的软件开发需求。




















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











