







从入门到真正能用在项目中,90% 人看完这篇就够了
目录
大家好,我是正在狂奔 2025 的打工人,今天是连续打卡的第 3 天!
前两天搞定了 Python 基础和 Pandas,今天轮到科学计算的灵魂——NumPy。
很多人说“NumPy 很简单”,但真正用起来才发现:不搞懂这几个核心点,后面 Pandas、PyTorch、机器学习全都会踩坑!
所以我花了一整晚,把官方快速入门教程(https://numpy.com.cn/doc/stable/user/quickstart.html)嚼了三遍,提炼出了这篇“看完就能上手的极精华笔记”。
建议收藏 + 一键三连,今晚跑完所有代码,你也会说:“原来 NumPy 这么香!”
一、为什么非学 NumPy 不可?
- Pandas 底层就是 NumPy
- PyTorch/TensorFlow 的 tensor 几乎和 ndarray 一模一样
- 数据预处理、图像处理、金融量化……全部离不开它
- 比 Python 原生 list 快 10~100 倍(矢量化)
一句话:不会 Num Py = 科学计算界的文盲
二、核心知识点(90% 场景只用这几招)
1. 创建数组的 8 种姿势(前 5 种必背)
import numpy as np
# 1. 最常用
a = np.array([1, 2, 3, 4, 5])
# 2. 二维、三维
b = np.array([[1,2,3], [4,5,6]])
# 3. 全 0 / 全 1
c = np.zeros((3, 4))
d = np.ones((2, 3, 4), dtype=np.int16)
# 4. 填充任意值
e = np.full((3, 3), 666)
# 5. 等差数列(神器!)
f = np.arange(0, 20, 2) # [0, 2, 4, ..., 18]
g = np.linspace(0, 1, 5) # [0. 0.25 0.5 0.75 1. ] 包含端点
# 6. 随机数(面试、项目天天用)
h = np.random.random((3, 3)) # [0, 1) 均匀分布
i = np.random.randn(3, 3) # 标准正态分布(最常用!)
j = np.random.randint(0, 10, (3, 3)) # 随机整数
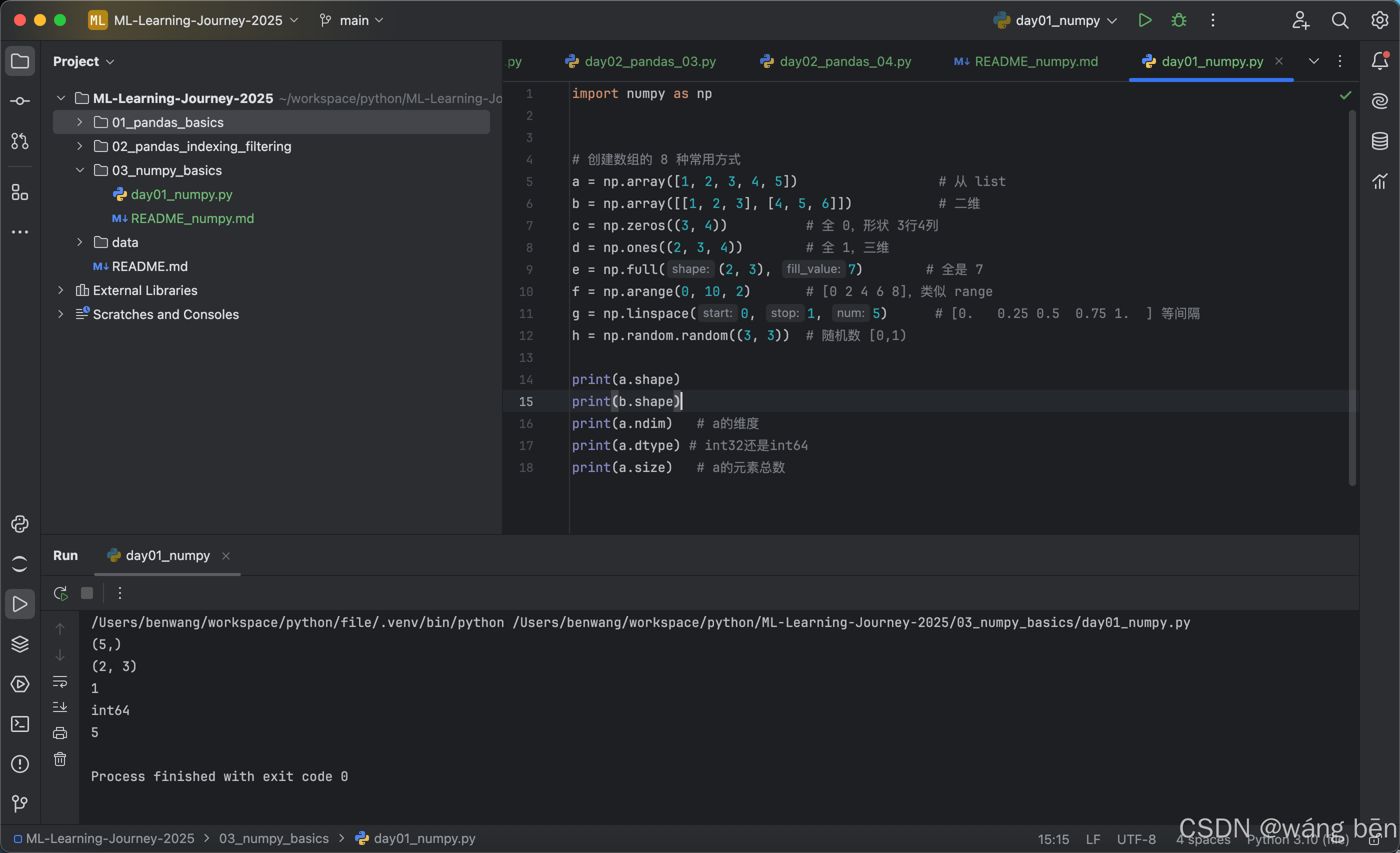
2. 重要属性(debug 必看)
arr = np.random.randn(4, 5)
arr.shape # (4, 5)
arr.ndim # 2
arr.dtype # float64
arr.size # 20
arr.itemsize # 每个元素占几个字节
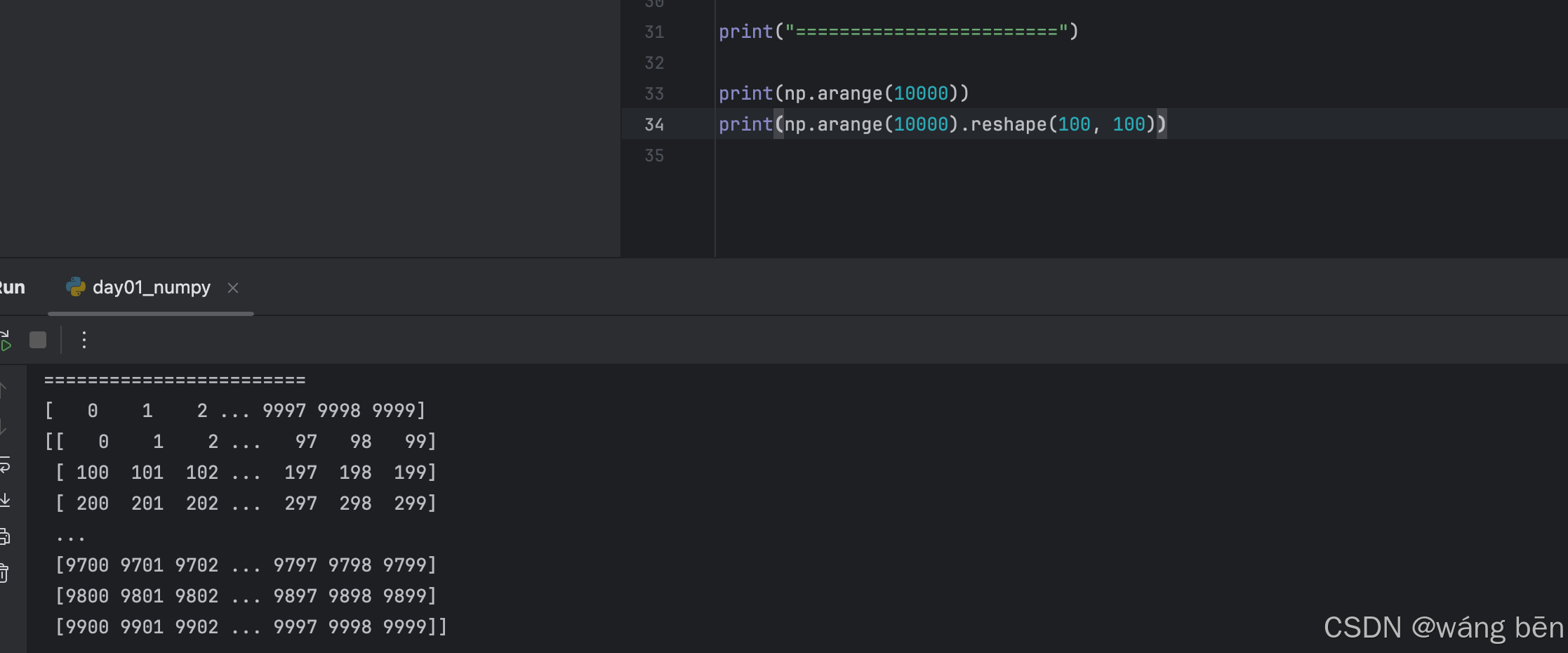
如果数组太大无法完全打印,NumPy 会自动跳过数组的中心部分,只打印边缘部分。
print(np.arange(10000))
print(np.arange(10000).reshape(100, 100))
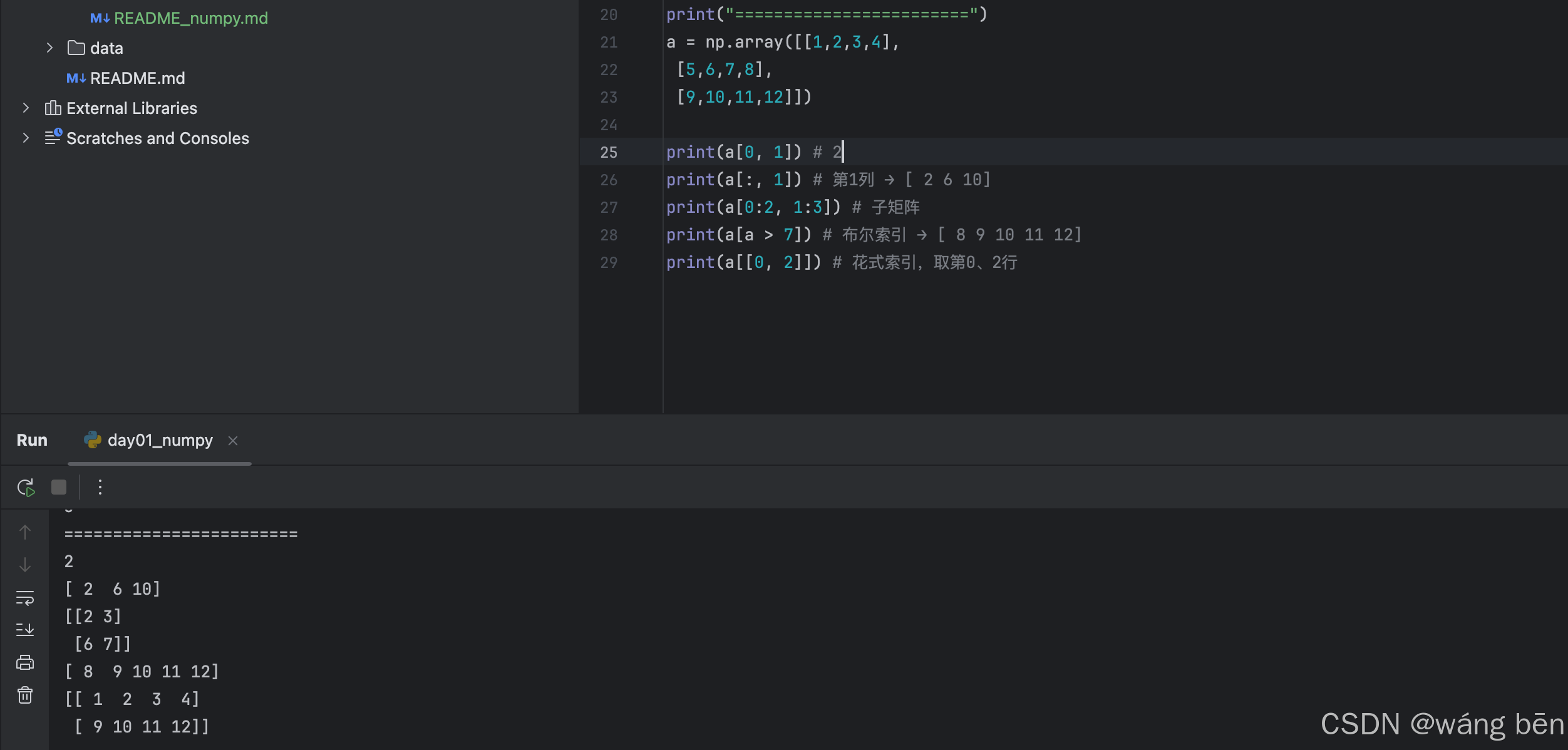
3. 索引 & 切片(比 list 还好用)
a = np.array([[1,2,3,4],
[5,6,7,8],
[9,10,11,12]])
a[0, 1] # 2
a[:, 1] # 第1列 → [ 2 6 10]
a[0:2, 1:3] # 子矩阵
a[a > 7] # 布尔索引 → [ 8 9 10 11 12]
a[[0, 2]] # 花式索引,取第0、2行
打印:
好嘞,直接给你最新一段,复制到你博客里,替换原来的“4. 形状操作”以及它后面的部分,或者直接插到形状操作之后,作为新的第 4 点(原第 4 点往后顺延即可)。
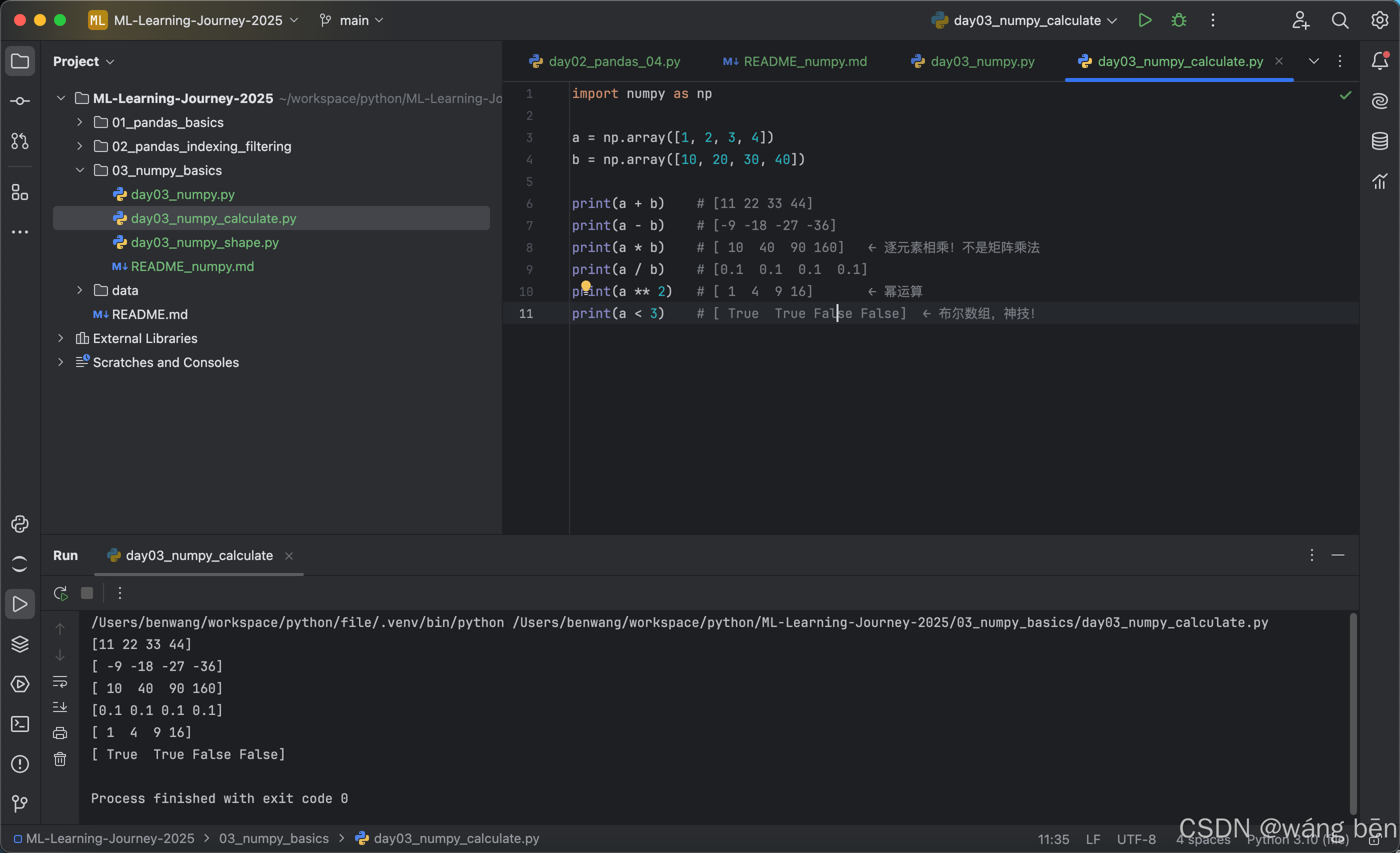
4. 数组的加减乘除(极重要!矢量化的灵魂)
NumPy 数组之间直接写 + - * /,逐元素运算,不需要任何循环,比 for 快几十到上百倍!
a = np.array([1, 2, 3, 4])
b = np.array([10, 20, 30, 40])
print(a + b) # [11 22 33 44]
print(a - b) # [-9 -18 -27 -36]
print(a * b) # [ 10 40 90 160] ← 逐元素相乘!不是矩阵乘法
print(a / b) # [0.1 0.1 0.1 0.1]
print(a ** 2) # [ 1 4 9 16] ← 幂运算
print(a < 3) # [ True True False False] ← 布尔数组,神技!
和标量运算(广播机制自动生效):
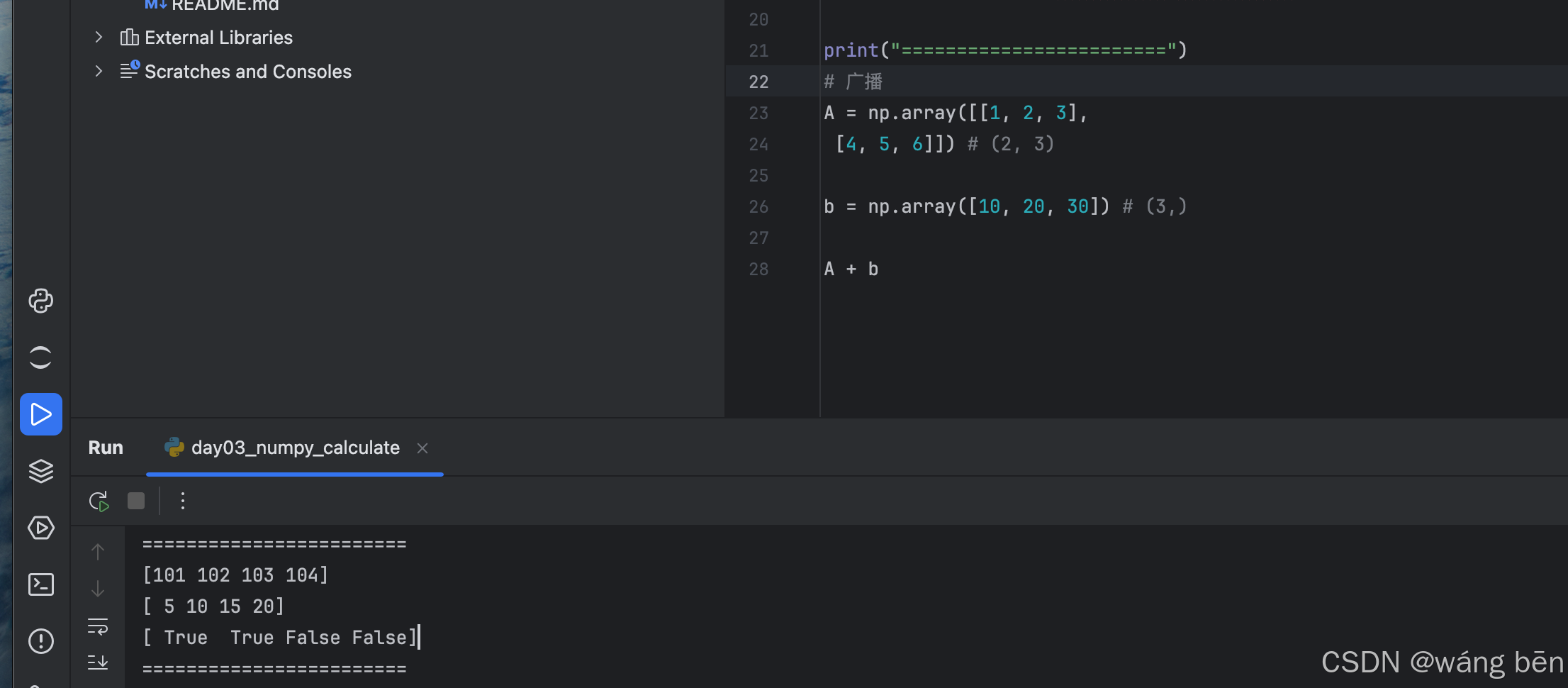
print(a + 100) # [101 102 103 104]
print(a * 5) # [ 5 10 15 20]
print(a <= 2) # [ True True False False]
真正的矩阵乘法(点积)用下面两种写法(推荐第二种):
A = np.array([[1, 2], [3, 4]]) # (2, 2)
B = np.array([[5, 6], [7, 8]]) # (2, 2)
np.dot(A, B) # 老写法
A @ B # Python 3.5+ 新写法(强烈推荐!)
# 结果:
# [[19 22]
# [43 50]]
实际项目中 99% 都会用到这几行:
# 特征缩放(非常常见)
X = np.random.randn(1000, 20)
X = X * 0.1 + 5 # 先乘后加,相当于缩放+平移
# ReLU 激活函数(深度学习里天天写)
X_relu = np.maximum(0, X) # 小于0的全部变成0
# L2 范数归一化(让每一行向量长度为1)
X_norm = X / np.sqrt(np.sum(X**2, axis=1, keepdims=True))
记住一句话:看到 for 循环对数组逐元素加减乘除,马上改成 NumPy 直接运算,性能直接起飞!
看完真的能“秒杀”90% 的数据处理任务!
5. 形状操作(每天都要用)
a = np.arange(12)
b = a.reshape(3, 4) # 重塑
c = b.ravel() # 展平
d = b.T # 转置
e = np.newaxis # 增加维度神器
# 例子:(100,) → (100, 1)
x = x[:, np.newaxis]
6. 广播(Broadcasting)—— NumPy 最神奇的特性
A = np.array([[1, 2, 3],
[4, 5, 6]]) # (2, 3)
b = np.array([10, 20, 30]) # (3,)
A + b
# 自动广播成:
# [[11, 22, 33],
# [14, 25, 36]]
实际项目中最常见的用法(数据标准化):
# 让每一列均值为0,方差为1(机器学习必备预处理)
X = np.random.randn(1000, 10)
X_centered = X - X.mean(axis=0) # 去均值
X_scaled = X_centered / X.std(axis=0) # 除以标准差
7. 聚合操作(记住 axis 就赢了)
X.sum(axis=0) # 按列求和
X.mean(axis=1) # 按行求均值
X.max(), X.argmax()
8. 线性代数(小项目直接够用)
A = np.array([[1, 2], [3, 4]])
b = np.array([5, 6])
x = np.linalg.solve(A, b) # 解方程 Ax = b
np.linalg.inv(A) # 求逆
np.dot(A, b) 或 A @ b # 矩阵乘法
三 、今天写的 3 个小练习(直接复制跑)
# 练习1:生成 10000 个正态分布数据,计算均值和标准差
data = np.random.randn(10000)
print(f"均值: {data.mean():.6f}, 标准差: {data.std():.6f}")
# 练习2:实现 min-max 归一化函数
def min_max_scale(x):
return (x - x.min()) / (x.max() - x.min())
# 练习3:不用循环,把矩阵每行加上不同的偏置
matrix = np.arange(20).reshape(4, 5)
bias = np.array([10, 20, 30, 40]) # (4,)
result = matrix + bias[:, np.newaxis] # 广播神技!
print(result)
四、Day3 总结
- NumPy 核心 = ndarray + 矢量化 + 广播
- 背会前 10 个函数,你就超过了 80% 的初学者
- 以后看到 for 循环操作列表 → 立刻改 NumPy,性能起飞
明天预告:Matplotlib 可视化 + 手把手画出让人惊艳的图表!
坚持打卡第 3 天,感觉自己已经起飞了
你们也一起冲,2025 我们都要卷成 AI 大佬!
点赞 + 收藏 + 在看,三连才是真的爱
我们明天见!
加油,兄弟!明天继续卷!!



















&spm=1001.2101.3001.5002&articleId=155188142&d=1&t=3&u=63eeb1be995a47dabdbd3ed9285c8792)
 674
674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











