







如何在c++中分割字符串
一、简介
如何在C++中分割字符串?这是一个简单的问题,但在C++中有多个方案可以解决。本文将看到3种解决方案,每种解决方案都有优点和缺点。这篇文章的目的还在于展示迭代器接口如何超越简单容器的范围。这说明了STL的设计是多么强大。
- 解决方案1:使用标准组件。
- 解决方案2更好,但依赖于boost。
- 解决方案3更进一步优化,但使用了范围。
所以你的选择取决于你需要什么和你能接触到什么。

二、方案一:在流(stream)上迭代
2.1、了解流(stream)
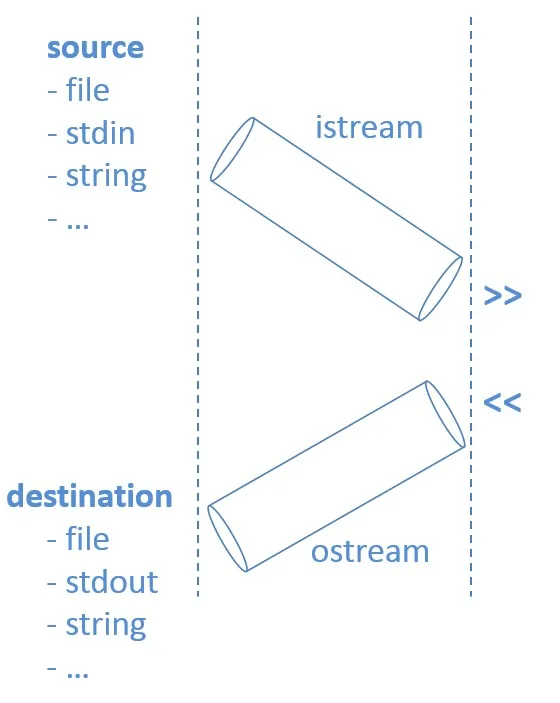
流是一个对象,它创建与感兴趣的源或目标的连接。流可以从源(std:: iststream)获取信息,也可以向目标(std::ostream)提供信息,或者两者兼而有之(std::iostream)。
感兴趣的源和目标通常可以是标准输入(std::cin)或输出(std::cout),一个文件或一个字符串,但实际上任何东西都可以连接到流,只要适当的机制被设置好。
在流上执行的主要操作有:
- 对于输入流:用
operator>>从中绘制一些东西。 - 对于输出流:使用
operator<<将一些内容压入其中。
如下图所示:
连接到字符串的输入流std::istringstream有一个有趣的属性:它的operator>> 会产生一个字符串,直到源字符串中的下一个空格为止。
std::istream_iterator是一个可以连接输入流的迭代器。它提供了输入迭代器的常规接口(++,解引用),但它的operator++实际上是在输入流上绘制。
istream_iterator是根据它从流中提取的类型模板化的。使用istream_iterator<std::string>将从流中绘制一个字符串,并在解引用时提供一个字符串:
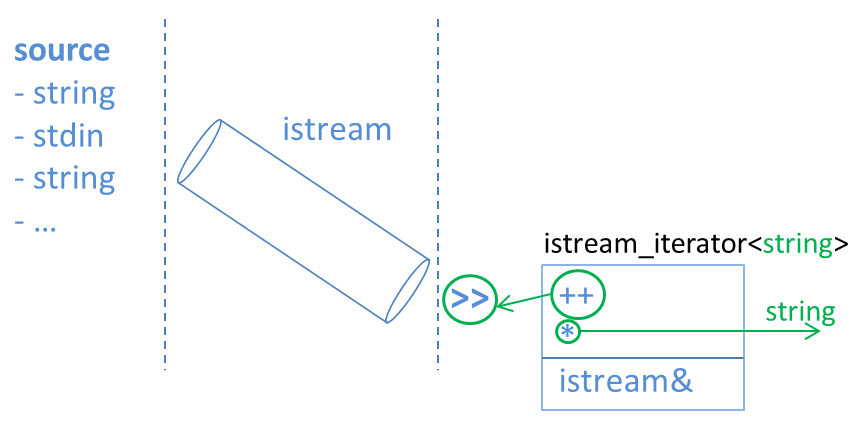
当流无法从其源中提取更多内容时,它会向迭代器发出信号,并且迭代器被标记为已完成。
2.1、解决方案 1.1
现在有了迭代器接口,可以使用算法,这真正展示了STL设计的灵活性。为了能够使用STL,需要一个开始(begin)和一个结束(end)。开始将是对未处理的字符串进行划分的迭代器:std::istream_iterator<std::string>(iss)。对于结束,按照惯例,一个默认构造的istream_iterator被标记为已完成:std::istream_iterator<string>():
std::string text = "Let me split this into words";
std::istringstream iss(text);
std::vector<std::string> results((std::istream_iterator<std::string>(iss)),
std::istream_iterator<std::string>());
第一个参数中的额外圆括号是为了消除函数调用的歧义。在C++ 11中,可以使用大括号来使用统一的初始化来解决这个令人烦恼的现象:
std::string text = "Let me split this into words";
std::istringstream iss(text);
std::vector<std::string> results(std::istream_iterator<std::string>{iss},
std::istream_iterator<std::string>());
优势:
- 仅使用标准组件。
- 适用于任何流,而不仅仅是字符串。
缺点:
- 除了空格,它不能以其他字符作为分裂字符,这可能是个问题,比如解析CSV时就无法完成期望操作。
- 在性能方面还有改进的空间(但在你的性能分析没有证明这是瓶颈之前,这并不是一个真正的问题)。
- 仅仅分割一个字符串就需要大量的代码!
2.2、解决方案 1.2: 改进 operator>>
以上两个缺点的原因都在于同一处:由istream_iterator调用的operator>>,它从流中提取字符串。这个operator>>实际上做了许多事情:在下一个空格停止(这是最初想要的,但无法自定义),做一些格式化、读取和设置一些标志、构造对象等。而在这里大部分都不需要。
希望改变以下函数的行为:
std::istream& operator>>(std::istream& is, std::string& output)
{
// ...做了很多事情...
}
实际上不能改变这个,因为它在标准库中。不过可以用另一种类型重新定义它,但这个类型仍然需要有点像字符串。
因此,需要将字符串伪装成另一种类型。这有两种解决方案:继承自std::string,和用隐式转换包装一个字符串。在这里我们选择继承。
假设想根据逗号拆分字符串:
class WordDelimitedByCommas : public std::string
{};
不过,这有一点争议。std::string没有虚析构函数,因此不应该从它继承!继承本身并不会引起问题。当然,如果以指向std::string的指针形式删除WordDelimitedByCommas的指针,或出现切割问题,那么问题会发生。但一般不会这样做。现在能阻止有人去实例化一个WordDelimitedByCommas并冷酷地用它来破坏程序吗?不能。但这个风险值得冒吗?先看看好处,再来判断。
现在可以用operator>>重载它,只执行需要的操作:获取直到下一个逗号之间的字符。这可以通过getline函数实现:
std::istream& operator>>(std::istream& is, WordDelimitedByComma& output)
{
std::getline(is, output, ',');
return is;
}
(返回is允许链式调用operator>>。)
现在初始代码可以重写为:
std::string text = "Let,me,split,this,into,words";
std::istringstream iss(text);
std::vector<std::string> results((std::istream_iterator<WordDelimitedByComma>(iss)),
std::istream_iterator<WordDelimitedByComma>());
通过为WordDelimitedByComma类模板化,可以将其泛化至任何分隔符:
template<char delimiter>
class WordDelimitedBy : public std::string
{};
现在以分号为例拆分:
std::string text = "Let;me;split;this;into;words";
std::istringstream iss(text);
std::vector<std::string> results((std::istream_iterator<WordDelimitedBy<';'>>(iss)),
std::istream_iterator<WordDelimitedBy<';'>>());
优势:
- 允许在编译时指定任何分隔符。
- 可以在任何流上工作,不只是字符串。
- 比解决方案1.1快(快20到30%)。
缺点:
- 分隔符需要在编译时指定
- 不是标准的,但易于重用,
- 对于仅拆分一个字符串,仍需要很多代码!
2.3、解决方案1.3:远离迭代器
解决方案1.2的主要问题在于分隔符必须在编译时指定。事实上无法通过迭代器将分隔符传递给std::getline。因此,需要重构解决方案1.2,消除迭代器的层次:
std::vector<std::string> split(const std::string& s, char delimiter)
{
std::vector<std::string> tokens;
std::string token;
std::istringstream tokenStream(s);
while (std::getline(tokenStream, token, delimiter))
{
tokens.push_back(token);
}
return tokens;
}
在这里,利用了std::getline的另一个特性:它返回传递给它的流,而该流在C++11之前可以转换为bool(或void*)。这个布尔值指示是否发生了错误(如果没有发生错误,则为true,如果发生了错误,则为false)。而这个错误检查包括流是否已结束。
因此,当流(因此是字符串)的末尾被达到时,while循环会很好地停止。
优势:
- 非常清晰的接口
- 适用于任何分隔符
- 分隔符可以在运行时指定
缺点:虽然易于复用,但不是标准的。
三、方案二:使用boost::split
Boost库提供了一个更优的解决方案,名为boost::split。这个解决方案相对于之前的方案更出色(除非需要在任意流上使用)。
引入了boost库并使用了boost::split函数:
#include <boost/algorithm/string.hpp>
std::string text = "Let me split this into words";
std::vector<std::string> results;
boost::split(results, text, [](char c){return c == ' ';});
boost::split的第三个参数是一个函数(或函数对象),用于确定字符是否为分隔符。在这个示例中,使用了一个lambda函数,接受一个字符并返回该字符是否为空格。
boost::split的实现相当简单:它在字符串上执行多次find_if操作,查找分隔符,直到达到字符串末尾。需要注意的是,与之前的解决方案不同,如果输入字符串以分隔符结尾,boost::split将在结果中提供一个空字符串作为最后一个元素。
优势:
- 简单直观的接口。
- 允许使用任意分隔符,甚至多个不同的分隔符。
- 比解决方案1.1快60%。
缺点:
- 需要访问Boost库。
- 接口不通过返回类型输出结果。
四、方案三:使用范围(ranges)
即使范围(ranges)目前不像标准库甚至boost组件那样普遍可用,但范围是STL的未来,并且应该在未来几年内广泛可用。
为了对其有所了解,range-v3 库提供了一个非常好的界面,用于创建字符串的拆分视图:
std::string text = "Let me split this into words";
auto splitText = text | view::split(' ') | ranges::to<std::vector<std::string>>();
它还带有一些有趣的特性,比如,可以使用子字符串作为分隔符。范围包含在C++20中,希望能在未来几年内轻松地使用这一特性。
五、总结
那么,如何拆分字符串呢?如果可以访问boost库,那么尽量使用解决方案2。或者可以考虑编写自己的算法,就像boost一样,基于find_if来拆分字符串。
如果不想这样做,可以使用解决方案1.1,这是标准的,除非需要特定的分隔符,或者已经证明这是一个瓶颈,否则解决方案1.3非常适合。
当能够访问范围时,解决方案3应该是比较好的选择。




















 822
822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











