




 本文详细解析了sync.pool在Golang Gin框架中的应用,探讨了它如何通过减少内存分配和优化GC来提高性能。重点讲解了sync.pool的原理、使用方法,以及其在Context对象管理和fmt对象池中的运用。
本文详细解析了sync.pool在Golang Gin框架中的应用,探讨了它如何通过减少内存分配和优化GC来提高性能。重点讲解了sync.pool的原理、使用方法,以及其在Context对象管理和fmt对象池中的运用。
前言
最近在看golang web框架Gin的实现原理,Gin里面的Context对象使用和频繁,Gin通过sync.pool来对其进行管理,以优化GC。
sync.pool有什么能力,它是如何优化GC的呢,让我们来一探究竟。
正文
sync.pool是什么?
一个临时对象池,保存和复用临时对象,减少内存分配,降低GC压力。
sync.pool如何使用?
var bufPool = sync.Pool{
// 当池子中没有可用对象时,pool通过New创建一个新的
New: func() interface{} {
// 返回一个指针,避免传参拷贝
return new(bytes.Buffer)
},
}
func Log(w io.Writer, val string) {
// 获取一个Buffer对象
b := bufPool.Get().(*bytes.Buffer)
// 重置Buffer
b.Reset()
// 做一些操作
b.WriteString(val)
// 把Buffer放回池子里
bufPool.Put(b)
}
func main() {
Log(os.Stdout, "hello world!")
}
这玩意儿用的地方还很多,比如上面提到的Gin Context,一次http请求一个Context,如果频繁的创建和销毁太折磨GC了,所以用了sync.pool来存放Context,我们看Gin的源代码:
func New() *Engine {
engine := &Engine{
...
}
...
engine.pool.New = func() interface{} {
return engine.allocateContext()
}
return engine
}
除此之外,我们最常用的fmt也有在用,没想到吧。
fmt总是需要很多byte[]对象,索性就建了一个byte[]的对象池子:
// printer状态的结构体
type pp struct {
buf buffer
...
}
// pp对象池
var ppFree = sync.Pool{
New: func() interface{} { return new(pp) },
}
// 需要创建一个pp,就从池子里取
func newPrinter() *pp {
p := ppFree.Get().(*pp)
p.panicking = false
p.erroring = false
p.wrapErrs = false
p.fmt.init(&p.buf)
return p
}
来看源码
基础结构
type Pool struct {
// 防止当前对象被copy,比较tricky,一会详说
noCopy noCopy
// 数组指针,指向内存中数组的开始位置
local unsafe.Pointer
// 数组大小
localSize uintptr
// 上一轮GC的local数组,不是很重要,可以先略过
victim unsafe.Pointer
// 上一轮GC的local数组大小
victimSize uintptr
// 自定义函数,当池子里没有可用对象的时候会调用,默认为nil
New func() interface{}
}
type poolLocalInternal struct {
// 私有缓冲区,P(调度器抽象)内部私有
private interface{}
// 共享缓冲区,P之间共享
shared poolChain
}
type poolLocal struct {
// 每个P对应的pool
poolLocalInternal
// 防止伪共享
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
来一张全景图,会对全局更加清晰:
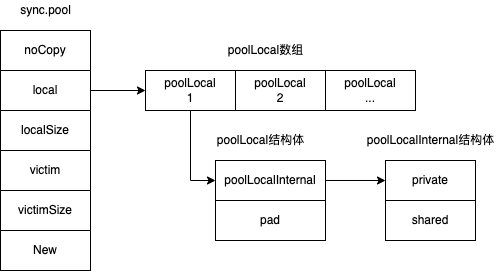
面对这基础结构,你一定会有很多疑惑,比如
- noCopy的作用
- poolLocal中pad的作用
- pool里头为什么要用一个数组
- 如何确定从哪个poolLocal取数据
带着疑惑,继续往下看
gin
pool对象一共有6个方法
New: func() interface{}
Put(x interface{})
Get() interface{}
getSlow(pid int) interface{}
pin() (*poolLocal, int)
pinSlow() (*poolLocal, int)
其中大些字母开头的前三个是对外暴露的,也就是我们创建一个pool时需要传入的New方法,存取对象要用到的Get/Put。
New我们已经了解了,一个自定义的函数,在对象池没有可用对象时被调用,创建一个新的对象返回。
在了解Get/Put之前,我们需要先看看一个关键的基础函数pin,它用于确定当前P绑定的localPool对象。这里的P是MPG中的P,也就是调度上下文,要深入理解sync.pool,需要对MPG有一些些了解。
MPG的关系图:

- M(Machine),OS线程的实体
- P(Processor),处理器的抽象,每个P持有一个G的本地队列,如果没有P,所有的G只能放在一个全局的队列中,当M执行完一个G后,必须将队列锁住从而取一个G来执行。所以P是golang实现高度并发的核心角色。
- G(Goroutine),这个不用介绍了吧
关于MPG,前往了解更多>>
跑的有点远了,我们回头继续看gin函数,作用是确定当前P对应的localPool,它的源码:
func (p *Pool) pin() (*poolLocal, int) {
// 返回当前 P.id && 设置禁止抢占(避免GC)
pid := runtime_procPin()
// 根据localSize来获取当前指针偏移的位置
s := runtime_LoadAcquintptr(&p.localSize)
l := p.local
// 有可能在运行中动态调整P,所以这里进行需要判断是否越界
if uintptr(pid) < s {
return indexLocal(l, pid), pid
}
// 越界时,会涉及全局加锁,重新分配poolLocal,添加到全局列表
return p.pinSlow()
}
代码里的注释可能还是有一些疑惑,下面来对逐行的细节解释一下
runtime_procPin()函数是运行时实现,咱也看不了它怎么实现的了//摊手//,先按下不表吧
runtime_LoadAcquintptr获取指针偏移位置,偏移到哪儿?localPool数组最后一个元素的位置。
后面的indexLocal(l, pid)就根据数组的首地址l以及偏移pid来获取对应的localPool,pid对应的是MPG中的P,上面介绍过,P是调度器的抽象,它下面挂了一串G,这些G都由它来进行调度。而每个P都有自己的localPool,以pid作为数组偏移,就可以从local(localPool数组)中定位到localPool了。这就回答了问题:如何确定要获取的数据在哪个poolLocal里头?
如果还不清楚,咱简化成两步
1、从系统获取当前pid
2、以pid为偏移,定位local中P对应的localPool
至于为什么要判断是否越界呢,这里简单解释一下。大部分时间里P的数量是不会被动态调整的,而runtime.GOMAXPROCS(n int)能够在运行时动态调整P的数量。如果P数量增加,多出来的部分pid并没有分配localPool,所以访问就会越界了。
如果越界了怎么办呢,给它分配一个,这里涉及到并发的问题,下面看ginSlow()是如何解决的
ginSlow
老规矩,先上源码
func (p *Pool) pinSlow() (*poolLocal, int) {
// 通过runtime_procPin设置了禁止抢占,后面要加锁,所以这里进行释放
runtime_procUnpin()
// 加锁
allPoolsMu.Lock()
defer allPoolsMu.Unlock()
// 返回当前 P.id && 设置禁止抢占(避免GC)
pid := runtime_procPin()
// 再次检查是否符合条件,有可能中途已被其他线程调用
s := p.localSize
l := p.local
if uintptr(pid) < s {
return indexLocal(l, pid), pid
}
// 如果数组为空,则新建Pool,将其添加到 allPools,GC以此获取所有 Pool 实例
if p.local == nil {
allPools = append(allPools, p)
}
// 根据 P 数量创建 slice
size := runtime.GOMAXPROCS(0)
local := make([]poolLocal, size)
// 将底层数组起始指针保存到 Pool.local,并设置 P.localSize
// 如果P数量在GC时发生了改变,重新分配local空间,旧的丢弃,等待GC回收
atomic.StorePointer(&p.local, unsafe.Pointer(&local[0]))
runtime_StoreReluintptr(&p.localSize, uintptr(size))
// 最后,返回pid偏移对应的poolLocal
return &local[pid], pid
}
runtime_procPin和runtime_procUnpin必须成对出现,allPoolsMu是一个全局变量,pool实现里一共有三个全局变量,它们是
var (
// 锁对象
allPoolsMu Mutex
// 所有的pool对象,pool新建后会放入allPools
// 为了避免并发竞争,只能在三种情况下访问:1)allPoolsMu加锁 2)调用了runtime_procPin 3)GC STW
allPools []*Pool
// 旧pools,上一轮GC前的allPools,详情看下文poolCleanup()的实现(善用ctrl+F)
oldPools []*Pool
)
这里为什么需要加锁呢?
因为P调整后,同时有多个G调用gin()时,都发现pid越界了,同时调用ginSlow()来重新分配localPool,就造成了对local数组的并发访问,需要加锁来保证数据安全。
在获取到锁后,再double-check一下是否越界,如果在越界判断和获取锁之间,其他G已经重新分配了localPool,就不需要重复操作,直接返回。
接着判断p.local是否为空,如果为空,说明这将是一个新的pool,我们需要把它加入allPools里头。至于为什么要加进去呢,当然是为了GC,GC时可以通过allPools获取所有pool实例,进行垃圾清理。
ginSlow()的目的是应对越界问题,为多出来的P创建poolLocal,创建多少个poolLocal呢?有多少个P就创建多少个poolLocal。
通过runtime.GOMAXPROCS(0)获取系统当前的P数量,runtime.GOMAXPROCS不是设置P数量的吗,这里为什么设置成0,有意思了。runtime.GOMAXPROCS设置P数量,并返回之前的值;但如果传参为0,它不会改变当前的设置。
put
我们来回顾一下poolLocal的结构
type poolLocal struct {
poolLocalInternal
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
type poolLocalInternal struct {
private interface{}
shared poolChain
}
poolLocalInternal是实际的数据承载对象,它包含private和shared两个属性,private和New出来的对象是一个,在put时,优先放private,后面再放shared。shared是一个poolChain对象,它的结构如下
type poolChain struct {
head *poolChainElt
tail *poolChainElt
}
只有head和tail,poolChainElt可以简单视为包含poolLocal的节点,这样就很明晰了,poolChain是一个双向链表,没想到学的算法只是还能在这里用上吧。
put的代码相对比较简单,去掉一些无关紧要(race检测,只在debug环境生效)的代码,如下
func (p *Pool) Put(x interface{}) {
if x == nil {
return
}
// 获取存放对象的poolLocal
l, _ := p.pin()
// 优先放private
if l.private == nil {
l.private = x
x = nil
}
// private放失败了,再放shared
if x != nil {
l.shared.pushHead(x)
}
// 取消P的禁止抢占
runtime_procUnpin()
}
有意思的是,放shared时,put函数放在了head,那么问题来了,tail在什么情况下被访问到呢?带着问题,我们来看get的实现
get
和set相对应,优先从private取,再加锁从shared空间拿
shared也没有,就从其他的poolLocal的shared空间拿,还没有就New一个出来
func (p *Pool) Get() interface{} {
// 获取poolLocal
l, pid := p.pin()
// 优先从private拿
x := l.private
l.private = nil
if x == nil {
// 从头节点拿
x, _ = l.shared.popHead()
if x == nil {
// 从其他poolLocal空间拿
x = p.getSlow(pid)
}
}
runtime_procUnpin()
// 都没有,就New一个出来返回
if x == nil && p.New != nil {
x = p.New()
}
return x
}
getSlow
getSlow用于从其他poolLocal窃取对象
func (p *Pool) getSlow(pid int) interface{} {
// 获取poolLocal数组的大小
size := runtime_LoadAcquintptr(&p.localSize)
locals := p.local
// 尝试从其他P获取一个对象
for i := 0; i < int(size); i++ {
// 获取一个poolLocal
l := indexLocal(locals, (pid+i+1)%int(size))
// 从尾部获取对象,减少竞争(get从head获取)
// shared的类型poolChain内部实现了并发控制(乐观锁)
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// 尝试从旧pool里获取对象,流程相似,先private,后shared
size = atomic.LoadUintptr(&p.victimSize)
if uintptr(pid) >= size {
return nil
}
locals = p.victim
l := indexLocal(locals, pid)
if x := l.private; x != nil {
l.private = nil
return x
}
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// 把旧的pool标记为空,以后不再使用
atomic.StoreUintptr(&p.victimSize, 0)
// 实在没有了
return nil
}
其他关键点
pool是永久的吗,poolCleanup()的作用?
pool是会清理的,它存活的时间为两次GC的间隔
在程序启动时,会注册一个清理函数poolCleanup(),每次GC开始前,都会被调用
func init() {
runtime_registerPoolCleanup(poolCleanup)
}
poolCleanup源码
// 在STW期间,GC前被调用
// 因为STW,所以不会有并发竞争
func poolCleanup() {
// 上一轮的pools,直接全部丢弃
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// 把当前pools的private和shared移到victim cache中
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
// oldPools内容会被GC回收,oldPools指针指向allPools
oldPools, allPools = allPools, nil
}
可以看出poolCleanup源码非常简单,就是做一些数据交换的工作,同时因为STW,不涉及并发。
另外也可以看书,pools并不是持久的,它会被定期回收,时间就是两次GC
noCopy作用
防止pool被拷贝,因为pool在golang是全局唯一的
为什么noCopy能防止pool被拷贝呢
Golang中没有原生的禁止拷贝的方式,所以结构体不希望被拷贝,所以go作者做了这么一个约定:只要包含实现 sync.Locker 这个接口的结构体noCopy,go vet 就可以帮我们进行检查是否被拷贝了。
pad的作用
防止伪共享,什么是伪共享?
简单说一下,缓存系统中是以缓存行为单位存储的,缓存行一般为64字节,加载其中一个字节,就需要把另外63个加载出来。
加锁的话,也是在这一行64个字节上加锁。所以如果一个变量X不足64字节,它和另一个变量Y共享了这一缓存行,当对X加锁后,Y也不能访问了,所以称为伪共享。
通过pad补齐缓存行,就可以防止伪共享了。
为什么每个P一个poolLocal对象
为什么不能简单的使用一个pool,大家都在里面存取呢
目的是减少加锁竞争,goroutine同一时刻并发量是有限的,通常为P的个数,通过为每个P绑定自己的poolLocal,首先在自己的poolLocal里取值,取不到时,再去其他P窃取一个。

















 2143
2143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









